 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmicroN: A Framework for Generating Annotations for Human Activity Recognition with Granular Micro-Activities
Jun 22, 2023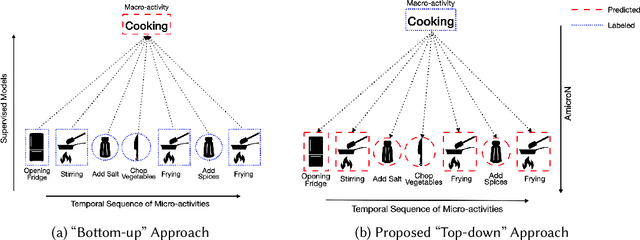

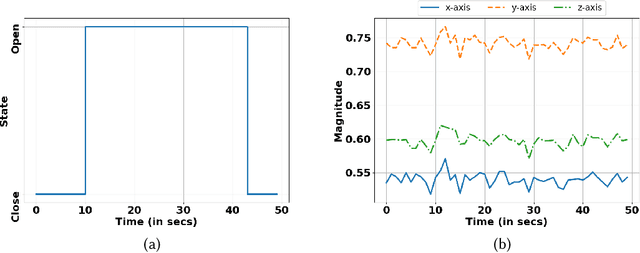

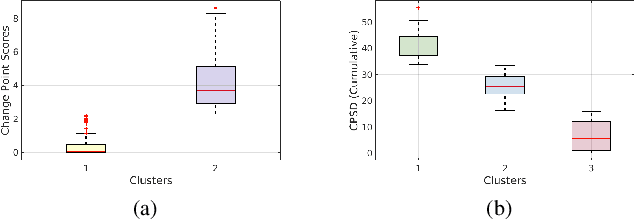
Efficient human activity recognition (HAR) using sensor data needs a significant volume of annotated data. The growing volume of unlabelled sensor data has challenged conventional practices for gathering HAR annotations with human-in-the-loop approaches, often leading to the collection of shallower annotations. These shallower annotations ignore the fine-grained micro-activities that constitute any complex activities of daily living (ADL). Understanding this, we, in this paper, first analyze this lack of granular annotations from available pre-annotated datasets to understand the practical inconsistencies and also perform a detailed survey to look into the human perception surrounding annotations. Drawing motivations from these, we next develop the framework AmicroN that can automatically generate micro-activity annotations using locomotive signatures and the available coarse-grain macro-activity labels. In the backend, AmicroN applies change-point detection followed by zero-shot learning with activity embeddings to identify the unseen micro-activities in an unsupervised manner. Rigorous evaluation on publicly available datasets shows that AmicroN can accurately generate micro-activity annotations with a median F1-score of >0.75. Additionally, we also show that AmicroN can be used in a plug-and-play manner with Large Language Models (LLMs) to obtain the micro-activity labels, thus making it more practical for realistic applications.
Accoustate: Auto-annotation of IMU-generated Activity Signatures under Smart Infrastructure
Dec 08, 2021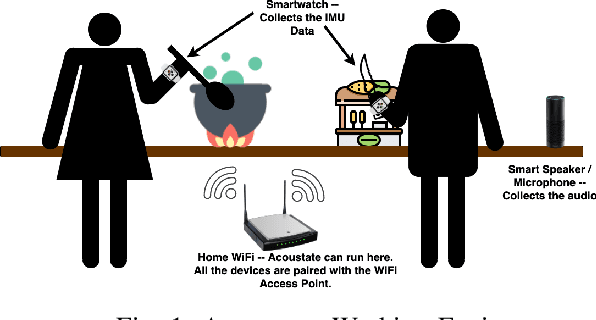
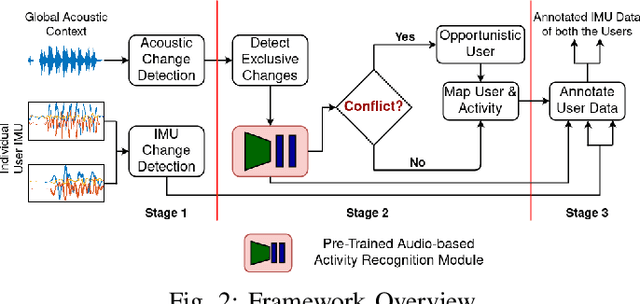
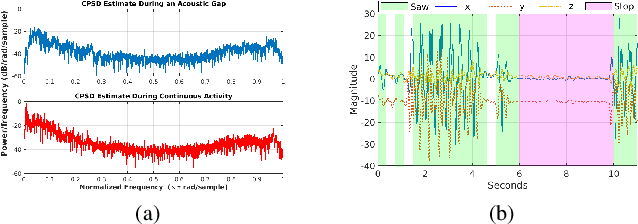
Human activities within smart infrastructures generate a vast amount of IMU data from the wearables worn by individuals. Many existing studies rely on such sensory data for human activity recognition (HAR); however, one of the major bottlenecks is their reliance on pre-annotated or labeled data. Manual human-driven annotations are neither scalable nor efficient, whereas existing auto-annotation techniques heavily depend on video signatures. Still, video-based auto-annotation needs high computation resources and has privacy concerns when the data from a personal space, like a smart-home, is transferred to the cloud. This paper exploits the acoustic signatures generated from human activities to label the wearables' IMU data at the edge, thus mitigating resource requirement and data privacy concerns. We utilize acoustic-based pre-trained HAR models for cross-modal labeling of the IMU data even when two individuals perform simultaneous but different activities under the same environmental context. We observe that non-overlapping acoustic gaps exist with a high probability during the simultaneous activities performed by two individuals in the environment's acoustic context, which helps us resolve the overlapping activity signatures to label them individually. A principled evaluation of the proposed approach on two real-life in-house datasets further augmented to create a dual occupant setup, shows that the framework can correctly annotate a significant volume of unlabeled IMU data from both individuals with an accuracy of $\mathbf{82.59\%}$ ($\mathbf{\pm 17.94\%}$) and $\mathbf{98.32\%}$ ($\mathbf{\pm 3.68\%}$), respectively, for a workshop and a kitchen environment.