 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlchemist: Towards the Design of Efficient Online Continual Learning System
Mar 03, 2025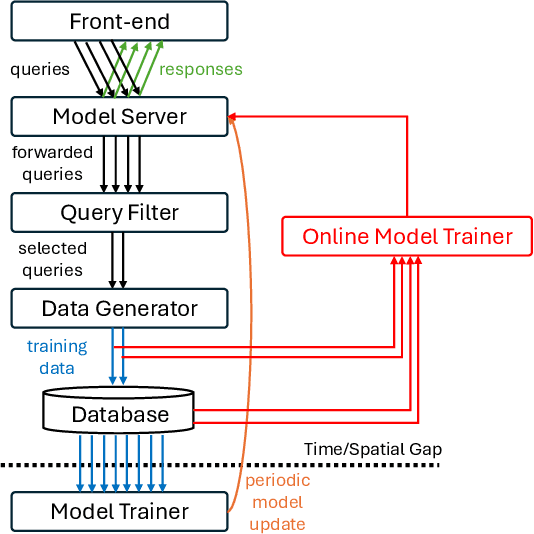
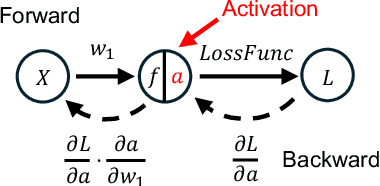
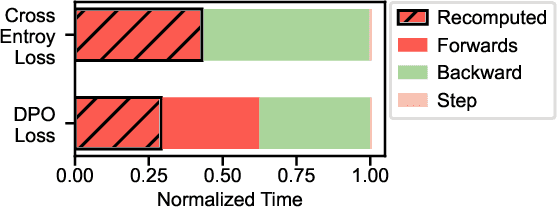
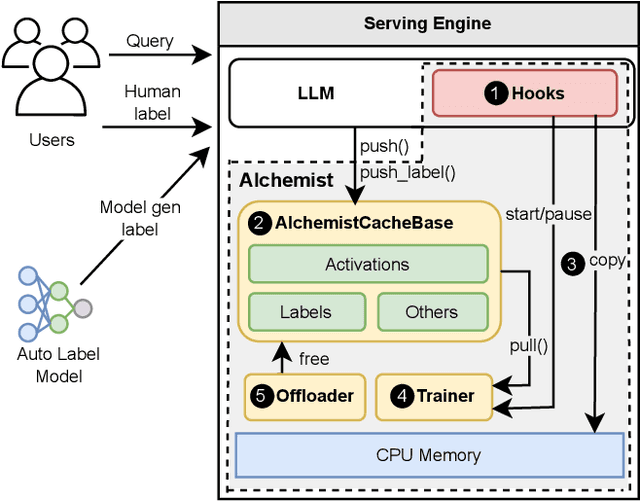
Continual learning has emerged as a promising solution to refine models incrementally by leveraging user feedback, thereby enhancing model performance in applications like code completion, personal assistants, and chat interfaces. In particular, online continual learning - iteratively training the model with small batches of user feedback - has demonstrated notable performance improvements. However, the existing practice of segregating training and serving processes forces the online trainer to recompute the intermediate results already done during serving. Such redundant computations can account for 30%-42% of total training time. In this paper, we propose Alchemist, to the best of our knowledge, the first online continual learning system that efficiently reuses intermediate results computed during serving to reduce redundant computation with minimal impact on the serving latency or capacity. Alchemist introduces two key techniques: (1) minimal activations recording and saving during serving, where activations are recorded and saved only during the prefill phase to minimize overhead; and (2) offloading of serving activations, which dynamically manages GPU memory by freeing activations in the forward order, while reloading them in the backward order during the backward pass. Evaluations with the ShareGPT dataset show that compared with a separate training cluster, Alchemist significantly increases training throughput by up to 1.72x, reduces up to 47% memory usage during training, and supports up to 2x more training tokens - all while maintaining negligible impact on serving latency.
Towards Continually Learning Application Performance Models
Oct 25, 2023Machine learning-based performance models are increasingly being used to build critical job scheduling and application optimization decisions. Traditionally, these models assume that data distribution does not change as more samples are collected over time. However, owing to the complexity and heterogeneity of production HPC systems, they are susceptible to hardware degradation, replacement, and/or software patches, which can lead to drift in the data distribution that can adversely affect the performance models. To this end, we develop continually learning performance models that account for the distribution drift, alleviate catastrophic forgetting, and improve generalizability. Our best model was able to retain accuracy, regardless of having to learn the new distribution of data inflicted by system changes, while demonstrating a 2x improvement in the prediction accuracy of the whole data sequence in comparison to the naive approach.