 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAG-Based Multi-Agent LLM System for Natural Hazard Resilience and Adaptation
Apr 24, 2025Large language models (LLMs) are a transformational capability at the frontier of artificial intelligence and machine learning that can support decision-makers in addressing pressing societal challenges such as extreme natural hazard events. As generalized models, LLMs often struggle to provide context-specific information, particularly in areas requiring specialized knowledge. In this work we propose a retrieval-augmented generation (RAG)-based multi-agent LLM system to support analysis and decision-making in the context of natural hazards and extreme weather events. As a proof of concept, we present WildfireGPT, a specialized system focused on wildfire hazards. The architecture employs a user-centered, multi-agent design to deliver tailored risk insights across diverse stakeholder groups. By integrating natural hazard and extreme weather projection data, observational datasets, and scientific literature through an RAG framework, the system ensures both the accuracy and contextual relevance of the information it provides. Evaluation across ten expert-led case studies demonstrates that WildfireGPT significantly outperforms existing LLM-based solutions for decision support.
WildfireGPT: Tailored Large Language Model for Wildfire Analysis
Feb 12, 2024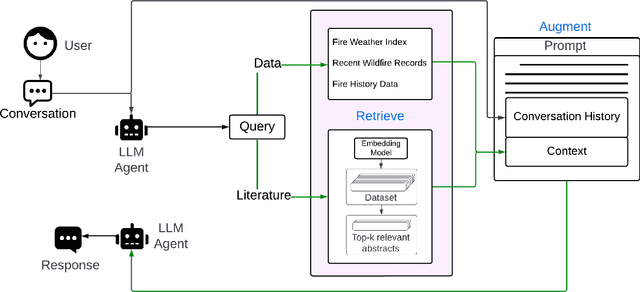


The recent advancement of large language models (LLMs) represents a transformational capability at the frontier of artificial intelligence (AI) and machine learning (ML). However, LLMs are generalized models, trained on extensive text corpus, and often struggle to provide context-specific information, particularly in areas requiring specialized knowledge such as wildfire details within the broader context of climate change. For decision-makers and policymakers focused on wildfire resilience and adaptation, it is crucial to obtain responses that are not only precise but also domain-specific, rather than generic. To that end, we developed WildfireGPT, a prototype LLM agent designed to transform user queries into actionable insights on wildfire risks. We enrich WildfireGPT by providing additional context such as climate projections and scientific literature to ensure its information is current, relevant, and scientifically accurate. This enables WildfireGPT to be an effective tool for delivering detailed, user-specific insights on wildfire risks to support a diverse set of end users, including researchers, engineers, urban planners, emergency managers, and infrastructure operators.
Towards Continually Learning Application Performance Models
Oct 25, 2023Machine learning-based performance models are increasingly being used to build critical job scheduling and application optimization decisions. Traditionally, these models assume that data distribution does not change as more samples are collected over time. However, owing to the complexity and heterogeneity of production HPC systems, they are susceptible to hardware degradation, replacement, and/or software patches, which can lead to drift in the data distribution that can adversely affect the performance models. To this end, we develop continually learning performance models that account for the distribution drift, alleviate catastrophic forgetting, and improve generalizability. Our best model was able to retain accuracy, regardless of having to learn the new distribution of data inflicted by system changes, while demonstrating a 2x improvement in the prediction accuracy of the whole data sequence in comparison to the naive approach.
A Visual Analytics Framework for Reviewing Streaming Performance Data
Jan 26, 2020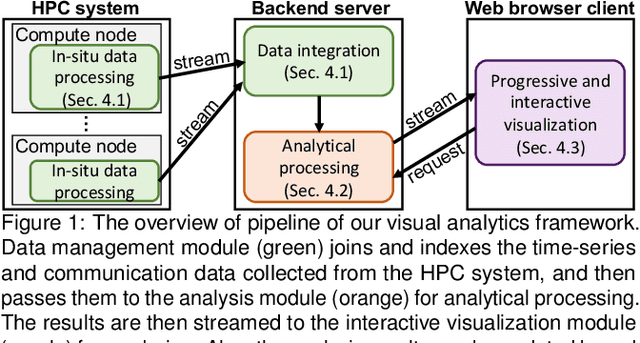

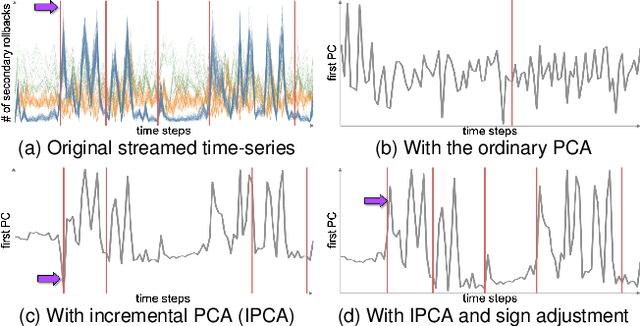
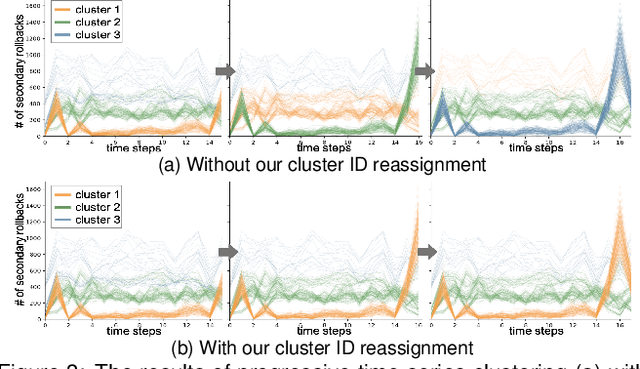
Understanding and tuning the performance of extreme-scale parallel computing systems demands a streaming approach due to the computational cost of applying offline algorithms to vast amounts of performance log data. Analyzing large streaming data is challenging because the rate of receiving data and limited time to comprehend data make it difficult for the analysts to sufficiently examine the data without missing important changes or patterns. To support streaming data analysis, we introduce a visual analytic framework comprising of three modules: data management, analysis, and interactive visualization. The data management module collects various computing and communication performance metrics from the monitored system using streaming data processing techniques and feeds the data to the other two modules. The analysis module automatically identifies important changes and patterns at the required latency. In particular, we introduce a set of online and progressive analysis methods for not only controlling the computational costs but also helping analysts better follow the critical aspects of the analysis results. Finally, the interactive visualization module provides the analysts with a coherent view of the changes and patterns in the continuously captured performance data. Through a multi-faceted case study on performance analysis of parallel discrete-event simulation, we demonstrate the effectiveness of our framework for identifying bottlenecks and locating outliers.