 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIT-GS: LiDAR-Inertial-Thermal Gaussian Splatting for Illumination-Robust Mapping
Jun 18, 2026Gaussian Splatting has enabled real-time neural rendering, yet existing LiDAR-inertial-visual (LIV) Gaussian mapping pipelines remain fragile under illumination changes and texture-deficient scenes due to their reliance on RGB photometric cues. We present LIT-GS, a LiDAR-inertial-thermal Gaussian Splatting framework that injects LiDAR-derived plane geometry as an explicit constraint in both pose/structure refinement and Gaussian optimization. Specifically, we exploit LIV visual map points as confidence-aware cross-modal anchors to establish reliable thermal-LiDAR associations, and incorporate weighted LiDAR point-to-plane residuals into bundle adjustment to jointly refine camera poses and 3D points under weak thermal supervision. Building on the refined structure, we further introduce a LiDAR-plane-regularized differentiable splatting objective that constrains rendered 3D points to align with locally observed planes, mitigating surface thickening and structural drift in low-contrast thermal imagery. Experiments on proprietary sequences and public datasets demonstrate that LIT-GS consistently improves geometric accuracy and rendering quality over state-of-the-art LIV-based Gaussian Splatting baselines, particularly in challenging lighting conditions.
FAST-LIVGO: A Degeneracy-Robust LiDAR-Inertial-Visual-GNSS Fusion Odometry
Jun 17, 2026Robust state estimation and mapping in long-term, large-scale, and highly dynamic environments remains a key challenge in robotics. Existing LiDAR-Inertial-Visual Odometry (LIVO) systems achieve strong local accuracy but suffer from accumulated drift over long distances and may fail in geometrically degraded or textureless scenes. Meanwhile, GNSS-aided fusion frameworks often rely on LiDAR or visual odometry for state prediction and outlier rejection, making them vulnerable when odometry degenerates. To address these limitations, we propose a tightly coupled LiDAR-Inertial-Visual-GNSS fusion framework based on an Error-State Iterated Kalman Filter. An online spatiotemporal alignment module using Dynamic Time Warping is introduced for highly dynamic conditions. To better exploit GNSS precision, we develop observation models based on Doppler shifts and fixed-anchor Time-Differenced Carrier Phase, providing millimeter-level relative constraints without augmenting historical anchor states. We further design a degeneracy-aware dual-mode outlier rejection strategy that switches between LIVO-prior-guided rejection and GNSS-aided recovery according to the LIVO degeneracy level. Experiments on the public M3DGR dataset and a custom 20~m/s fixed-wing UAV dataset demonstrate that our system reduces accumulated drift and map ghosting, outperforming state-of-the-art methods in accuracy and robustness.
SB-RF: Schrödinger Bridge Rectified Flow for One-Step Robust Speech Enhancement
Jun 04, 2026Generative models have shown impressive results in speech enhancement but often suffer from multi-step inference. We propose SB-RF, a one-step generative framework integrating Rectified Flow (RF) with Schrödinger Bridge (SB) theory. SB-RF constructs a conditional bridge between clean and noisy speech distributions via entropy-regularized optimal transport. By aligning SB trajectories with the optimal transport geodesic through the velocity-matching objective of RF, SB-RF enables high-quality enhancement with one-step generation. Experiments demonstrate that SB-RF achieves leading performance among generative methods on the VoiceBank-DEMAND benchmark. Furthermore, to fully assess performance in challenging real-world scenarios, we evaluate SB-RF on a simulated low signal-to-noise ratio test set using an expanded training dataset. Under these conditions, SB-RF exhibits strong and competitive robustness with high efficiency, validating its potential for real-world applications.
Perceive Before Reasoning: A Pre-Reasoning Perception Framework for Efficient and Reliable Proactive Mobile Agents
Jun 02, 2026Multimodal large language models (MLLMs) have substantially advanced mobile agents, yet proactive mobile assistance remains challenging because agents must decide \emph{when} to intervene before determining \emph{how} to assist. Existing systems often implement these two decisions within a unified MLLM-based pipeline, leading to goal misalignment between conservative intervention filtering and comprehensive assistance generation, as well as redundant inference when the agent should remain silent. To address these limitations, we propose the \textbf{Pre-Reasoning Perception Framework (PRPF)}, a two-stage framework built on perceiving before reasoning. PRPF introduces a lightweight Multimodal Proactive Perceptor (MPP) for intervention gating and context compression, and activates the Proactive Agent Reasoner (PAR) only when intervention is warranted. Experiments on the ProactiveMobile benchmark show that PRPF substantially reduces false trigger rates (FTR) while improving success rates (SR) and inference efficiency over the ProactiveMobile baseline.
ProUIE: A Macro-to-Micro Progressive Learning Method for LLM-based Universal Information Extraction
Apr 12, 2026LLM-based universal information extraction (UIE) methods often rely on additional information beyond the original training data, which increases training complexity yet often yields limited gains. To address this, we propose ProUIE, a Macro-to-Micro progressive learning approach that improves UIE without introducing any external information. ProUIE consists of three stages: (i) macro-level Complete Modeling (CM), which learns NER, RE, and EE along their intrinsic difficulty order on the full training data to build a unified extraction foundation, (ii) meso-level Streamlined Alignment (SA), which operates on sampled data with simplified target formats, streamlining and regularizing structured outputs to make them more concise and controllable, and (iii) micro-level Deep Exploration (DE), which applies GRPO with stepwise fine-grained rewards (SFR) over structural units to guide exploration and improve performance. Experiments on 36 public datasets show that ProUIE consistently improves unified extraction, outperforming strong instruction-tuned baselines on average for NER and RE while using a smaller backbone, and it further demonstrates clear gains in large-scale production-oriented information extraction.
GUI-CEval: A Hierarchical and Comprehensive Chinese Benchmark for Mobile GUI Agents
Mar 16, 2026Recent progress in Multimodal Large Language Models (MLLMs) has enabled mobile GUI agents capable of visual perception, cross-modal reasoning, and interactive control. However, existing benchmarks are largely English-centric and fail to capture the linguistic and interaction characteristics of the Chinese mobile ecosystem. They also focus on isolated skills such as GUI grounding or offline agent, lacking a unified and fine-grained framework to assess the full capability chain from perception to execution. To address this gap, we introduce GUI-CEval, the first comprehensive benchmark for Chinese mobile GUI agents, built entirely on physical device environments. GUI-CEval spans 201 mainstream apps across four device types and adopts a two-level structure that evaluates both atomic abilities and realistic application-level performance along five dimensions: perception, planning, reflection, execution, and evaluation. All data are collected and verified through multi-stage manual processes to ensure authenticity and reproducibility. Extensive experiments on 20 representative MLLMs and multi-agent systems show that while models such as Qwen2.5-VL and UI-TARS perform competitively, most MLLMs still exhibit clear weaknesses in reflective decision-making and post-action self-evaluation, limiting their reliability in real-world interactions. We hope GUI-CEval provides a comprehensive and interpretable benchmark to guide capability diagnosis and advance the development of Chinese mobile GUI agents.
ProactiveMobile: A Comprehensive Benchmark for Boosting Proactive Intelligence on Mobile Devices
Feb 26, 2026Multimodal large language models (MLLMs) have made significant progress in mobile agent development, yet their capabilities are predominantly confined to a reactive paradigm, where they merely execute explicit user commands. The emerging paradigm of proactive intelligence, where agents autonomously anticipate needs and initiate actions, represents the next frontier for mobile agents. However, its development is critically bottlenecked by the lack of benchmarks that can address real-world complexity and enable objective, executable evaluation. To overcome these challenges, we introduce ProactiveMobile, a comprehensive benchmark designed to systematically advance research in this domain. ProactiveMobile formalizes the proactive task as inferring latent user intent across four dimensions of on-device contextual signals and generating an executable function sequence from a comprehensive function pool of 63 APIs. The benchmark features over 3,660 instances of 14 scenarios that embrace real-world complexity through multi-answer annotations. To ensure quality, a team of 30 experts conducts a final audit of the benchmark, verifying factual accuracy, logical consistency, and action feasibility, and correcting any non-compliant entries. Extensive experiments demonstrate that our fine-tuned Qwen2.5-VL-7B-Instruct achieves a success rate of 19.15%, outperforming o1 (15.71%) and GPT-5 (7.39%). This result indicates that proactivity is a critical competency widely lacking in current MLLMs, yet it is learnable, emphasizing the importance of the proposed benchmark for proactivity evaluation.
SSL: Sweet Spot Learning for Differentiated Guidance in Agentic Optimization
Jan 30, 2026Reinforcement learning with verifiable rewards has emerged as a powerful paradigm for training intelligent agents. However, existing methods typically employ binary rewards that fail to capture quality differences among trajectories achieving identical outcomes, thereby overlooking potential diversity within the solution space. Inspired by the ``sweet spot'' concept in tennis-the racket's core region that produces optimal hitting effects, we introduce \textbf{S}weet \textbf{S}pot \textbf{L}earning (\textbf{SSL}), a novel framework that provides differentiated guidance for agent optimization. SSL follows a simple yet effective principle: progressively amplified, tiered rewards guide policies toward the sweet-spot region of the solution space. This principle naturally adapts across diverse tasks: visual perception tasks leverage distance-tiered modeling to reward proximity, while complex reasoning tasks reward incremental progress toward promising solutions. We theoretically demonstrate that SSL preserves optimal solution ordering and enhances the gradient signal-to-noise ratio, thereby fostering more directed optimization. Extensive experiments across GUI perception, short/long-term planning, and complex reasoning tasks show consistent improvements over strong baselines on 12 benchmarks, achieving up to 2.5X sample efficiency gains and effective cross-task transferability. Our work establishes SSL as a general principle for training capable and robust agents.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025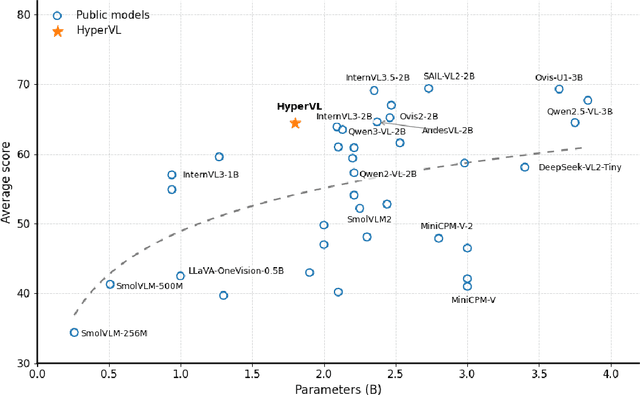

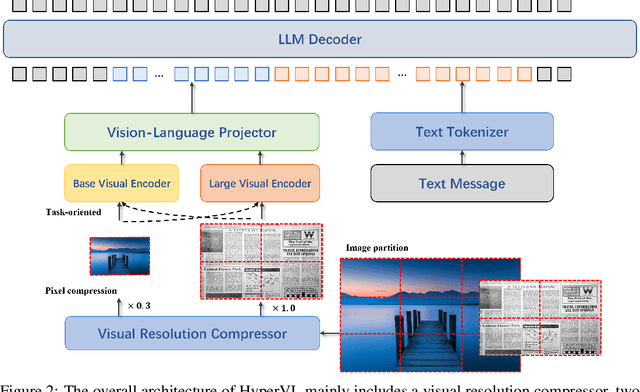

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.