 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Adaptive Mutation Rates for Program Synthesis
Jun 23, 2024

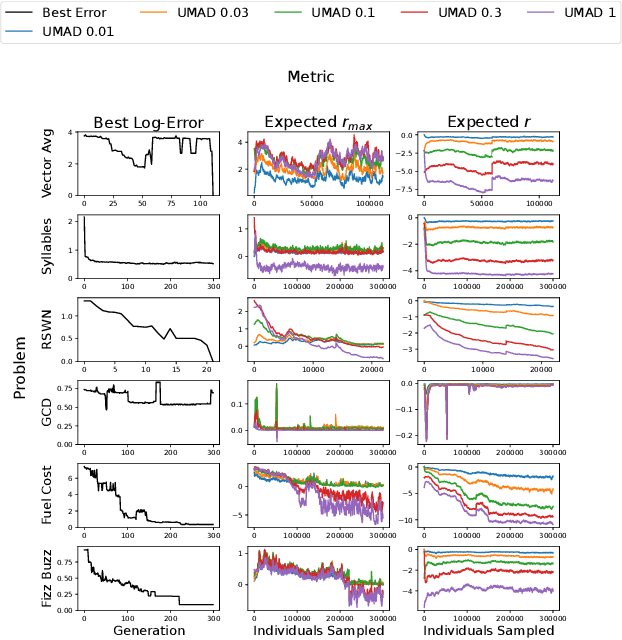

The problem-solving performance of many evolutionary algorithms, including genetic programming systems used for program synthesis, depends on the values of hyperparameters including mutation rates. The mutation method used to produce some of the best results to date on software synthesis benchmark problems, Uniform Mutation by Addition and Deletion (UMAD), adds new genes into a genome at a predetermined rate and then deletes genes at a rate that balances the addition rate, producing no size change on average. While UMAD with a predetermined addition rate outperforms many other mutation and crossover schemes, we do not expect a single rate to be optimal across all problems or all generations within one run of an evolutionary system. However, many current adaptive mutation schemes such as self-adaptive mutation rates suffer from pathologies like the vanishing mutation rate problem, in which the mutation rate quickly decays to zero. We propose an adaptive bandit-based scheme that addresses this problem and essentially removes the need to specify a mutation rate. Although the proposed scheme itself introduces hyperparameters, we either set these to good values or ensemble them in a reasonable range. Results on software synthesis and symbolic regression problems validate the effectiveness of our approach.
Pareto-Optimal Learning from Preferences with Hidden Context
Jun 21, 2024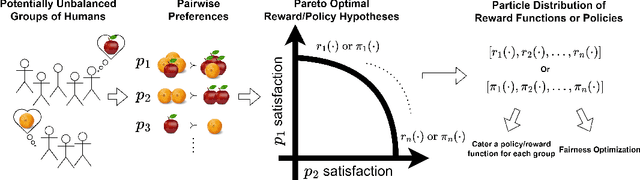
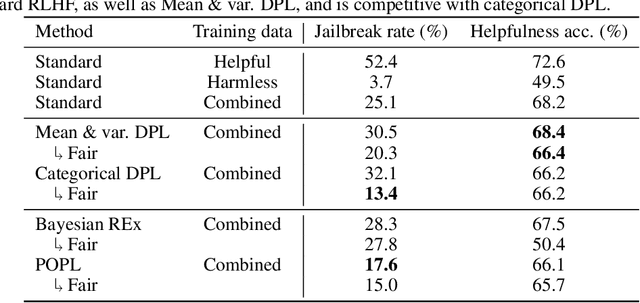
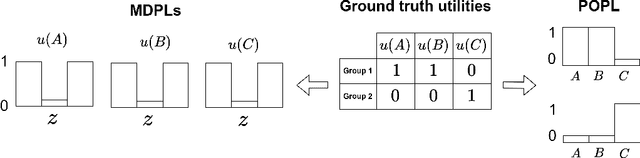
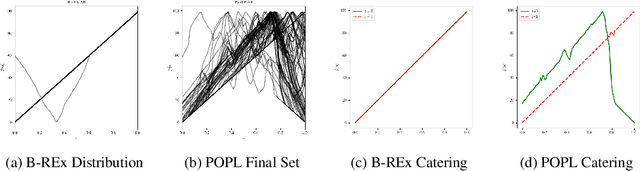
Ensuring AI models align with human values is essential for their safety and functionality. Reinforcement learning from human feedback (RLHF) uses human preferences to achieve this alignment. However, preferences sourced from diverse populations can result in point estimates of human values that may be sub-optimal or unfair to specific groups. We propose Pareto Optimal Preference Learning (POPL), which frames discrepant group preferences as objectives with potential trade-offs, aiming for policies that are Pareto-optimal on the preference dataset. POPL utilizes Lexicase selection, an iterative process to select diverse and Pareto-optimal solutions. Our empirical evaluations demonstrate that POPL surpasses baseline methods in learning sets of reward functions, effectively catering to distinct groups without access to group numbers or membership labels. Furthermore, we illustrate that POPL can serve as a foundation for techniques optimizing specific notions of group fairness, ensuring inclusive and equitable AI model alignment.
Leveraging Symbolic Regression for Heuristic Design in the Traveling Thief Problem
Apr 19, 2024The Traveling Thief Problem is an NP-hard combination of the well known traveling salesman and knapsack packing problems. In this paper, we use symbolic regression to learn useful features of near-optimal packing plans, which we then use to design efficient metaheuristic genetic algorithms for the traveling thief algorithm. By using symbolic regression again to initialize the metaheuristic GA with near-optimal individuals, we are able to design a fast, interpretable, and effective packing initialization scheme. Comparisons against previous initialization schemes validates our algorithm design.
DALex: Lexicase-like Selection via Diverse Aggregation
Jan 23, 2024



Lexicase selection has been shown to provide advantages over other selection algorithms in several areas of evolutionary computation and machine learning. In its standard form, lexicase selection filters a population or other collection based on randomly ordered training cases that are considered one at a time. This iterated filtering process can be time-consuming, particularly in settings with large numbers of training cases. In this paper, we propose a new method that is nearly equivalent to lexicase selection in terms of the individuals that it selects, but which does so significantly more quickly. The new method, called DALex (for Diversely Aggregated Lexicase), selects the best individual with respect to a weighted sum of training case errors, where the weights are randomly sampled. This allows us to formulate the core computation required for selection as matrix multiplication instead of recursive loops of comparisons, which in turn allows us to take advantage of optimized and parallel algorithms designed for matrix multiplication for speedup. Furthermore, we show that we can interpolate between the behavior of lexicase selection and its "relaxed" variants, such as epsilon or batch lexicase selection, by adjusting a single hyperparameter, named "particularity pressure," which represents the importance granted to each individual training case. Results on program synthesis, deep learning, symbolic regression, and learning classifier systems demonstrate that DALex achieves significant speedups over lexicase selection and its relaxed variants while maintaining almost identical problem-solving performance. Under a fixed computational budget, these savings free up resources that can be directed towards increasing population size or the number of generations, enabling the potential for solving more difficult problems.
Optimizing Neural Networks with Gradient Lexicase Selection
Dec 19, 2023



One potential drawback of using aggregated performance measurement in machine learning is that models may learn to accept higher errors on some training cases as compromises for lower errors on others, with the lower errors actually being instances of overfitting. This can lead to both stagnation at local optima and poor generalization. Lexicase selection is an uncompromising method developed in evolutionary computation, which selects models on the basis of sequences of individual training case errors instead of using aggregated metrics such as loss and accuracy. In this paper, we investigate how lexicase selection, in its general form, can be integrated into the context of deep learning to enhance generalization. We propose Gradient Lexicase Selection, an optimization framework that combines gradient descent and lexicase selection in an evolutionary fashion. Our experimental results demonstrate that the proposed method improves the generalization performance of various widely-used deep neural network architectures across three image classification benchmarks. Additionally, qualitative analysis suggests that our method assists networks in learning more diverse representations. Our source code is available on GitHub: https://github.com/ld-ing/gradient-lexicase.
* ICLR 2022
Objectives Are All You Need: Solving Deceptive Problems Without Explicit Diversity Maintenance
Nov 04, 2023Navigating deceptive domains has often been a challenge in machine learning due to search algorithms getting stuck at sub-optimal local optima. Many algorithms have been proposed to navigate these domains by explicitly maintaining diversity or equivalently promoting exploration, such as Novelty Search or other so-called Quality Diversity algorithms. In this paper, we present an approach with promise to solve deceptive domains without explicit diversity maintenance by optimizing a potentially large set of defined objectives. These objectives can be extracted directly from the environment by sub-aggregating the raw performance of individuals in a variety of ways. We use lexicase selection to optimize for these objectives as it has been shown to implicitly maintain population diversity. We compare this technique with a varying number of objectives to a commonly used quality diversity algorithm, MAP-Elites, on a set of discrete optimization as well as reinforcement learning domains with varying degrees of deception. We find that decomposing objectives into many objectives and optimizing them outperforms MAP-Elites on the deceptive domains that we explore. Furthermore, we find that this technique results in competitive performance on the diversity-focused metrics of QD-Score and Coverage, without explicitly optimizing for these things. Our ablation study shows that this technique is robust to different subaggregation techniques. However, when it comes to non-deceptive, or ``illumination" domains, quality diversity techniques generally outperform our objective-based framework with respect to exploration (but not exploitation), hinting at potential directions for future work.
Quality Diversity through Human Feedback
Oct 18, 2023



Reinforcement learning from human feedback (RLHF) has exhibited the potential to enhance the performance of foundation models for qualitative tasks. Despite its promise, its efficacy is often restricted when conceptualized merely as a mechanism to maximize learned reward models of averaged human preferences, especially in areas such as image generation which demand diverse model responses. Meanwhile, quality diversity (QD) algorithms, dedicated to seeking diverse, high-quality solutions, are often constrained by the dependency on manually defined diversity metrics. Interestingly, such limitations of RLHF and QD can be overcome by blending insights from both. This paper introduces Quality Diversity through Human Feedback (QDHF), which employs human feedback for inferring diversity metrics, expanding the applicability of QD algorithms. Empirical results reveal that QDHF outperforms existing QD methods regarding automatic diversity discovery, and matches the search capabilities of QD with human-constructed metrics. Notably, when deployed for a latent space illumination task, QDHF markedly enhances the diversity of images generated by a Diffusion model. The study concludes with an in-depth analysis of QDHF's sample efficiency and the quality of its derived diversity metrics, emphasizing its promise for enhancing exploration and diversity in optimization for complex, open-ended tasks.
Particularity
Jun 12, 2023We describe a design principle for adaptive systems under which adaptation is driven by particular challenges that the environment poses, as opposed to average or otherwise aggregated measures of performance over many challenges. We trace the development of this "particularity" approach from the use of lexicase selection in genetic programming to "particularist" approaches to other forms of machine learning and to the design of adaptive systems more generally.
Probabilistic Lexicase Selection
May 19, 2023



Lexicase selection is a widely used parent selection algorithm in genetic programming, known for its success in various task domains such as program synthesis, symbolic regression, and machine learning. Due to its non-parametric and recursive nature, calculating the probability of each individual being selected by lexicase selection has been proven to be an NP-hard problem, which discourages deeper theoretical understanding and practical improvements to the algorithm. In this work, we introduce probabilistic lexicase selection (plexicase selection), a novel parent selection algorithm that efficiently approximates the probability distribution of lexicase selection. Our method not only demonstrates superior problem-solving capabilities as a semantic-aware selection method, but also benefits from having a probabilistic representation of the selection process for enhanced efficiency and flexibility. Experiments are conducted in two prevalent domains in genetic programming: program synthesis and symbolic regression, using standard benchmarks including PSB and SRBench. The empirical results show that plexicase selection achieves state-of-the-art problem-solving performance that is competitive to the lexicase selection, and significantly outperforms lexicase selection in computation efficiency.
Can the Problem-Solving Benefits of Quality Diversity Be Obtained Without Explicit Diversity Maintenance?
May 12, 2023When using Quality Diversity (QD) optimization to solve hard exploration or deceptive search problems, we assume that diversity is extrinsically valuable. This means that diversity is important to help us reach an objective, but is not an objective in itself. Often, in these domains, practitioners benchmark their QD algorithms against single objective optimization frameworks. In this paper, we argue that the correct comparison should be made to \emph{multi-objective} optimization frameworks. This is because single objective optimization frameworks rely on the aggregation of sub-objectives, which could result in decreased information that is crucial for maintaining diverse populations automatically. In order to facilitate a fair comparison between quality diversity and multi-objective optimization, we present a method that utilizes dimensionality reduction to automatically determine a set of behavioral descriptors for an individual, as well as a set of objectives for an individual to solve. Using the former, one can generate solutions using standard quality diversity optimization techniques, and using the latter, one can generate solutions using standard multi-objective optimization techniques. This allows for a level comparison between these two classes of algorithms, without requiring domain and algorithm specific modifications to facilitate a comparison.