 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Parallelism for Multimodal Large Language Model Training
May 26, 2026Foundation model training is becoming multimodal, from post-training pipelines to large-scale pretraining. As modality coverage broadens, context windows grow, and encoder LLM scales diverge, a single LLM-centric TP/CP/PP/DP/EP layout increasingly limits throughput. This coupling forces encoders to inherit LLM-driven sharding and placement choices that can add communication, limit encoder parallelism, or constrain the LLM schedule; the mismatch is most pronounced at long contexts, where LLM context parallelism is needed for the fused multimodal sequence but encoder inputs remain bounded. We present heterogeneous parallelism for multimodal large language model training, an abstraction that lets modules in one end-to-end graph use independent layouts and rank placements, supporting colocated execution on shared GPUs and non-colocated execution on disjoint rank sets. The key challenge is preserving boundary tensor semantics across independent layouts: forward activations must be materialized for the destination layout, while backward gradients must be routed back to the source layout. We address this with boundary communicators that implement forward and backward layout transforms, plus scheduling extensions for both placement modes. We evaluate optimized homogeneous, colocated heterogeneous, and non-colocated heterogeneous configurations across multimodal workloads and GPU scales to characterize when added layout and placement freedom exposes a better operating point. Across this sweep, colocated heterogeneity improves TFLOPS/GPU by up to 49.3%, while non-colocated heterogeneity improves aggregate token throughput by up to 13.0% and TFLOPS/GPU by up to 9.6%. We validate loss convergence parity against homogeneous baselines and release the system as an open-source Megatron-LM extension.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
QiMeng-PRepair: Precise Code Repair via Edit-Aware Reward Optimization
Apr 07, 2026Large Language Models (LLMs) achieve strong program repair performance but often suffer from over-editing, where excessive modifications overwrite correct code and hinder bug localization. We systematically quantify its impact and introduce precise repair task, which maximizes reuse of correct code while fixing only buggy parts. Building on this insight, we propose PRepair, a framework that mitigates over-editing and improves repair accuracy. PRepair has two components: Self-Breaking, which generates diverse buggy programs via controlled bug injection and min-max sampling, and Self-Repairing, which trains models with Edit-Aware Group Relative Policy Optimization (EA-GRPO) using an edit-aware reward to encourage minimal yet correct edits. Experiments show that PRepair improves repair precision by up to 31.4% under $\mathrm{fix}_1@1$, a metric that jointly considers repair correctness and extent, and significantly increases decoding throughput when combined with speculative editing, demonstrating its potential for precise and practical code repair.
Efficient Reasoning with Balanced Thinking
Mar 19, 2026Large Reasoning Models (LRMs) have shown remarkable reasoning capabilities, yet they often suffer from overthinking, expending redundant computational steps on simple problems, or underthinking, failing to explore sufficient reasoning paths despite inherent capabilities. These issues lead to inefficiencies and potential inaccuracies, limiting practical deployment in resource-constrained settings. Existing methods to mitigate overthinking, such as suppressing reflective keywords or adjusting reasoning length, may inadvertently induce underthinking, compromising accuracy. Therefore, we propose ReBalance, a training-free framework that achieves efficient reasoning with balanced thinking. ReBalance leverages confidence as a continuous indicator of reasoning dynamics, identifying overthinking through high confidence variance and underthinking via consistent overconfidence. By aggregating hidden states from a small-scale dataset into reasoning mode prototypes, we compute a steering vector to guide LRMs' reasoning trajectories. A dynamic control function modulates this vector's strength and direction based on real-time confidence, pruning redundancy during overthinking, and promoting exploration during underthinking. Extensive experiments conducted on four models ranging from 0.5B to 32B, and across nine benchmarks in math reasoning, general question answering, and coding tasks demonstrate that ReBalance effectively reduces output redundancy while improving accuracy, offering a general, training-free, and plug-and-play strategy for efficient and robust LRM deployment. Project page and code are available at https://rebalance-ai.github.io .
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Model-Agnostic Sentiment Distribution Stability Analysis for Robust LLM-Generated Texts Detection
Aug 09, 2025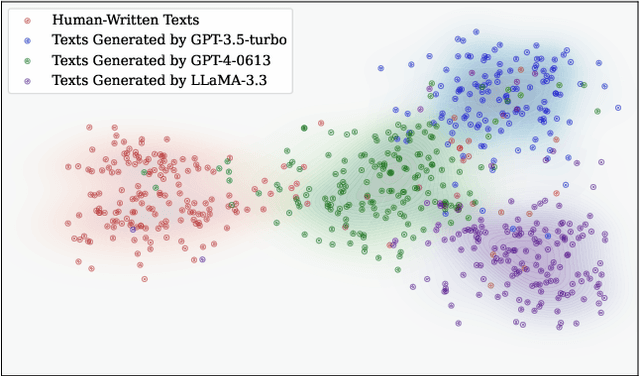

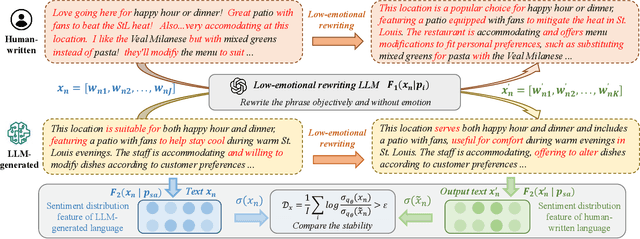

The rapid advancement of large language models (LLMs) has resulted in increasingly sophisticated AI-generated content, posing significant challenges in distinguishing LLM-generated text from human-written language. Existing detection methods, primarily based on lexical heuristics or fine-tuned classifiers, often suffer from limited generalizability and are vulnerable to paraphrasing, adversarial perturbations, and cross-domain shifts. In this work, we propose SentiDetect, a model-agnostic framework for detecting LLM-generated text by analyzing the divergence in sentiment distribution stability. Our method is motivated by the empirical observation that LLM outputs tend to exhibit emotionally consistent patterns, whereas human-written texts display greater emotional variability. To capture this phenomenon, we define two complementary metrics: sentiment distribution consistency and sentiment distribution preservation, which quantify stability under sentiment-altering and semantic-preserving transformations. We evaluate SentiDetect on five diverse datasets and a range of advanced LLMs,including Gemini-1.5-Pro, Claude-3, GPT-4-0613, and LLaMa-3.3. Experimental results demonstrate its superiority over state-of-the-art baselines, with over 16% and 11% F1 score improvements on Gemini-1.5-Pro and GPT-4-0613, respectively. Moreover, SentiDetect also shows greater robustness to paraphrasing, adversarial attacks, and text length variations, outperforming existing detectors in challenging scenarios.
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025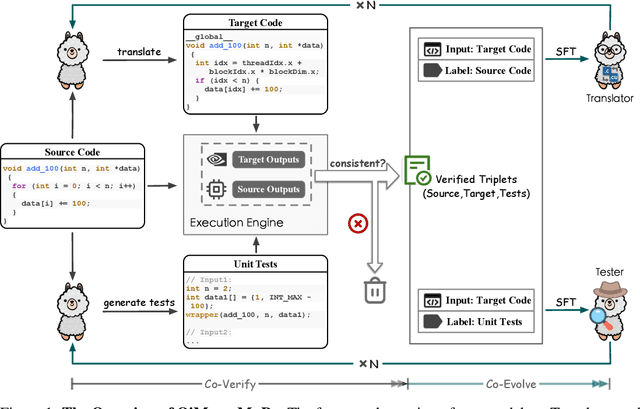
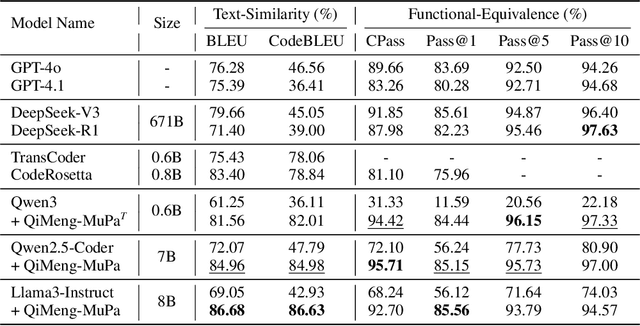
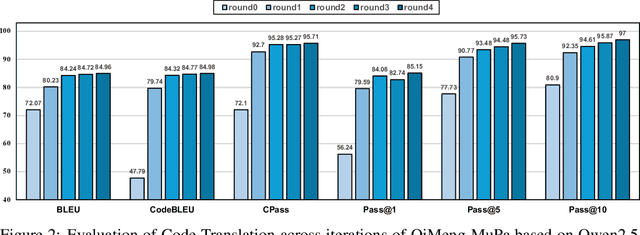
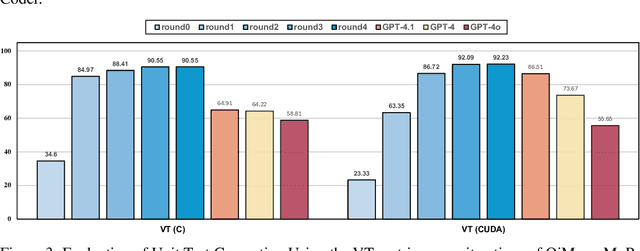
The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
Fast-Powerformer: A Memory-Efficient Transformer for Accurate Mid-Term Wind Power Forecasting
Apr 15, 2025



Wind power forecasting (WPF), as a significant research topic within renewable energy, plays a crucial role in enhancing the security, stability, and economic operation of power grids. However, due to the high stochasticity of meteorological factors (e.g., wind speed) and significant fluctuations in wind power output, mid-term wind power forecasting faces a dual challenge of maintaining high accuracy and computational efficiency. To address these issues, this paper proposes an efficient and lightweight mid-term wind power forecasting model, termed Fast-Powerformer. The proposed model is built upon the Reformer architecture, incorporating structural enhancements such as a lightweight Long Short-Term Memory (LSTM) embedding module, an input transposition mechanism, and a Frequency Enhanced Channel Attention Mechanism (FECAM). These improvements enable the model to strengthen temporal feature extraction, optimize dependency modeling across variables, significantly reduce computational complexity, and enhance sensitivity to periodic patterns and dominant frequency components. Experimental results conducted on multiple real-world wind farm datasets demonstrate that the proposed Fast-Powerformer achieves superior prediction accuracy and operational efficiency compared to mainstream forecasting approaches. Furthermore, the model exhibits fast inference speed and low memory consumption, highlighting its considerable practical value for real-world deployment scenarios.