 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoHAR: Understanding Hyperlocal Human Activities with Pollution Sensor Networks
May 10, 2026Low-cost air quality sensors are becoming ubiquitous in our daily lives as public awareness of air pollution continues to grow, and people take measures to monitor and improve the air they breathe indoors. Besides the standard operation of these sensors, fluctuations in environmental parameters can be leveraged to understand human behavior and activities in indoor spaces. Unlike traditional audio-visual, Radio Frequency, and inertial sensors, air quality sensors are easily scalable to a household, are privacy-preserving, and more economical. Such distributed sensor networks must jointly make decisions to monitor indoor occupants for downstream smart home and healthcare applications. However, due to low processing power, memory, and energy, they often struggle to maintain distributed data consensus and identify activity-affected sensor groups for accurate on-device inference. In this paper, we propose PoHAR framework that implements: (i) a conflict-free replicated data primitive for data sharing, (ii) a hierarchical clustering for ESP32 to detect activity-affected sensor groups with a self-supervised distance metric, and (iii) a leader-based group inference with off-the-shelf ML classifiers, enabling the sensor network to collaboratively detect hyperlocal indoor activities. Our extensive experiments demonstrated on-device activity detection, achieving 97.41% accuracy for indoor activity and 99.68% for cooking activity, using off-the-shelf ML models with latency below 34 microseconds.
Benchmarking Federated Learning for Throughput Prediction in 5G Live Streaming Applications
Aug 11, 2025Accurate and adaptive network throughput prediction is essential for latency-sensitive and bandwidth-intensive applications in 5G and emerging 6G networks. However, most existing methods rely on centralized training with uniformly collected data, limiting their applicability in heterogeneous mobile environments with non-IID data distributions. This paper presents the first comprehensive benchmarking of federated learning (FL) strategies for throughput prediction in realistic 5G edge scenarios. We evaluate three aggregation algorithms - FedAvg, FedProx, and FedBN - across four time-series architectures: LSTM, CNN, CNN+LSTM, and Transformer, using five diverse real-world datasets. We systematically analyze the effects of client heterogeneity, cohort size, and history window length on prediction performance. Our results reveal key trade-offs among model complexities, convergence rates, and generalization. It is found that FedBN consistently delivers robust performance under non-IID conditions. On the other hand, LSTM and Transformer models outperform CNN-based baselines by up to 80% in R2 scores. Moreover, although Transformers converge in half the rounds of LSTM, they require longer history windows to achieve a high R2, indicating higher context dependence. LSTM is, therefore, found to achieve a favorable balance between accuracy, rounds, and temporal footprint. To validate the end-to-end applicability of the framework, we have integrated our FL-based predictors into a live adaptive streaming pipeline. It is seen that FedBN-based LSTM and Transformer models improve mean QoE scores by 11.7% and 11.4%, respectively, over FedAvg, while also reducing the variance. These findings offer actionable insights for building scalable, privacy-preserving, and edge-aware throughput prediction systems in next-generation wireless networks.
RadarTrack: Enhancing Ego-Vehicle Speed Estimation with Single-chip mmWave Radar
Apr 20, 2025In this work, we introduce RadarTrack, an innovative ego-speed estimation framework utilizing a single-chip millimeter-wave (mmWave) radar to deliver robust speed estimation for mobile platforms. Unlike previous methods that depend on cross-modal learning and computationally intensive Deep Neural Networks (DNNs), RadarTrack utilizes a novel phase-based speed estimation approach. This method effectively overcomes the limitations of conventional ego-speed estimation approaches which rely on doppler measurements and static surrondings. RadarTrack is designed for low-latency operation on embedded platforms, making it suitable for real-time applications where speed and efficiency are critical. Our key contributions include the introduction of a novel phase-based speed estimation technique solely based on signal processing and the implementation of a real-time prototype validated through extensive real-world evaluations. By providing a reliable and lightweight solution for ego-speed estimation, RadarTrack holds significant potential for a wide range of applications, including micro-robotics, augmented reality, and autonomous navigation.
Generation of Optimized Solidity Code for Machine Learning Models using LLMs
Mar 08, 2025



While a plethora of machine learning (ML) models are currently available, along with their implementation on disparate platforms, there is hardly any verifiable ML code which can be executed on public blockchains. We propose a novel approach named LMST that enables conversion of the inferencing path of an ML model as well as its weights trained off-chain into Solidity code using Large Language Models (LLMs). Extensive prompt engineering is done to achieve gas cost optimization beyond mere correctness of the produced code, while taking into consideration the capabilities and limitations of the Ethereum Virtual Machine. We have also developed a proof of concept decentralized application using the code so generated for verifying the accuracy claims of the underlying ML model. An extensive set of experiments demonstrate the feasibility of deploying ML models on blockchains through automated code translation using LLMs.
Indoor Air Quality Dataset with Activities of Daily Living in Low to Middle-income Communities
Jul 19, 2024
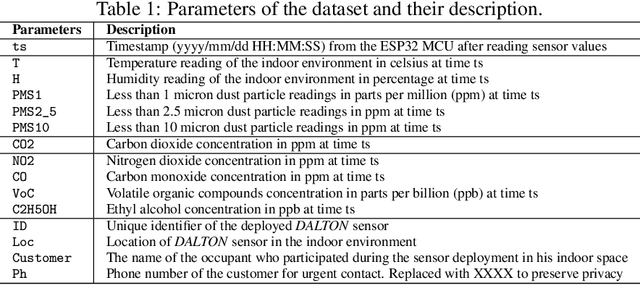

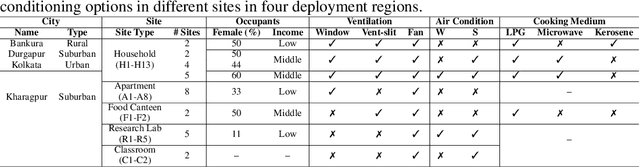
In recent years, indoor air pollution has posed a significant threat to our society, claiming over 3.2 million lives annually. Developing nations, such as India, are most affected since lack of knowledge, inadequate regulation, and outdoor air pollution lead to severe daily exposure to pollutants. However, only a limited number of studies have attempted to understand how indoor air pollution affects developing countries like India. To address this gap, we present spatiotemporal measurements of air quality from 30 indoor sites over six months during summer and winter seasons. The sites are geographically located across four regions of type: rural, suburban, and urban, covering the typical low to middle-income population in India. The dataset contains various types of indoor environments (e.g., studio apartments, classrooms, research laboratories, food canteens, and residential households), and can provide the basis for data-driven learning model research aimed at coping with unique pollution patterns in developing countries. This unique dataset demands advanced data cleaning and imputation techniques for handling missing data due to power failure or network outages during data collection. Furthermore, through a simple speech-to-text application, we provide real-time indoor activity labels annotated by occupants. Therefore, environmentalists and ML enthusiasts can utilize this dataset to understand the complex patterns of the pollutants under different indoor activities, identify recurring sources of pollution, forecast exposure, improve floor plans and room structures of modern indoor designs, develop pollution-aware recommender systems, etc.
Dynamic Ego-Velocity estimation Using Moving mmWave Radar: A Phase-Based Approach
Apr 15, 2024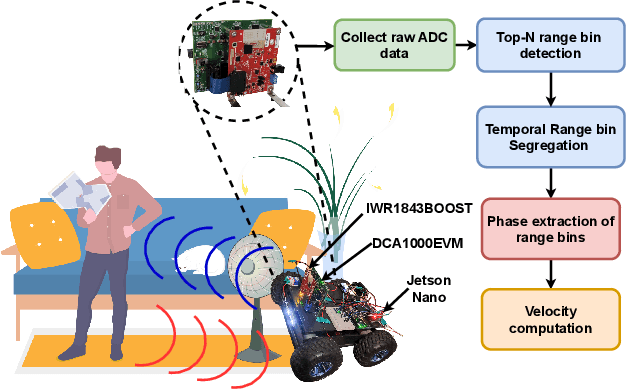
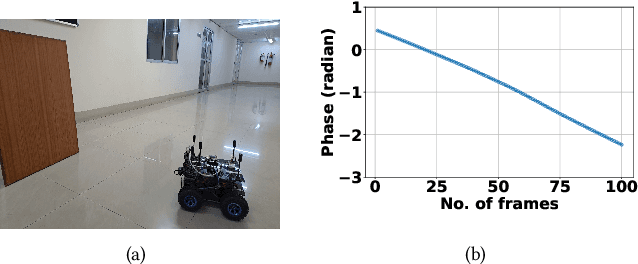
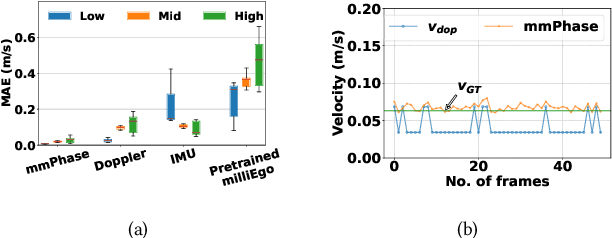
Precise ego-motion measurement is crucial for various applications, including robotics, augmented reality, and autonomous navigation. In this poster, we propose mmPhase, an odometry framework based on single-chip millimetre-wave (mmWave) radar for robust ego-motion estimation in mobile platforms without requiring additional modalities like the visual, wheel, or inertial odometry. mmPhase leverages a phase-based velocity estimation approach to overcome the limitations of conventional doppler resolution. For real-world evaluations of mmPhase we have developed an ego-vehicle prototype. Compared to the state-of-the-art baselines, mmPhase shows superior performance in ego-velocity estimation.
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Mar 02, 2024



Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
AmicroN: A Framework for Generating Annotations for Human Activity Recognition with Granular Micro-Activities
Jun 22, 2023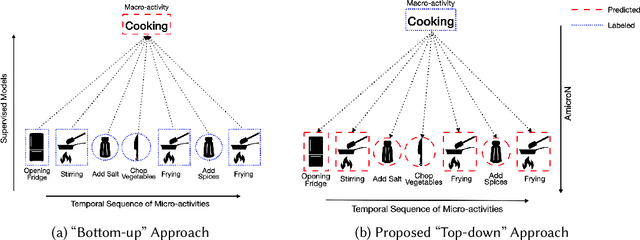

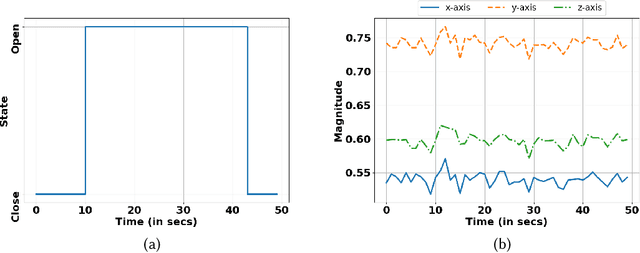

Efficient human activity recognition (HAR) using sensor data needs a significant volume of annotated data. The growing volume of unlabelled sensor data has challenged conventional practices for gathering HAR annotations with human-in-the-loop approaches, often leading to the collection of shallower annotations. These shallower annotations ignore the fine-grained micro-activities that constitute any complex activities of daily living (ADL). Understanding this, we, in this paper, first analyze this lack of granular annotations from available pre-annotated datasets to understand the practical inconsistencies and also perform a detailed survey to look into the human perception surrounding annotations. Drawing motivations from these, we next develop the framework AmicroN that can automatically generate micro-activity annotations using locomotive signatures and the available coarse-grain macro-activity labels. In the backend, AmicroN applies change-point detection followed by zero-shot learning with activity embeddings to identify the unseen micro-activities in an unsupervised manner. Rigorous evaluation on publicly available datasets shows that AmicroN can accurately generate micro-activity annotations with a median F1-score of >0.75. Additionally, we also show that AmicroN can be used in a plug-and-play manner with Large Language Models (LLMs) to obtain the micro-activity labels, thus making it more practical for realistic applications.
AQuaMoHo: Localized Low-Cost Outdoor Air Quality Sensing over a Thermo-Hygrometer
Apr 25, 2022

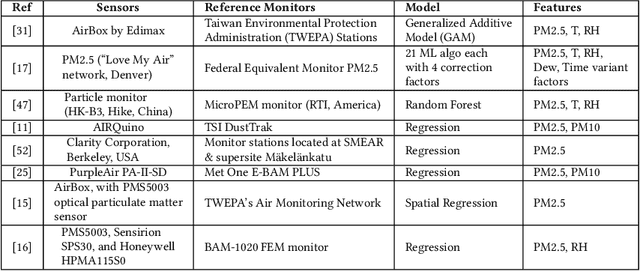
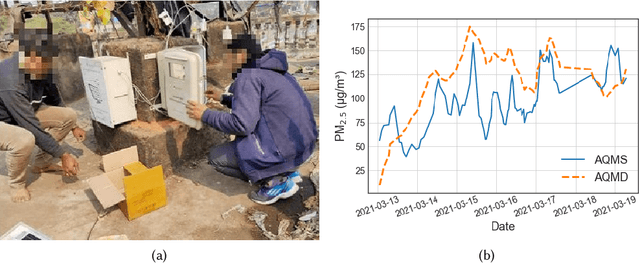
Efficient air quality sensing serves as one of the essential services provided in any recent smart city. Mostly facilitated by sparsely deployed Air Quality Monitoring Stations (AQMSs) that are difficult to install and maintain, the overall spatial variation heavily impacts air quality monitoring for locations far enough from these pre-deployed public infrastructures. To mitigate this, we in this paper propose a framework named AQuaMoHo that can annotate data obtained from a low-cost thermo-hygrometer (as the sole physical sensing device) with the AQI labels, with the help of additional publicly crawled Spatio-temporal information of that locality. At its core, AQuaMoHo exploits the temporal patterns from a set of readily available spatial features using an LSTM-based model and further enhances the overall quality of the annotation using temporal attention. From a thorough study of two different cities, we observe that AQuaMoHo can significantly help annotate the air quality data on a personal scale.
Accoustate: Auto-annotation of IMU-generated Activity Signatures under Smart Infrastructure
Dec 08, 2021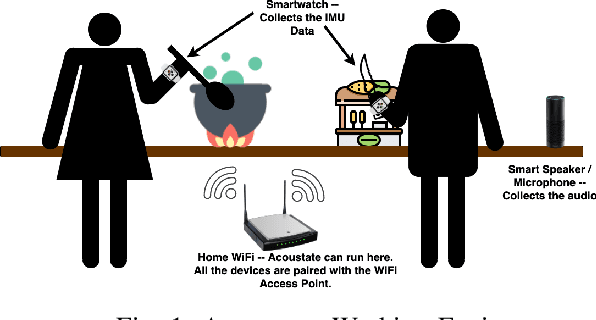
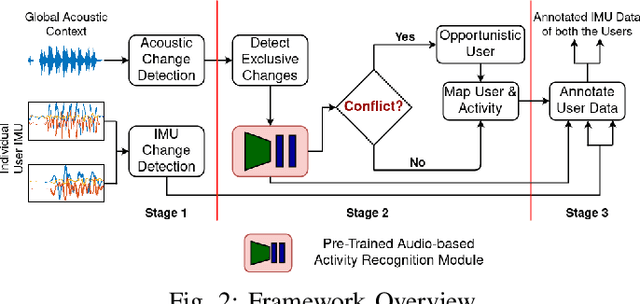
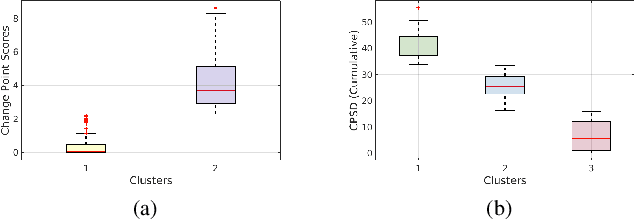
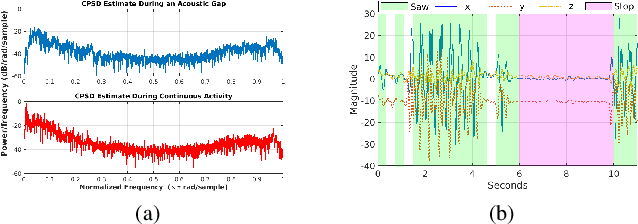
Human activities within smart infrastructures generate a vast amount of IMU data from the wearables worn by individuals. Many existing studies rely on such sensory data for human activity recognition (HAR); however, one of the major bottlenecks is their reliance on pre-annotated or labeled data. Manual human-driven annotations are neither scalable nor efficient, whereas existing auto-annotation techniques heavily depend on video signatures. Still, video-based auto-annotation needs high computation resources and has privacy concerns when the data from a personal space, like a smart-home, is transferred to the cloud. This paper exploits the acoustic signatures generated from human activities to label the wearables' IMU data at the edge, thus mitigating resource requirement and data privacy concerns. We utilize acoustic-based pre-trained HAR models for cross-modal labeling of the IMU data even when two individuals perform simultaneous but different activities under the same environmental context. We observe that non-overlapping acoustic gaps exist with a high probability during the simultaneous activities performed by two individuals in the environment's acoustic context, which helps us resolve the overlapping activity signatures to label them individually. A principled evaluation of the proposed approach on two real-life in-house datasets further augmented to create a dual occupant setup, shows that the framework can correctly annotate a significant volume of unlabeled IMU data from both individuals with an accuracy of $\mathbf{82.59\%}$ ($\mathbf{\pm 17.94\%}$) and $\mathbf{98.32\%}$ ($\mathbf{\pm 3.68\%}$), respectively, for a workshop and a kitchen environment.