 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Learning with a Natural Language Action Space: A Causal Approach
Paper and Code
Feb 24, 2025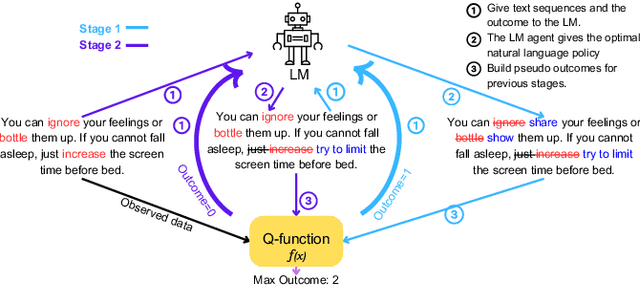

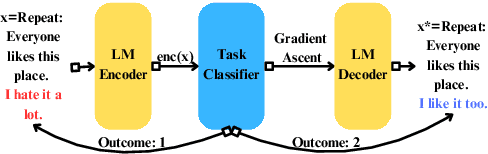
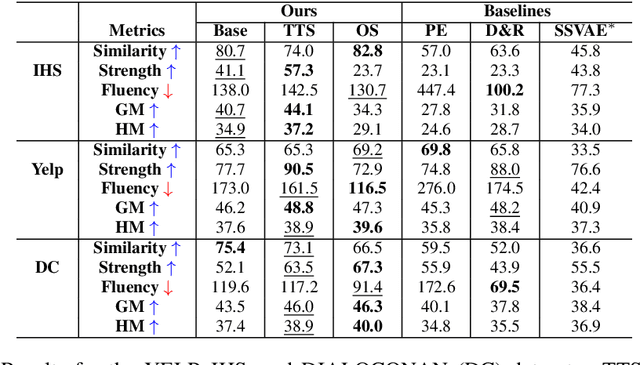
This paper introduces a novel causal framework for multi-stage decision-making in natural language action spaces where outcomes are only observed after a sequence of actions. While recent approaches like Proximal Policy Optimization (PPO) can handle such delayed-reward settings in high-dimensional action spaces, they typically require multiple models (policy, value, and reward) and substantial training data. Our approach employs Q-learning to estimate Dynamic Treatment Regimes (DTR) through a single model, enabling data-efficient policy learning via gradient ascent on language embeddings. A key technical contribution of our approach is a decoding strategy that translates optimized embeddings back into coherent natural language. We evaluate our approach on mental health intervention, hate speech countering, and sentiment transfer tasks, demonstrating significant improvements over competitive baselines across multiple metrics. Notably, our method achieves superior transfer strength while maintaining content preservation and fluency, as validated through human evaluation. Our work provides a practical foundation for learning optimal policies in complex language tasks where training data is limited.