 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Security and Privacy in the Digital World: Some Selected Topics
Mar 30, 2024



In the era of generative artificial intelligence and the Internet of Things, while there is explosive growth in the volume of data and the associated need for processing, analysis, and storage, several new challenges are faced in identifying spurious and fake information and protecting the privacy of sensitive data. This has led to an increasing demand for more robust and resilient schemes for authentication, integrity protection, encryption, non-repudiation, and privacy-preservation of data. The chapters in this book present some of the state-of-the-art research works in the field of cryptography and security in computing and communications.
A multiple k-means cluster ensemble framework for clustering citation trajectories
Sep 10, 2023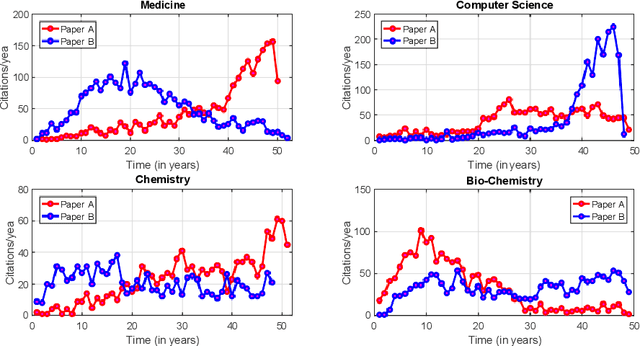
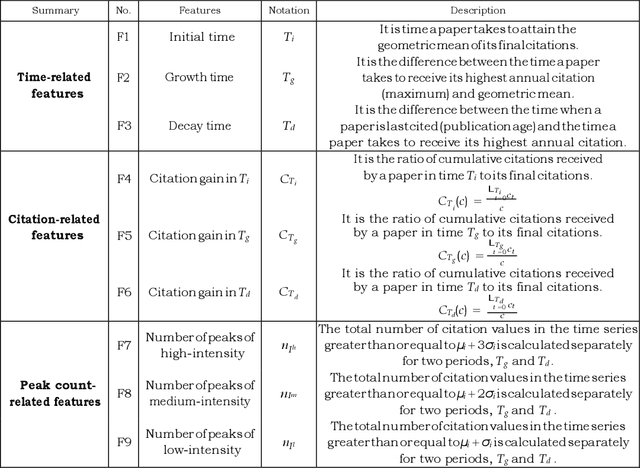
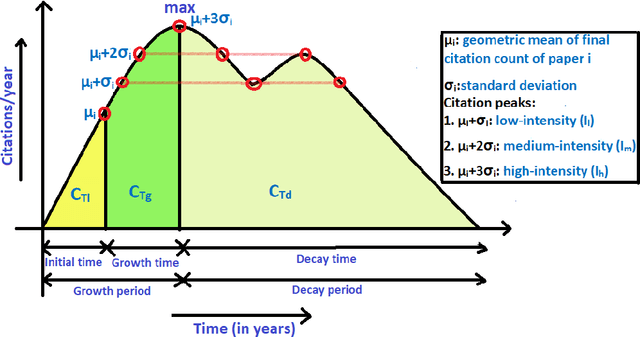
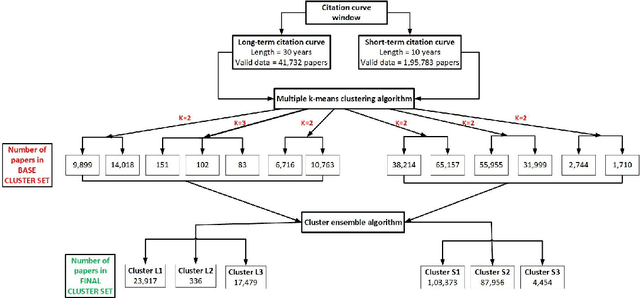
Citation maturity time varies for different articles. However, the impact of all articles is measured in a fixed window. Clustering their citation trajectories helps understand the knowledge diffusion process and reveals that not all articles gain immediate success after publication. Moreover, clustering trajectories is necessary for paper impact recommendation algorithms. It is a challenging problem because citation time series exhibit significant variability due to non linear and non stationary characteristics. Prior works propose a set of arbitrary thresholds and a fixed rule based approach. All methods are primarily parameter dependent. Consequently, it leads to inconsistencies while defining similar trajectories and ambiguities regarding their specific number. Most studies only capture extreme trajectories. Thus, a generalised clustering framework is required. This paper proposes a feature based multiple k means cluster ensemble framework. 1,95,783 and 41,732 well cited articles from the Microsoft Academic Graph data are considered for clustering short term (10 year) and long term (30 year) trajectories, respectively. It has linear run time. Four distinct trajectories are obtained Early Rise Rapid Decline (2.2%), Early Rise Slow Decline (45%), Delayed Rise No Decline (53%), and Delayed Rise Slow Decline (0.8%). Individual trajectory differences for two different spans are studied. Most papers exhibit Early Rise Slow Decline and Delayed Rise No Decline patterns. The growth and decay times, cumulative citation distribution, and peak characteristics of individual trajectories are redefined empirically. A detailed comparative study reveals our proposed methodology can detect all distinct trajectory classes.
AQuaMoHo: Localized Low-Cost Outdoor Air Quality Sensing over a Thermo-Hygrometer
Apr 25, 2022

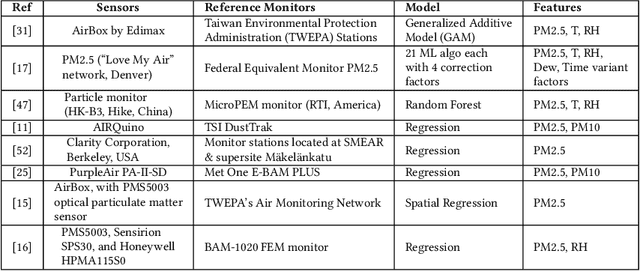
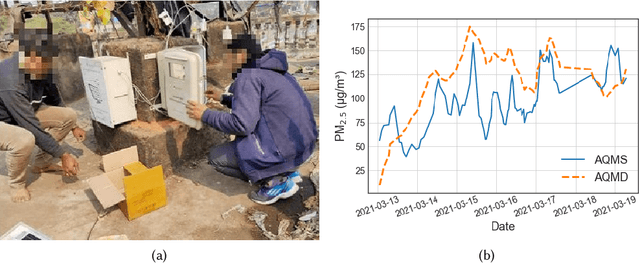
Efficient air quality sensing serves as one of the essential services provided in any recent smart city. Mostly facilitated by sparsely deployed Air Quality Monitoring Stations (AQMSs) that are difficult to install and maintain, the overall spatial variation heavily impacts air quality monitoring for locations far enough from these pre-deployed public infrastructures. To mitigate this, we in this paper propose a framework named AQuaMoHo that can annotate data obtained from a low-cost thermo-hygrometer (as the sole physical sensing device) with the AQI labels, with the help of additional publicly crawled Spatio-temporal information of that locality. At its core, AQuaMoHo exploits the temporal patterns from a set of readily available spatial features using an LSTM-based model and further enhances the overall quality of the annotation using temporal attention. From a thorough study of two different cities, we observe that AQuaMoHo can significantly help annotate the air quality data on a personal scale.
Exploiting Multi-modal Contextual Sensing for City-bus's Stay Location Characterization: Towards Sub-60 Seconds Accurate Arrival Time Prediction
May 24, 2021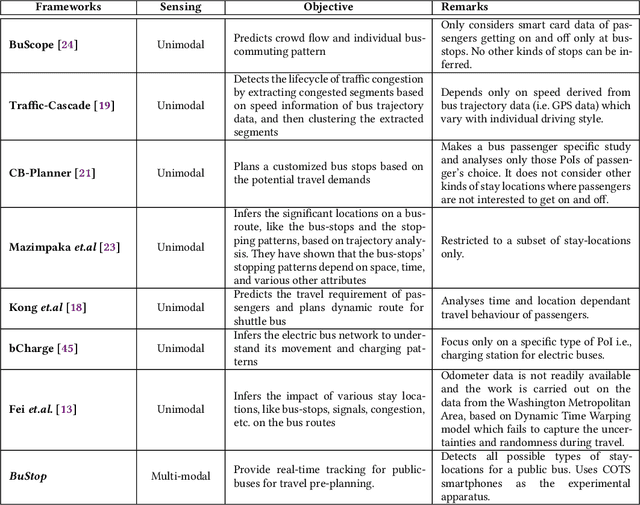
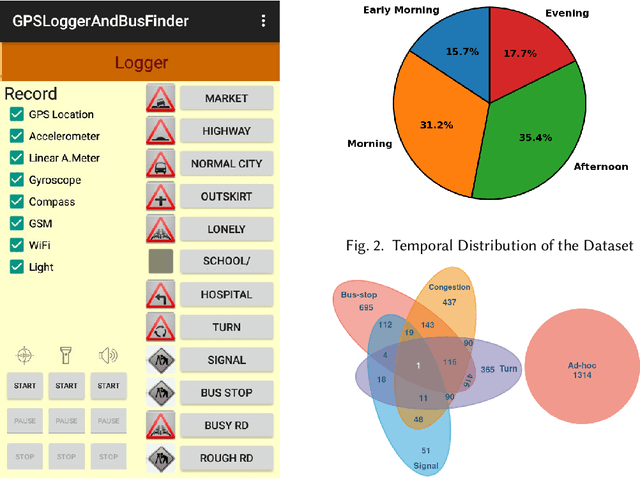


Intelligent city transportation systems are one of the core infrastructures of a smart city. The true ingenuity of such an infrastructure lies in providing the commuters with real-time information about citywide transports like public buses, allowing her to pre-plan the travel. However, providing prior information for transportation systems like public buses in real-time is inherently challenging because of the diverse nature of different stay-locations that a public bus stops. Although straightforward factors stay duration, extracted from unimodal sources like GPS, at these locations look erratic, a thorough analysis of public bus GPS trails for 720km of bus travels at the city of Durgapur, a semi-urban city in India, reveals that several other fine-grained contextual features can characterize these locations accurately. Accordingly, we develop BuStop, a system for extracting and characterizing the stay locations from multi-modal sensing using commuters' smartphones. Using this multi-modal information BuStop extracts a set of granular contextual features that allow the system to differentiate among the different stay-location types. A thorough analysis of BuStop using the collected dataset indicates that the system works with high accuracy in identifying different stay locations like regular bus stops, random ad-hoc stops, stops due to traffic congestion stops at traffic signals, and stops at sharp turns. Additionally, we also develop a proof-of-concept setup on top of BuStop to analyze the potential of the framework in predicting expected arrival time, a critical piece of information required to pre-plan travel, at any given bus stop. Subsequent analysis of the PoC framework, through simulation over the test dataset, shows that characterizing the stay-locations indeed helps make more accurate arrival time predictions with deviations less than 60s from the ground-truth arrival time.