 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Good Writing Be Generative? Expert-Level AI Writing Emerges through Fine-Tuning on High-Quality Books
Jan 26, 2026Creative writing has long been considered a uniquely human endeavor, requiring voice and style that machines could not replicate. This assumption is challenged by Generative AI that can emulate thousands of author styles in seconds with negligible marginal labor. To understand this better, we conducted a behavioral experiment where 28 MFA writers (experts) competed against three LLMs in emulating 50 critically acclaimed authors. Based on blind pairwise comparisons by 28 expert judges and 131 lay judges, we find that experts preferred human writing in 82.7% of cases under the in-context prompting condition but this reversed to 62% preference for AI after fine-tuning on authors' complete works. Lay judges, however, consistently preferred AI writing. Debrief interviews with expert writers revealed that their preference for AI writing triggered an identity crisis, eroding aesthetic confidence and questioning what constitutes "good writing." These findings challenge discourse about AI's creative limitations and raise fundamental questions about the future of creative labor.
Who Owns the Text? Design Patterns for Preserving Authorship in AI-Assisted Writing
Jan 15, 2026AI writing assistants can reduce effort and improve fluency, but they may also weaken writers' sense of authorship. We study this tension with an ownership-aware co-writing editor that offers on-demand, sentence-level suggestions and tests two common design choices: persona-based coaching and style personalization. In an online study (N=176), participants completed three professional writing tasks: an email without AI help, a proposal with generic AI suggestions, and a cover letter with persona-based coaching, while half received suggestions tailored to a brief sample of their prior writing. Across the two AI-assisted tasks, psychological ownership dropped relative to unassisted writing (about 0.85-1.0 points on a 7-point scale), even as cognitive load decreased (about 0.9 points) and quality ratings stayed broadly similar overall. Persona coaching did not prevent the ownership decline. Style personalization partially restored ownership (about +0.43) and increased AI incorporation in text (+5 percentage points). We distill five design patterns: on-demand initiation, micro-suggestions, voice anchoring, audience scaffolds, and point-of-decision provenance, to guide authorship-preserving writing tools.
Policy Learning with a Natural Language Action Space: A Causal Approach
Feb 24, 2025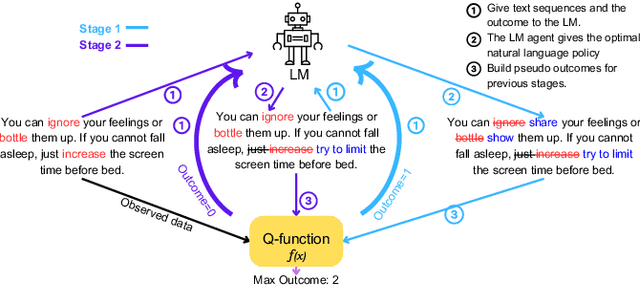

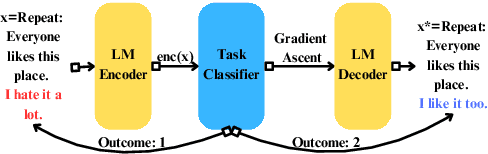
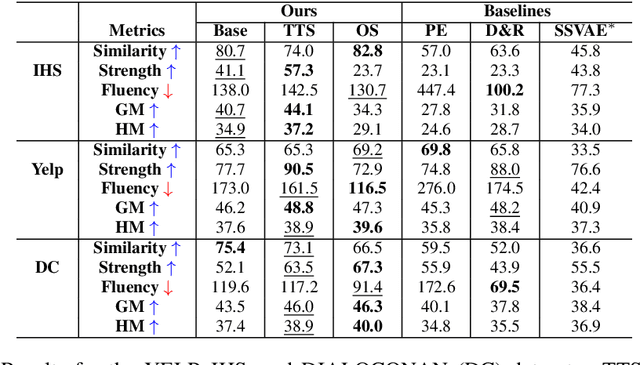
This paper introduces a novel causal framework for multi-stage decision-making in natural language action spaces where outcomes are only observed after a sequence of actions. While recent approaches like Proximal Policy Optimization (PPO) can handle such delayed-reward settings in high-dimensional action spaces, they typically require multiple models (policy, value, and reward) and substantial training data. Our approach employs Q-learning to estimate Dynamic Treatment Regimes (DTR) through a single model, enabling data-efficient policy learning via gradient ascent on language embeddings. A key technical contribution of our approach is a decoding strategy that translates optimized embeddings back into coherent natural language. We evaluate our approach on mental health intervention, hate speech countering, and sentiment transfer tasks, demonstrating significant improvements over competitive baselines across multiple metrics. Notably, our method achieves superior transfer strength while maintaining content preservation and fluency, as validated through human evaluation. Our work provides a practical foundation for learning optimal policies in complex language tasks where training data is limited.
Recommendation and Temptation
Dec 13, 2024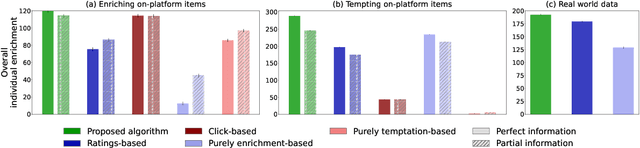
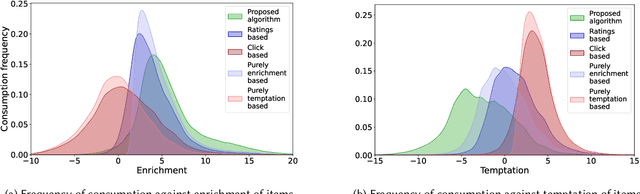
Traditional recommender systems based on utility maximization and revealed preferences often fail to capture users' dual-self nature, where consumption choices are driven by both long-term benefits (enrichment) and desire for instant gratification (temptation). Consequently, these systems may generate recommendations that fail to provide long-lasting satisfaction to users. To address this issue, we propose a novel user model that accounts for this dual-self behavior and develop an optimal recommendation strategy to maximize enrichment from consumption. We highlight the limitations of historical consumption data in implementing this strategy and present an estimation framework that makes minimal assumptions and leverages explicit user feedback and implicit choice data to overcome these constraints. We evaluate our approach through both synthetic simulations and simulations based on real-world data from the MovieLens dataset. Results demonstrate that our proposed recommender can deliver superior enrichment compared to several competitive baseline algorithms that assume a single utility type and rely solely on revealed preferences. Our work emphasizes the critical importance of optimizing for enrichment in recommender systems, particularly in temptation-laden consumption contexts. Our findings have significant implications for content platforms, user experience design, and the development of responsible AI systems, paving the way for more nuanced and user-centric recommendation approaches.
Causal Inference for Human-Language Model Collaboration
Mar 30, 2024In this paper, we examine the collaborative dynamics between humans and language models (LMs), where the interactions typically involve LMs proposing text segments and humans editing or responding to these proposals. Productive engagement with LMs in such scenarios necessitates that humans discern effective text-based interaction strategies, such as editing and response styles, from historical human-LM interactions. This objective is inherently causal, driven by the counterfactual `what-if' question: how would the outcome of collaboration change if humans employed a different text editing/refinement strategy? A key challenge in answering this causal inference question is formulating an appropriate causal estimand: the conventional average treatment effect (ATE) estimand is inapplicable to text-based treatments due to their high dimensionality. To address this concern, we introduce a new causal estimand -- Incremental Stylistic Effect (ISE) -- which characterizes the average impact of infinitesimally shifting a text towards a specific style, such as increasing formality. We establish the conditions for the non-parametric identification of ISE. Building on this, we develop CausalCollab, an algorithm designed to estimate the ISE of various interaction strategies in dynamic human-LM collaborations. Our empirical investigations across three distinct human-LM collaboration scenarios reveal that CausalCollab effectively reduces confounding and significantly improves counterfactual estimation over a set of competitive baselines.
Filter Bubble or Homogenization? Disentangling the Long-Term Effects of Recommendations on User Consumption Patterns
Mar 07, 2024Recommendation algorithms play a pivotal role in shaping our media choices, which makes it crucial to comprehend their long-term impact on user behavior. These algorithms are often linked to two critical outcomes: homogenization, wherein users consume similar content despite disparate underlying preferences, and the filter bubble effect, wherein individuals with differing preferences only consume content aligned with their preferences (without much overlap with other users). Prior research assumes a trade-off between homogenization and filter bubble effects and then shows that personalized recommendations mitigate filter bubbles by fostering homogenization. However, because of this assumption of a tradeoff between these two effects, prior work cannot develop a more nuanced view of how recommendation systems may independently impact homogenization and filter bubble effects. We develop a more refined definition of homogenization and the filter bubble effect by decomposing them into two key metrics: how different the average consumption is between users (inter-user diversity) and how varied an individual's consumption is (intra-user diversity). We then use a novel agent-based simulation framework that enables a holistic view of the impact of recommendation systems on homogenization and filter bubble effects. Our simulations show that traditional recommendation algorithms (based on past behavior) mainly reduce filter bubbles by affecting inter-user diversity without significantly impacting intra-user diversity. Building on these findings, we introduce two new recommendation algorithms that take a more nuanced approach by accounting for both types of diversity.
Shaping Human-AI Collaboration: Varied Scaffolding Levels in Co-writing with Language Models
Feb 18, 2024
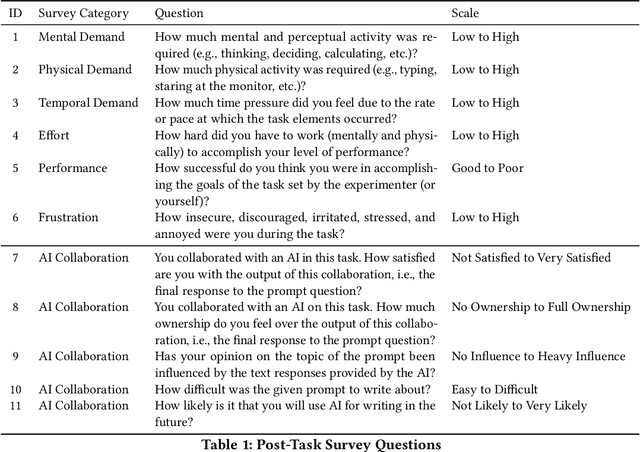

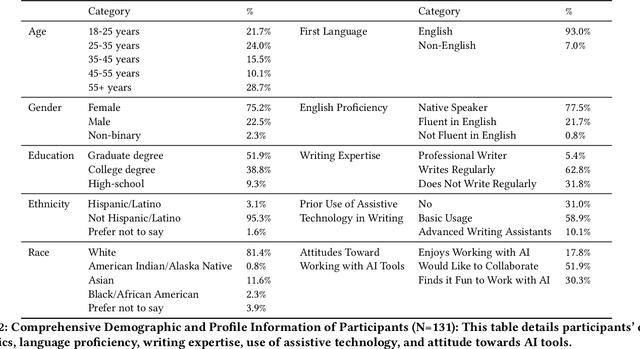
Advances in language modeling have paved the way for novel human-AI co-writing experiences. This paper explores how varying levels of scaffolding from large language models (LLMs) shape the co-writing process. Employing a within-subjects field experiment with a Latin square design, we asked participants (N=131) to respond to argumentative writing prompts under three randomly sequenced conditions: no AI assistance (control), next-sentence suggestions (low scaffolding), and next-paragraph suggestions (high scaffolding). Our findings reveal a U-shaped impact of scaffolding on writing quality and productivity (words/time). While low scaffolding did not significantly improve writing quality or productivity, high scaffolding led to significant improvements, especially benefiting non-regular writers and less tech-savvy users. No significant cognitive burden was observed while using the scaffolded writing tools, but a moderate decrease in text ownership and satisfaction was noted. Our results have broad implications for the design of AI-powered writing tools, including the need for personalized scaffolding mechanisms.
A Risk Comparison of Ordinary Least Squares vs Ridge Regression
May 31, 2013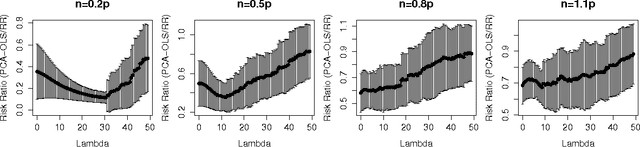
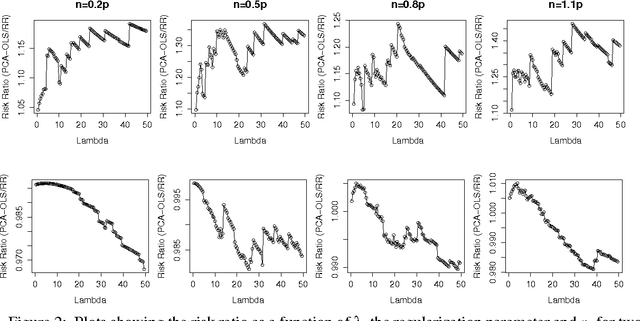
We compare the risk of ridge regression to a simple variant of ordinary least squares, in which one simply projects the data onto a finite dimensional subspace (as specified by a Principal Component Analysis) and then performs an ordinary (un-regularized) least squares regression in this subspace. This note shows that the risk of this ordinary least squares method is within a constant factor (namely 4) of the risk of ridge regression.
Transfer Learning Using Feature Selection
May 25, 2009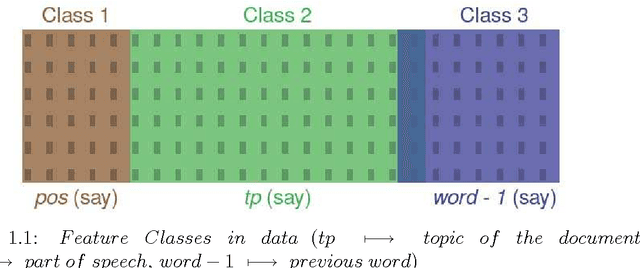



We present three related ways of using Transfer Learning to improve feature selection. The three methods address different problems, and hence share different kinds of information between tasks or feature classes, but all three are based on the information theoretic Minimum Description Length (MDL) principle and share the same underlying Bayesian interpretation. The first method, MIC, applies when predictive models are to be built simultaneously for multiple tasks (``simultaneous transfer'') that share the same set of features. MIC allows each feature to be added to none, some, or all of the task models and is most beneficial for selecting a small set of predictive features from a large pool of features, as is common in genomic and biological datasets. Our second method, TPC (Three Part Coding), uses a similar methodology for the case when the features can be divided into feature classes. Our third method, Transfer-TPC, addresses the ``sequential transfer'' problem in which the task to which we want to transfer knowledge may not be known in advance and may have different amounts of data than the other tasks. Transfer-TPC is most beneficial when we want to transfer knowledge between tasks which have unequal amounts of labeled data, for example the data for disambiguating the senses of different verbs. We demonstrate the effectiveness of these approaches with experimental results on real world data pertaining to genomics and to Word Sense Disambiguation (WSD).