 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-Time ECG and EMG Modeling on $μ$NPUs
Apr 21, 2026The miniaturisation of neural processing units (NPUs) and other low-power accelerators has enabled their integration into microcontroller-scale wearable hardware, supporting near-real-time, offline, and privacy-preserving inference. Yet physiological signal analysis has remained infeasible on such hardware; recent Transformer-based models show state-of-the-art performance but are prohibitively large for resource- and power-constrained hardware and incompatible with $μ$NPUs due to their dynamic attention operations. We introduce PhysioLite, a lightweight, NPU-compatible model architecture and training framework for ECG/EMG signal analysis. Using learnable wavelet filter banks, CPU-offloaded positional encoding, and hardware-aware layer design, PhysioLite reaches performance comparable to state-of-the-art Transformer-based foundation models on ECG and EMG benchmarks, while being <10% of the size ($\sim$370KB with 8-bit quantization). We also profile its component-wise latency and resource consumption on both the MAX78000 and HX6538 WE2 $μ$NPUs, demonstrating its viability for signal analysis on constrained, battery-powered hardware. We release our model(s) and training framework at: https://github.com/j0shmillar/physiolite.
AdaNODEs: Test Time Adaptation for Time Series Forecasting Using Neural ODEs
Jan 19, 2026Test time adaptation (TTA) has emerged as a promising solution to adapt pre-trained models to new, unseen data distributions using unlabeled target domain data. However, most TTA methods are designed for independent data, often overlooking the time series data and rarely addressing forecasting tasks. This paper presents AdaNODEs, an innovative source-free TTA method tailored explicitly for time series forecasting. By leveraging Neural Ordinary Differential Equations (NODEs), we propose a novel adaptation framework that accommodates the unique characteristics of distribution shifts in time series data. Moreover, we innovatively propose a new loss function to tackle TTA for forecasting tasks. AdaNODEs only requires updating limited model parameters, showing effectiveness in capturing temporal dependencies while avoiding significant memory usage. Extensive experiments with one- and high-dimensional data demonstrate that AdaNODEs offer relative improvements of 5.88\% and 28.4\% over the SOTA baselines, especially demonstrating robustness across higher severity distribution shifts.
Benchmarking Federated Learning for Throughput Prediction in 5G Live Streaming Applications
Aug 11, 2025Accurate and adaptive network throughput prediction is essential for latency-sensitive and bandwidth-intensive applications in 5G and emerging 6G networks. However, most existing methods rely on centralized training with uniformly collected data, limiting their applicability in heterogeneous mobile environments with non-IID data distributions. This paper presents the first comprehensive benchmarking of federated learning (FL) strategies for throughput prediction in realistic 5G edge scenarios. We evaluate three aggregation algorithms - FedAvg, FedProx, and FedBN - across four time-series architectures: LSTM, CNN, CNN+LSTM, and Transformer, using five diverse real-world datasets. We systematically analyze the effects of client heterogeneity, cohort size, and history window length on prediction performance. Our results reveal key trade-offs among model complexities, convergence rates, and generalization. It is found that FedBN consistently delivers robust performance under non-IID conditions. On the other hand, LSTM and Transformer models outperform CNN-based baselines by up to 80% in R2 scores. Moreover, although Transformers converge in half the rounds of LSTM, they require longer history windows to achieve a high R2, indicating higher context dependence. LSTM is, therefore, found to achieve a favorable balance between accuracy, rounds, and temporal footprint. To validate the end-to-end applicability of the framework, we have integrated our FL-based predictors into a live adaptive streaming pipeline. It is seen that FedBN-based LSTM and Transformer models improve mean QoE scores by 11.7% and 11.4%, respectively, over FedAvg, while also reducing the variance. These findings offer actionable insights for building scalable, privacy-preserving, and edge-aware throughput prediction systems in next-generation wireless networks.
E-BATS: Efficient Backpropagation-Free Test-Time Adaptation for Speech Foundation Models
Jun 08, 2025



Speech Foundation Models encounter significant performance degradation when deployed in real-world scenarios involving acoustic domain shifts, such as background noise and speaker accents. Test-time adaptation (TTA) has recently emerged as a viable strategy to address such domain shifts at inference time without requiring access to source data or labels. However, existing TTA approaches, particularly those relying on backpropagation, are memory-intensive, limiting their applicability in speech tasks and resource-constrained settings. Although backpropagation-free methods offer improved efficiency, existing ones exhibit poor accuracy. This is because they are predominantly developed for vision tasks, which fundamentally differ from speech task formulations, noise characteristics, and model architecture, posing unique transferability challenges. In this paper, we introduce E-BATS, the first Efficient BAckpropagation-free TTA framework designed explicitly for speech foundation models. E-BATS achieves a balance between adaptation effectiveness and memory efficiency through three key components: (i) lightweight prompt adaptation for a forward-pass-based feature alignment, (ii) a multi-scale loss to capture both global (utterance-level) and local distribution shifts (token-level) and (iii) a test-time exponential moving average mechanism for stable adaptation across utterances. Experiments conducted on four noisy speech datasets spanning sixteen acoustic conditions demonstrate consistent improvements, with 4.1%-13.5% accuracy gains over backpropagation-free baselines and 2.0-6.4 times GPU memory savings compared to backpropagation-based methods. By enabling scalable and robust adaptation under acoustic variability, this work paves the way for developing more efficient adaptation approaches for practical speech processing systems in real-world environments.
BoTTA: Benchmarking on-device Test Time Adaptation
Apr 16, 2025The performance of deep learning models depends heavily on test samples at runtime, and shifts from the training data distribution can significantly reduce accuracy. Test-time adaptation (TTA) addresses this by adapting models during inference without requiring labeled test data or access to the original training set. While research has explored TTA from various perspectives like algorithmic complexity, data and class distribution shifts, model architectures, and offline versus continuous learning, constraints specific to mobile and edge devices remain underexplored. We propose BoTTA, a benchmark designed to evaluate TTA methods under practical constraints on mobile and edge devices. Our evaluation targets four key challenges caused by limited resources and usage conditions: (i) limited test samples, (ii) limited exposure to categories, (iii) diverse distribution shifts, and (iv) overlapping shifts within a sample. We assess state-of-the-art TTA methods under these scenarios using benchmark datasets and report system-level metrics on a real testbed. Furthermore, unlike prior work, we align with on-device requirements by advocating periodic adaptation instead of continuous inference-time adaptation. Experiments reveal key insights: many recent TTA algorithms struggle with small datasets, fail to generalize to unseen categories, and depend on the diversity and complexity of distribution shifts. BoTTA also reports device-specific resource use. For example, while SHOT improves accuracy by $2.25\times$ with $512$ adaptation samples, it uses $1.08\times$ peak memory on Raspberry Pi versus the base model. BoTTA offers actionable guidance for TTA in real-world, resource-constrained deployments.
SoundCollage: Automated Discovery of New Classes in Audio Datasets
Oct 30, 2024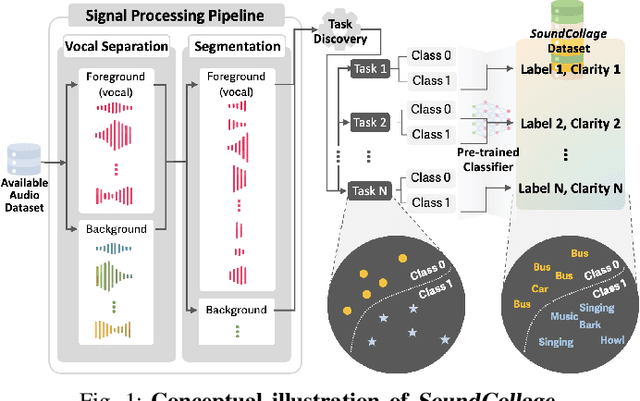



Developing new machine learning applications often requires the collection of new datasets. However, existing datasets may already contain relevant information to train models for new purposes. We propose SoundCollage: a framework to discover new classes within audio datasets by incorporating (1) an audio pre-processing pipeline to decompose different sounds in audio samples and (2) an automated model-based annotation mechanism to identify the discovered classes. Furthermore, we introduce clarity measure to assess the coherence of the discovered classes for better training new downstream applications. Our evaluations show that the accuracy of downstream audio classifiers within discovered class samples and held-out datasets improves over the baseline by up to 34.7% and 4.5%, respectively, highlighting the potential of SoundCollage in making datasets reusable by labeling with newly discovered classes. To encourage further research in this area, we open-source our code at https://github.com/nokia-bell-labs/audio-class-discovery.
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Mar 02, 2024



Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
AmicroN: A Framework for Generating Annotations for Human Activity Recognition with Granular Micro-Activities
Jun 22, 2023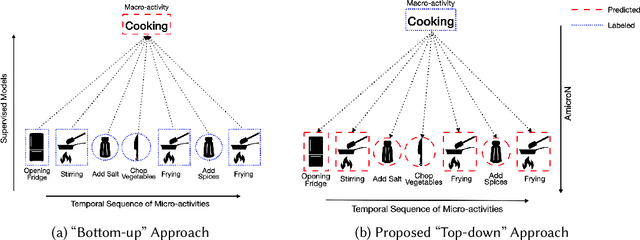


Efficient human activity recognition (HAR) using sensor data needs a significant volume of annotated data. The growing volume of unlabelled sensor data has challenged conventional practices for gathering HAR annotations with human-in-the-loop approaches, often leading to the collection of shallower annotations. These shallower annotations ignore the fine-grained micro-activities that constitute any complex activities of daily living (ADL). Understanding this, we, in this paper, first analyze this lack of granular annotations from available pre-annotated datasets to understand the practical inconsistencies and also perform a detailed survey to look into the human perception surrounding annotations. Drawing motivations from these, we next develop the framework AmicroN that can automatically generate micro-activity annotations using locomotive signatures and the available coarse-grain macro-activity labels. In the backend, AmicroN applies change-point detection followed by zero-shot learning with activity embeddings to identify the unseen micro-activities in an unsupervised manner. Rigorous evaluation on publicly available datasets shows that AmicroN can accurately generate micro-activity annotations with a median F1-score of >0.75. Additionally, we also show that AmicroN can be used in a plug-and-play manner with Large Language Models (LLMs) to obtain the micro-activity labels, thus making it more practical for realistic applications.
Centaur: Federated Learning for Constrained Edge Devices
Nov 12, 2022



Federated learning (FL) on deep neural networks facilitates new applications at the edge, especially for wearable and Internet-of-Thing devices. Such devices capture a large and diverse amount of data, but they have memory, compute, power, and connectivity constraints which hinder their participation in FL. We propose Centaur, a multitier FL framework, enabling ultra-constrained devices to efficiently participate in FL on large neural nets. Centaur combines two major ideas: (i) a data selection scheme to choose a portion of samples that accelerates the learning, and (ii) a partition-based training algorithm that integrates both constrained and powerful devices owned by the same user. Evaluations, on four benchmark neural nets and three datasets, show that Centaur gains ~10% higher accuracy than local training on constrained devices with ~58% energy saving on average. Our experimental results also demonstrate the superior efficiency of Centaur when dealing with imbalanced data, client participation heterogeneity, and various network connection probabilities.
AQuaMoHo: Localized Low-Cost Outdoor Air Quality Sensing over a Thermo-Hygrometer
Apr 25, 2022

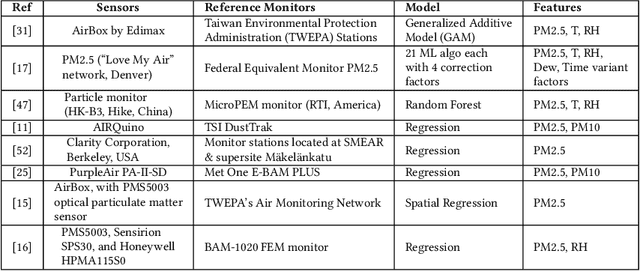
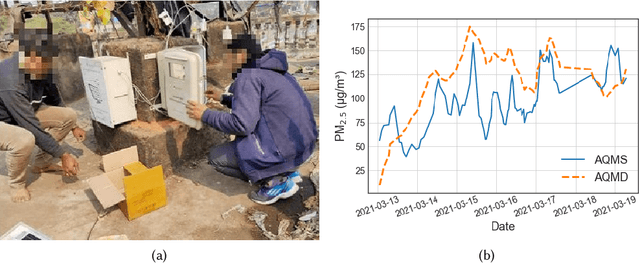
Efficient air quality sensing serves as one of the essential services provided in any recent smart city. Mostly facilitated by sparsely deployed Air Quality Monitoring Stations (AQMSs) that are difficult to install and maintain, the overall spatial variation heavily impacts air quality monitoring for locations far enough from these pre-deployed public infrastructures. To mitigate this, we in this paper propose a framework named AQuaMoHo that can annotate data obtained from a low-cost thermo-hygrometer (as the sole physical sensing device) with the AQI labels, with the help of additional publicly crawled Spatio-temporal information of that locality. At its core, AQuaMoHo exploits the temporal patterns from a set of readily available spatial features using an LSTM-based model and further enhances the overall quality of the annotation using temporal attention. From a thorough study of two different cities, we observe that AQuaMoHo can significantly help annotate the air quality data on a personal scale.