 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA RAG-Based Multi-Agent LLM System for Natural Hazard Resilience and Adaptation
Apr 24, 2025Large language models (LLMs) are a transformational capability at the frontier of artificial intelligence and machine learning that can support decision-makers in addressing pressing societal challenges such as extreme natural hazard events. As generalized models, LLMs often struggle to provide context-specific information, particularly in areas requiring specialized knowledge. In this work we propose a retrieval-augmented generation (RAG)-based multi-agent LLM system to support analysis and decision-making in the context of natural hazards and extreme weather events. As a proof of concept, we present WildfireGPT, a specialized system focused on wildfire hazards. The architecture employs a user-centered, multi-agent design to deliver tailored risk insights across diverse stakeholder groups. By integrating natural hazard and extreme weather projection data, observational datasets, and scientific literature through an RAG framework, the system ensures both the accuracy and contextual relevance of the information it provides. Evaluation across ten expert-led case studies demonstrates that WildfireGPT significantly outperforms existing LLM-based solutions for decision support.
WildfireGPT: Tailored Large Language Model for Wildfire Analysis
Feb 12, 2024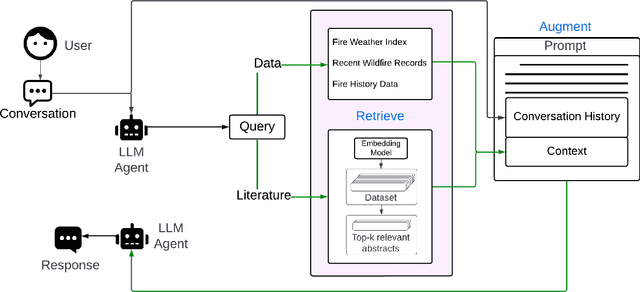


The recent advancement of large language models (LLMs) represents a transformational capability at the frontier of artificial intelligence (AI) and machine learning (ML). However, LLMs are generalized models, trained on extensive text corpus, and often struggle to provide context-specific information, particularly in areas requiring specialized knowledge such as wildfire details within the broader context of climate change. For decision-makers and policymakers focused on wildfire resilience and adaptation, it is crucial to obtain responses that are not only precise but also domain-specific, rather than generic. To that end, we developed WildfireGPT, a prototype LLM agent designed to transform user queries into actionable insights on wildfire risks. We enrich WildfireGPT by providing additional context such as climate projections and scientific literature to ensure its information is current, relevant, and scientifically accurate. This enables WildfireGPT to be an effective tool for delivering detailed, user-specific insights on wildfire risks to support a diverse set of end users, including researchers, engineers, urban planners, emergency managers, and infrastructure operators.
Analyzing Regional Impacts of Climate Change using Natural Language Processing Techniques
Jan 11, 2024Understanding the multifaceted effects of climate change across diverse geographic locations is crucial for timely adaptation and the development of effective mitigation strategies. As the volume of scientific literature on this topic continues to grow exponentially, manually reviewing these documents has become an immensely challenging task. Utilizing Natural Language Processing (NLP) techniques to analyze this wealth of information presents an efficient and scalable solution. By gathering extensive amounts of peer-reviewed articles and studies, we can extract and process critical information about the effects of climate change in specific regions. We employ BERT (Bidirectional Encoder Representations from Transformers) for Named Entity Recognition (NER), which enables us to efficiently identify specific geographies within the climate literature. This, in turn, facilitates location-specific analyses. We conduct region-specific climate trend analyses to pinpoint the predominant themes or concerns related to climate change within a particular area, trace the temporal progression of these identified issues, and evaluate their frequency, severity, and potential development over time. These in-depth examinations of location-specific climate data enable the creation of more customized policy-making, adaptation, and mitigation strategies, addressing each region's unique challenges and providing more effective solutions rooted in data-driven insights. This approach, founded on a thorough exploration of scientific texts, offers actionable insights to a wide range of stakeholders, from policymakers to engineers to environmentalists. By proactively understanding these impacts, societies are better positioned to prepare, allocate resources wisely, and design tailored strategies to cope with future climate conditions, ensuring a more resilient future for all.
Analyzing the impact of climate change on critical infrastructure from the scientific literature: A weakly supervised NLP approach
Feb 06, 2023
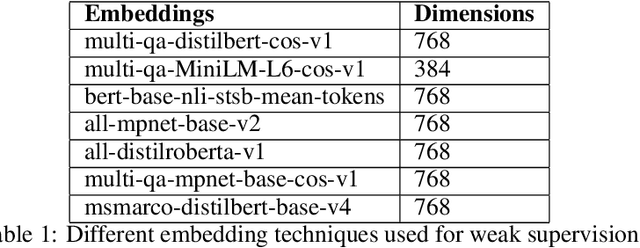


Natural language processing (NLP) is a promising approach for analyzing large volumes of climate-change and infrastructure-related scientific literature. However, best-in-practice NLP techniques require large collections of relevant documents (corpus). Furthermore, NLP techniques using machine learning and deep learning techniques require labels grouping the articles based on user-defined criteria for a significant subset of a corpus in order to train the supervised model. Even labeling a few hundred documents with human subject-matter experts is a time-consuming process. To expedite this process, we developed a weak supervision-based NLP approach that leverages semantic similarity between categories and documents to (i) establish a topic-specific corpus by subsetting a large-scale open-access corpus and (ii) generate category labels for the topic-specific corpus. In comparison with a months-long process of subject-matter expert labeling, we assign category labels to the whole corpus using weak supervision and supervised learning in about 13 hours. The labeled climate and NCF corpus enable targeted, efficient identification of documents discussing a topic (or combination of topics) of interest and identification of various effects of climate change on critical infrastructure, improving the usability of scientific literature and ultimately supporting enhanced policy and decision making. To demonstrate this capability, we conduct topic modeling on pairs of climate hazards and NCFs to discover trending topics at the intersection of these categories. This method is useful for analysts and decision-makers to quickly grasp the relevant topics and most important documents linked to the topic.