 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROIDS: Robust Outlier-Aware Informed Down-Sampling
Jan 27, 2026Informed down-sampling (IDS) is known to improve performance in symbolic regression when combined with various selection strategies, especially tournament selection. However, recent work found that IDS's gains are not consistent across all problems. Our analysis reveals that IDS performance is worse for problems containing outliers. IDS systematically favors including outliers in subsets which pushes GP towards finding solutions that overfit to outliers. To address this, we introduce ROIDS (Robust Outlier-Aware Informed Down-Sampling), which excludes potential outliers from the sampling process of IDS. With ROIDS it is possible to keep the advantages of IDS without overfitting to outliers and to compete on a wide range of benchmark problems. This is also reflected in our experiments in which ROIDS shows the desired behavior on all studied benchmark problems. ROIDS consistently outperforms IDS on synthetic problems with added outliers as well as on a wide range of complex real-world problems, surpassing IDS on over 80% of the real-world benchmark problems. Moreover, compared to all studied baseline approaches, ROIDS achieves the best average rank across all tested benchmark problems. This robust behavior makes ROIDS a reliable down-sampling method for selection in symbolic regression, especially when outliers may be included in the data set.
Was Tournament Selection All We Ever Needed? A Critical Reflection on Lexicase Selection
Feb 25, 2025



The success of lexicase selection has led to various extensions, including its combination with down-sampling, which further increased performance. However, recent work found that down-sampling also leads to significant improvements in the performance of tournament selection. This raises the question of whether tournament selection combined with down-sampling is the better choice, given its faster running times. To address this question, we run a set of experiments comparing epsilon-lexicase and tournament selection with different down-sampling techniques on synthetic problems of varying noise levels and problem sizes as well as real-world symbolic regression problems. Overall, we find that down-sampling improves generalization and performance even when compared over the same number of generations. This means that down-sampling is beneficial even with way fewer fitness evaluations. Additionally, down-sampling successfully reduces code growth. We observe that population diversity increases for tournament selection when combined with down-sampling. Further, we find that tournament selection and epsilon-lexicase selection with down-sampling perform similar, while tournament selection is significantly faster. We conclude that tournament selection should be further analyzed and improved in future work instead of only focusing on the improvement of lexicase variants.
ComfyGI: Automatic Improvement of Image Generation Workflows
Nov 21, 2024



Automatic image generation is no longer just of interest to researchers, but also to practitioners. However, current models are sensitive to the settings used and automatic optimization methods often require human involvement. To bridge this gap, we introduce ComfyGI, a novel approach to automatically improve workflows for image generation without the need for human intervention driven by techniques from genetic improvement. This enables image generation with significantly higher quality in terms of the alignment with the given description and the perceived aesthetics. On the performance side, we find that overall, the images generated with an optimized workflow are about 50% better compared to the initial workflow in terms of the median ImageReward score. These already good results are even surpassed in our human evaluation, as the participants preferred the images improved by ComfyGI in around 90% of the cases.
Large Language Models Suffer From Their Own Output: An Analysis of the Self-Consuming Training Loop
Nov 28, 2023Large language models (LLM) have become state of the art in many benchmarks and conversational LLM applications like ChatGPT are now widely used by the public. Those LLMs can be used to generate large amounts of content which is posted on the internet to various platforms. As LLMs are trained on datasets usually collected from the internet, this LLM-generated content might be used to train the next generation of LLMs. Therefore, a self-consuming training loop emerges in which new LLM generations are trained on the output from the previous generations. We empirically study this self-consuming training loop using a novel dataset to analytically and accurately measure quality and diversity of generated outputs. We find that this self-consuming training loop initially improves both quality and diversity. However, after a few generations the output inevitably degenerates in diversity. We find that the rate of degeneration depends on the proportion of real and generated data.
Do You Trust ChatGPT? -- Perceived Credibility of Human and AI-Generated Content
Sep 05, 2023
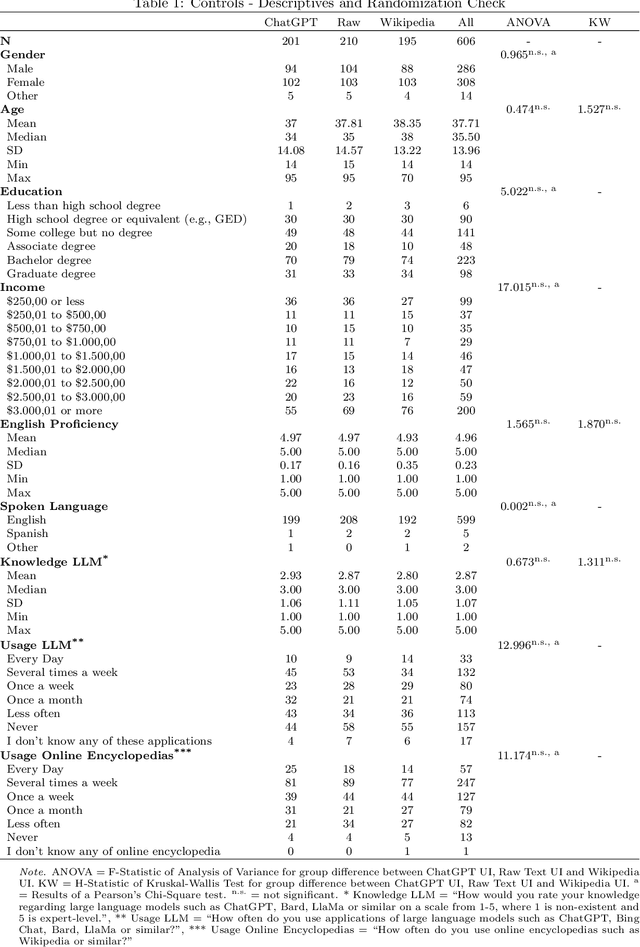
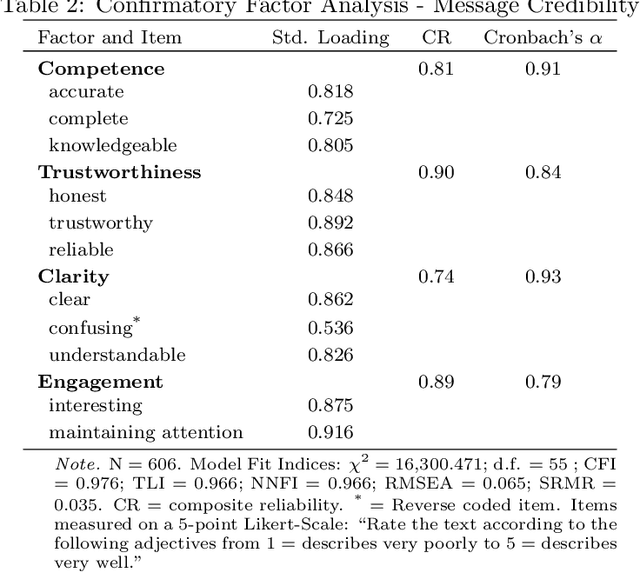
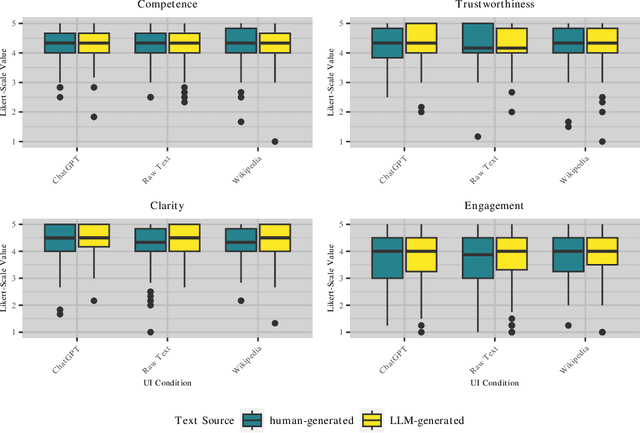
This paper examines how individuals perceive the credibility of content originating from human authors versus content generated by large language models, like the GPT language model family that powers ChatGPT, in different user interface versions. Surprisingly, our results demonstrate that regardless of the user interface presentation, participants tend to attribute similar levels of credibility. While participants also do not report any different perceptions of competence and trustworthiness between human and AI-generated content, they rate AI-generated content as being clearer and more engaging. The findings from this study serve as a call for a more discerning approach to evaluating information sources, encouraging users to exercise caution and critical thinking when engaging with content generated by AI systems.
Analyzing the Interaction Between Down-Sampling and Selection
Apr 14, 2023Genetic programming systems often use large training sets to evaluate the quality of candidate solutions for selection. However, evaluating populations on large training sets can be computationally expensive. Down-sampling training sets has long been used to decrease the computational cost of evaluation in a wide range of application domains. Indeed, recent studies have shown that both random and informed down-sampling can substantially improve problem-solving success for GP systems that use the lexicase parent selection algorithm. We use the PushGP framework to experimentally test whether these down-sampling techniques can also improve problem-solving success in the context of two other commonly used selection methods, fitness-proportionate and tournament selection, across eight GP problems (four program synthesis and four symbolic regression). We verified that down-sampling can benefit the problem-solving success of both fitness-proportionate and tournament selection. However, the number of problems wherein down-sampling improved problem-solving success varied by selection scheme, suggesting that the impact of down-sampling depends both on the problem and choice of selection scheme. Surprisingly, we found that down-sampling was most consistently beneficial when combined with lexicase selection as compared to tournament and fitness-proportionate selection. Overall, our results suggest that down-sampling should be considered more often when solving test-based GP problems.
MTGP: Combining Metamorphic Testing and Genetic Programming
Jan 20, 2023
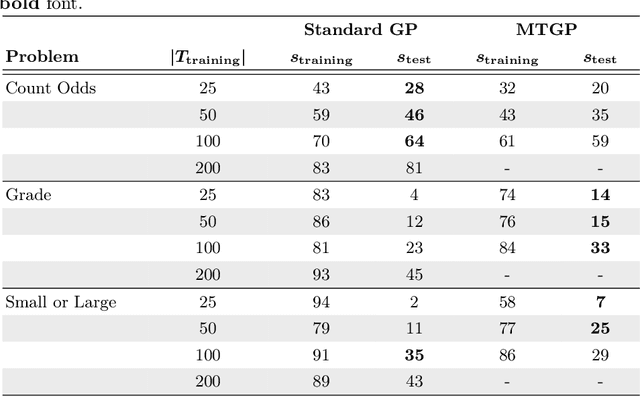
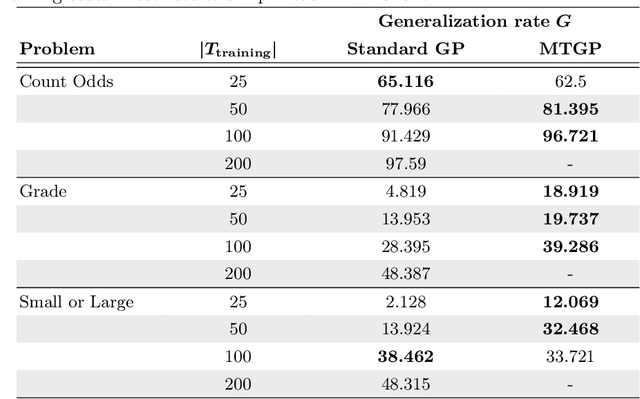
Genetic programming is an evolutionary approach known for its performance in program synthesis. However, it is not yet mature enough for a practical use in real-world software development, since usually many training cases are required to generate programs that generalize to unseen test cases. As in practice, the training cases have to be expensively hand-labeled by the user, we need an approach to check the program behavior with a lower number of training cases. Metamorphic testing needs no labeled input/output examples. Instead, the program is executed multiple times, first on a given (randomly generated) input, followed by related inputs to check whether certain user-defined relations between the observed outputs hold. In this work, we suggest MTGP, which combines metamorphic testing and genetic programming and study its performance and the generalizability of the generated programs. Further, we analyze how the generalizability depends on the number of given labeled training cases. We find that using metamorphic testing combined with labeled training cases leads to a higher generalization rate than the use of labeled training cases alone in almost all studied configurations. Consequently, we recommend researchers to use metamorphic testing in their systems if the labeling of the training data is expensive.
Informed Down-Sampled Lexicase Selection: Identifying productive training cases for efficient problem solving
Jan 04, 2023



Genetic Programming (GP) often uses large training sets and requires all individuals to be evaluated on all training cases during selection. Random down-sampled lexicase selection evaluates individuals on only a random subset of the training cases allowing for more individuals to be explored with the same amount of program executions. However, creating a down-sample randomly might exclude important cases from the current down-sample for a number of generations, while cases that measure the same behavior (synonymous cases) may be overused despite their redundancy. In this work, we introduce Informed Down-Sampled Lexicase Selection. This method leverages population statistics to build down-samples that contain more distinct and therefore informative training cases. Through an empirical investigation across two different GP systems (PushGP and Grammar-Guided GP), we find that informed down-sampling significantly outperforms random down-sampling on a set of contemporary program synthesis benchmark problems. Through an analysis of the created down-samples, we find that important training cases are included in the down-sample consistently across independent evolutionary runs and systems. We hypothesize that this improvement can be attributed to the ability of Informed Down-Sampled Lexicase Selection to maintain more specialist individuals over the course of evolution, while also benefiting from reduced per-evaluation costs.
Choose Your Programming Copilot: A Comparison of the Program Synthesis Performance of GitHub Copilot and Genetic Programming
Nov 15, 2021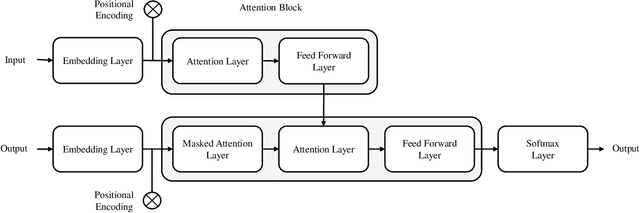
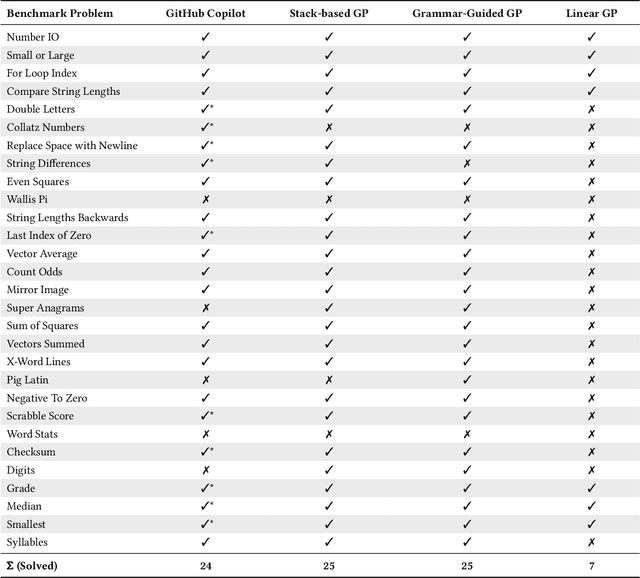

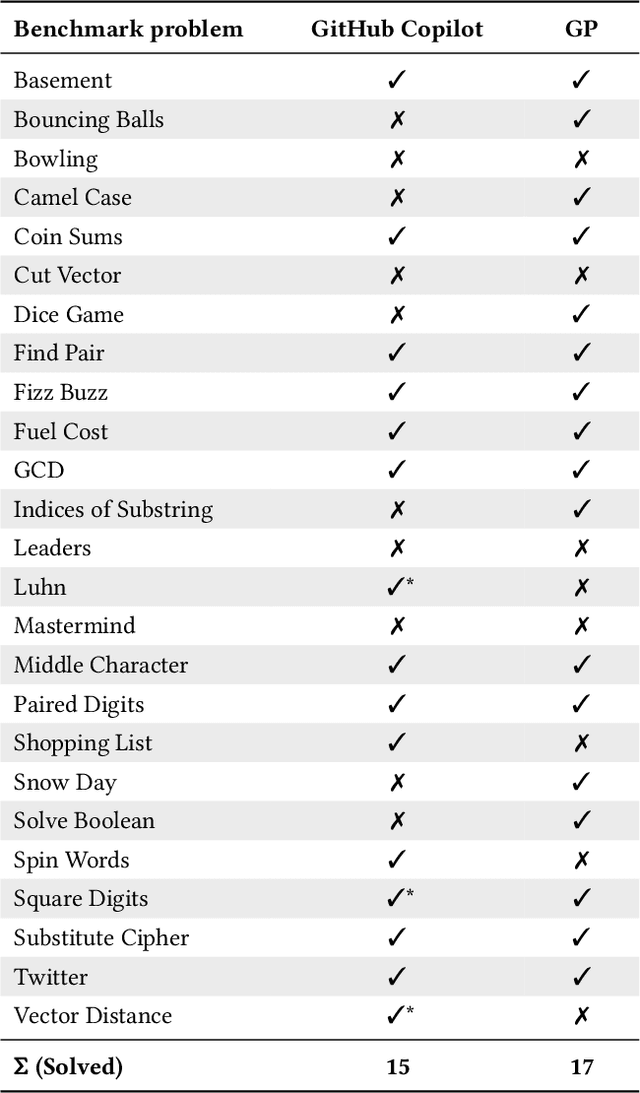
GitHub Copilot, an extension for the Visual Studio Code development environment powered by the large-scale language model Codex, makes automatic program synthesis available for software developers. This model has been extensively studied in the field of deep learning, however, a comparison to genetic programming, which is also known for its performance in automatic program synthesis, has not yet been carried out. In this paper, we evaluate GitHub Copilot on standard program synthesis benchmark problems and compare the achieved results with those from the genetic programming literature. In addition, we discuss the performance of both approaches. We find that the performance of the two approaches on the benchmark problems is quite similar, however, in comparison to GitHub Copilot, the program synthesis approaches based on genetic programming are not yet mature enough to support programmers in practical software development. Genetic programming usually needs a huge amount of expensive hand-labeled training cases and takes too much time to generate solutions. Furthermore, source code generated by genetic programming approaches is often bloated and difficult to understand. For future work on program synthesis with genetic programming, we suggest researchers to focus on improving the execution time, readability, and usability.
The Randomness of Input Data Spaces is an A Priori Predictor for Generalization
Jun 08, 2021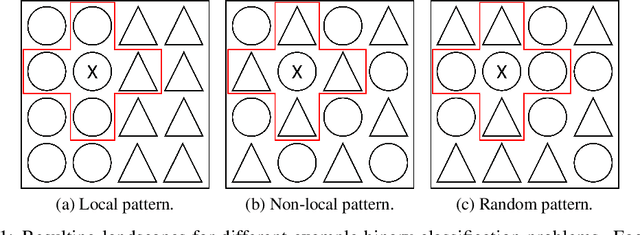
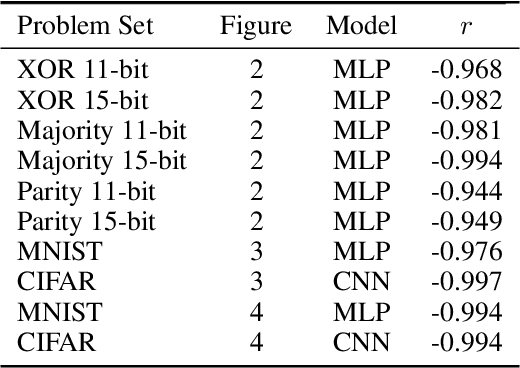
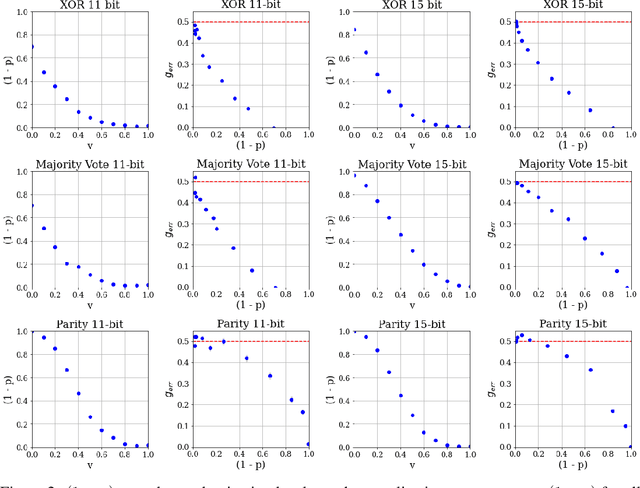
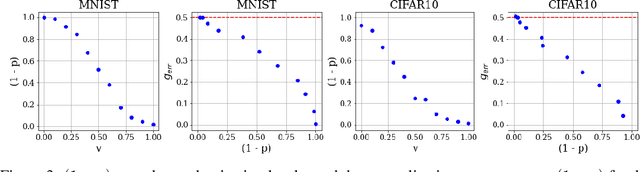
Over-parameterized models can perfectly learn various types of data distributions, however, generalization error is usually lower for real data in comparison to artificial data. This suggests that the properties of data distributions have an impact on generalization capability. This work focuses on the search space defined by the input data and assumes that the correlation between labels of neighboring input values influences generalization. If correlation is low, the randomness of the input data space is high leading to high generalization error. We suggest to measure the randomness of an input data space using Maurer's universal. Results for synthetic classification tasks and common image classification benchmarks (MNIST, CIFAR10, and Microsoft's cats vs. dogs data set) find a high correlation between the randomness of input data spaces and the generalization error of deep neural networks for binary classification problems.