 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Skeleton-based Zero-Shot Action Recognition with Training-Free Test-Time Adaptation
Dec 12, 2025We introduce Skeleton-Cache, the first training-free test-time adaptation framework for skeleton-based zero-shot action recognition (SZAR), aimed at improving model generalization to unseen actions during inference. Skeleton-Cache reformulates inference as a lightweight retrieval process over a non-parametric cache that stores structured skeleton representations, combining both global and fine-grained local descriptors. To guide the fusion of descriptor-wise predictions, we leverage the semantic reasoning capabilities of large language models (LLMs) to assign class-specific importance weights. By integrating these structured descriptors with LLM-guided semantic priors, Skeleton-Cache dynamically adapts to unseen actions without any additional training or access to training data. Extensive experiments on NTU RGB+D 60/120 and PKU-MMD II demonstrate that Skeleton-Cache consistently boosts the performance of various SZAR backbones under both zero-shot and generalized zero-shot settings. The code is publicly available at https://github.com/Alchemist0754/Skeleton-Cache.
DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action Recognition
Dec 12, 2025Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we introduce \textbf{DynaPURLS}, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module. During inference, this module adapts textual features to the incoming visual stream via a lightweight learnable projection. This refinement process is stabilized by a confidence-aware, class-balanced memory bank, which mitigates error propagation from noisy pseudo-labels. Extensive experiments on three large-scale benchmark datasets, including NTU RGB+D 60/120 and PKU-MMD, demonstrate that DynaPURLS significantly outperforms prior art, setting new state-of-the-art records. The source code is made publicly available at https://github.com/Alchemist0754/DynaPURLS
Part-aware Unified Representation of Language and Skeleton for Zero-shot Action Recognition
Jun 19, 2024While remarkable progress has been made on supervised skeleton-based action recognition, the challenge of zero-shot recognition remains relatively unexplored. In this paper, we argue that relying solely on aligning label-level semantics and global skeleton features is insufficient to effectively transfer locally consistent visual knowledge from seen to unseen classes. To address this limitation, we introduce Part-aware Unified Representation between Language and Skeleton (PURLS) to explore visual-semantic alignment at both local and global scales. PURLS introduces a new prompting module and a novel partitioning module to generate aligned textual and visual representations across different levels. The former leverages a pre-trained GPT-3 to infer refined descriptions of the global and local (body-part-based and temporal-interval-based) movements from the original action labels. The latter employs an adaptive sampling strategy to group visual features from all body joint movements that are semantically relevant to a given description. Our approach is evaluated on various skeleton/language backbones and three large-scale datasets, i.e., NTU-RGB+D 60, NTU-RGB+D 120, and a newly curated dataset Kinetics-skeleton 200. The results showcase the universality and superior performance of PURLS, surpassing prior skeleton-based solutions and standard baselines from other domains. The source codes can be accessed at https://github.com/azzh1/PURLS.
Action-OOD: An End-to-End Skeleton-Based Model for Robust Out-of-Distribution Human Action Detection
May 31, 2024



Human action recognition is a crucial task in computer vision systems. However, in real-world scenarios, human actions often fall outside the distribution of training data, requiring a model to both recognize in-distribution (ID) actions and reject out-of-distribution (OOD) ones. Despite its importance, there has been limited research on OOD detection in human actions. Existing works on OOD detection mainly focus on image data with RGB structure, and many methods are post-hoc in nature. While these methods are convenient and computationally efficient, they often lack sufficient accuracy and fail to consider the presence of OOD samples. To address these challenges, we propose a novel end-to-end skeleton-based model called Action-OOD, specifically designed for OOD human action detection. Unlike some existing approaches that may require prior knowledge of existing OOD data distribution, our model solely utilizes in-distribution (ID) data during the training stage, effectively mitigating the overconfidence issue prevalent in OOD detection. We introduce an attention-based feature fusion block, which enhances the model's capability to recognize unknown classes while preserving classification accuracy for known classes. Further, we present a novel energy-based loss function and successfully integrate it with the traditional cross-entropy loss to maximize the separation of data distributions between ID and OOD. Through extensive experiments conducted on NTU-RGB+D 60, NTU-RGB+D 120, and Kinetics-400 datasets, we demonstrate the superior performance of our proposed approach compared to state-of-the-art methods. Our findings underscore the effectiveness of classic OOD detection techniques in the context of skeleton-based action recognition tasks, offering promising avenues for future research in this field. Code will be available at: https://github.com/YilliaJing/Action-OOD.git.
Adaptive Local-Component-aware Graph Convolutional Network for One-shot Skeleton-based Action Recognition
Sep 21, 2022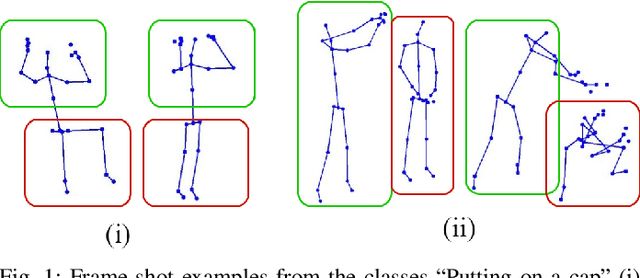
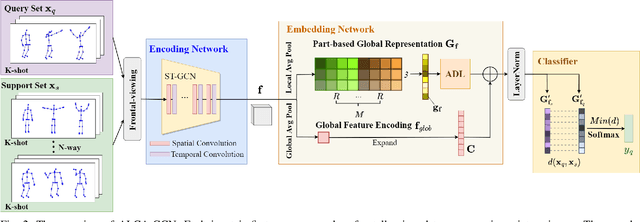
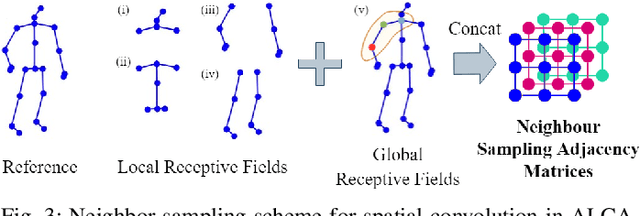

Skeleton-based action recognition receives increasing attention because the skeleton representations reduce the amount of training data by eliminating visual information irrelevant to actions. To further improve the sample efficiency, meta-learning-based one-shot learning solutions were developed for skeleton-based action recognition. These methods find the nearest neighbor according to the similarity between instance-level global average embedding. However, such measurement holds unstable representativity due to inadequate generalized learning on local invariant and noisy features, while intuitively, more fine-grained recognition usually relies on determining key local body movements. To address this limitation, we present the Adaptive Local-Component-aware Graph Convolutional Network, which replaces the comparison metric with a focused sum of similarity measurements on aligned local embedding of action-critical spatial/temporal segments. Comprehensive one-shot experiments on the public benchmark of NTU-RGB+D 120 indicate that our method provides a stronger representation than the global embedding and helps our model reach state-of-the-art.