 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
Apr 11, 2025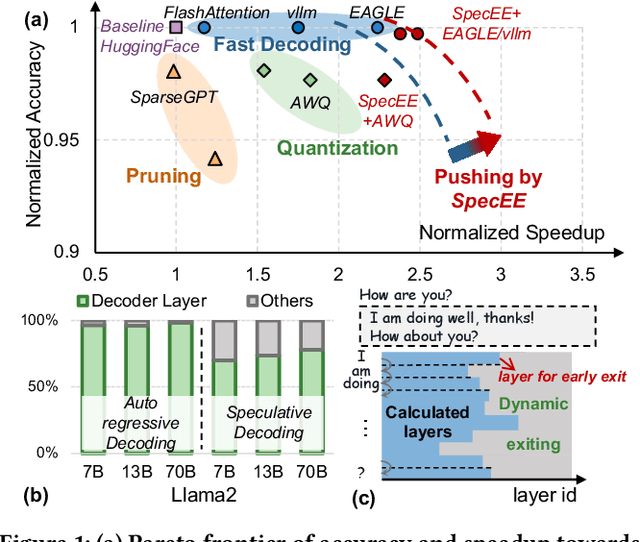
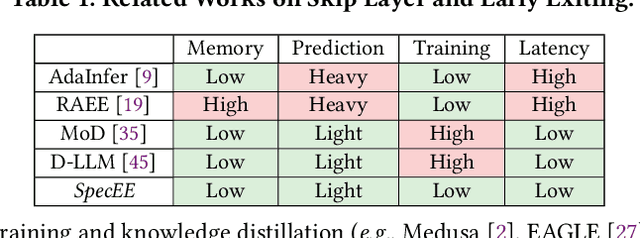
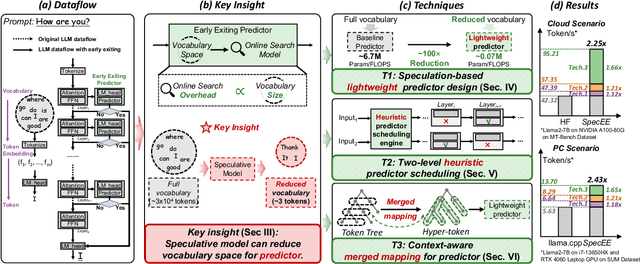
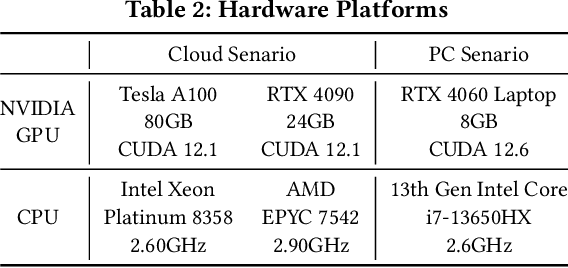
Early exiting has recently emerged as a promising technique for accelerating large language models (LLMs) by effectively reducing the hardware computation and memory access. In this paper, we present SpecEE, a fast LLM inference engine with speculative early exiting. (1) At the algorithm level, we propose the speculation-based lightweight predictor design by exploiting the probabilistic correlation between the speculative tokens and the correct results and high parallelism of GPUs. (2) At the system level, we point out that not all layers need a predictor and design the two-level heuristic predictor scheduling engine based on skewed distribution and contextual similarity. (3) At the mapping level, we point out that different decoding methods share the same essential characteristics, and propose the context-aware merged mapping for predictor with efficient GPU implementations to support speculative decoding, and form a framework for various existing orthogonal acceleration techniques (e.g., quantization and sparse activation) on cloud and personal computer (PC) scenarios, successfully pushing the Pareto frontier of accuracy and speedup. It is worth noting that SpecEE can be applied to any LLM by negligible training overhead in advance without affecting the model original parameters. Extensive experiments show that SpecEE achieves 2.25x and 2.43x speedup with Llama2-7B on cloud and PC scenarios respectively.
Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective
Oct 06, 2024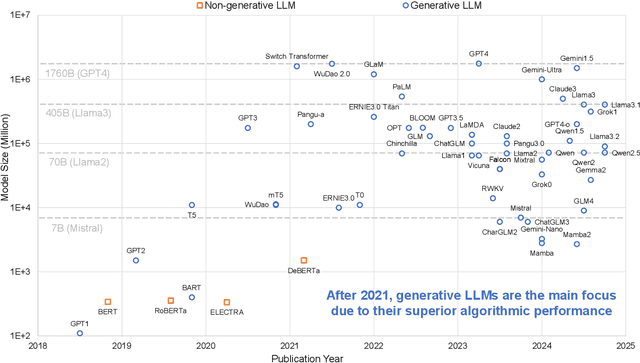
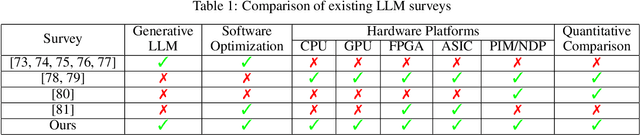
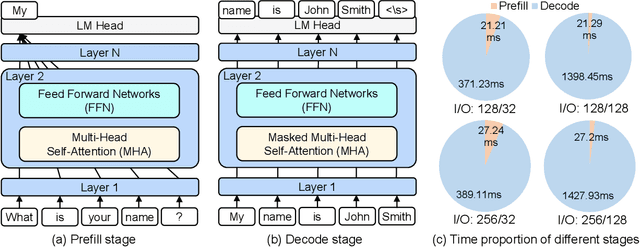
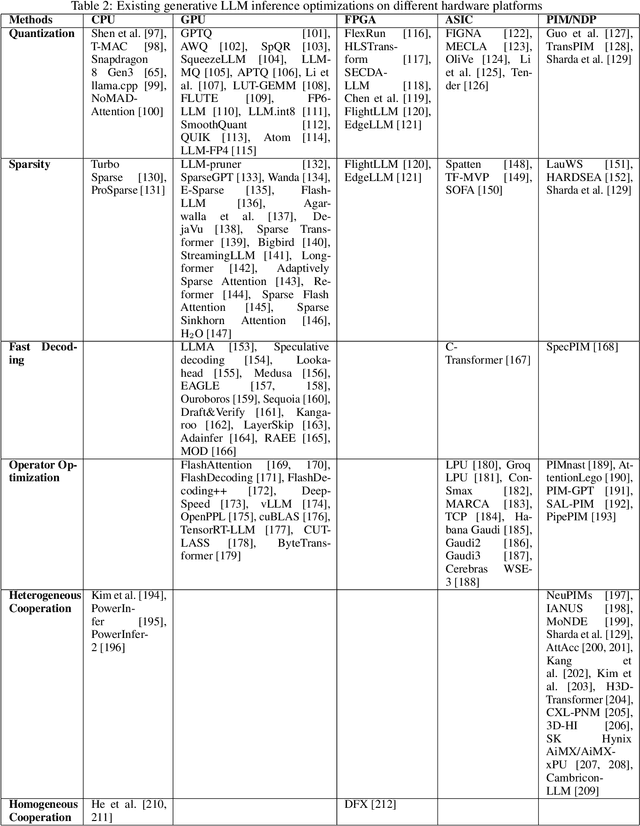
Large Language Models (LLMs) have demonstrated remarkable capabilities across various fields, from natural language understanding to text generation. Compared to non-generative LLMs like BERT and DeBERTa, generative LLMs like GPT series and Llama series are currently the main focus due to their superior algorithmic performance. The advancements in generative LLMs are closely intertwined with the development of hardware capabilities. Various hardware platforms exhibit distinct hardware characteristics, which can help improve LLM inference performance. Therefore, this paper comprehensively surveys efficient generative LLM inference on different hardware platforms. First, we provide an overview of the algorithm architecture of mainstream generative LLMs and delve into the inference process. Then, we summarize different optimization methods for different platforms such as CPU, GPU, FPGA, ASIC, and PIM/NDP, and provide inference results for generative LLMs. Furthermore, we perform a qualitative and quantitative comparison of inference performance with batch sizes 1 and 8 on different hardware platforms by considering hardware power consumption, absolute inference speed (tokens/s), and energy efficiency (tokens/J). We compare the performance of the same optimization methods across different hardware platforms, the performance across different hardware platforms, and the performance of different methods on the same hardware platform. This provides a systematic and comprehensive summary of existing inference acceleration work by integrating software optimization methods and hardware platforms, which can point to the future trends and potential developments of generative LLMs and hardware technology for edge-side scenarios.
Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization
Nov 28, 2023Large language models (LLMs) have demonstrated impressive abilities in various domains while the inference cost is expensive. The state-of-the-art methods use 2-bit quantization for mainstream LLMs. However, challenges still exist: (1) Nonnegligible accuracy loss for 2-bit quantization. Weights are quantized by groups, while the ranges of weights are large in some groups, resulting in large quantization errors and nonnegligible accuracy loss (e.g. >3% for Llama2-7b with 2-bit quantization in GPTQ and Greenbit). (2) Limited accuracy improvement by adding 4-bit weights. Increasing 10% extra average bit more 4-bit weights only leads to <0.5% accuracy improvement on a quantized Llama2-7b. (3) Time-consuming dequantization operations on GPUs. The dequantization operations lead to >50% execution time, hindering the potential of reducing LLM inference cost. To tackle these challenges, we propose the following techniques: (1) We only quantize a small fraction of groups with the larger range using 4-bit with memory alignment consideration on GPUs. (2) We point out that the distribution of the sparse outliers with larger weights is different in 2-bit and 4-bit groups, and only a small fraction of outliers require 16-bit quantization. Such design leads to >0.5% accuracy improvement with <3% average increased bit for Llama2-7b. (3) We design the asynchronous dequantization on GPUs, leading to up to 3.92X speedup. We conduct extensive experiments on different model families and model sizes. We achieve 2.85-bit for each weight and the end-to-end speedup for Llama2-7b is 1.74X over the original model, and we reduce both runtime cost and hardware cost by up to 2.70X and 2.81X with less GPU requirements.