 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Optimal Learning from Preferences with Hidden Context
Jun 21, 2024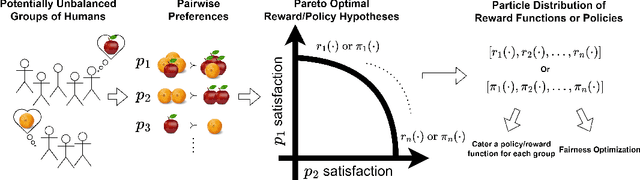
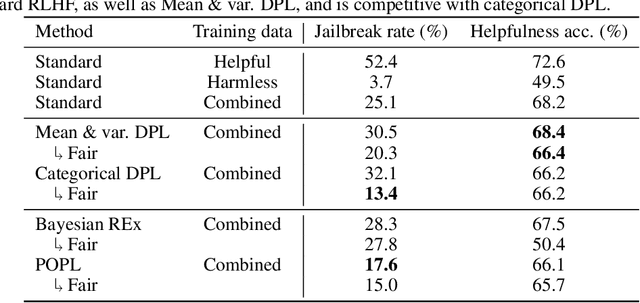
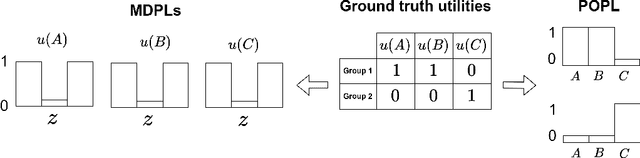
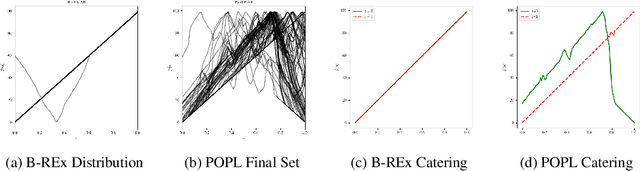
Ensuring AI models align with human values is essential for their safety and functionality. Reinforcement learning from human feedback (RLHF) uses human preferences to achieve this alignment. However, preferences sourced from diverse populations can result in point estimates of human values that may be sub-optimal or unfair to specific groups. We propose Pareto Optimal Preference Learning (POPL), which frames discrepant group preferences as objectives with potential trade-offs, aiming for policies that are Pareto-optimal on the preference dataset. POPL utilizes Lexicase selection, an iterative process to select diverse and Pareto-optimal solutions. Our empirical evaluations demonstrate that POPL surpasses baseline methods in learning sets of reward functions, effectively catering to distinct groups without access to group numbers or membership labels. Furthermore, we illustrate that POPL can serve as a foundation for techniques optimizing specific notions of group fairness, ensuring inclusive and equitable AI model alignment.
Objectives Are All You Need: Solving Deceptive Problems Without Explicit Diversity Maintenance
Nov 04, 2023Navigating deceptive domains has often been a challenge in machine learning due to search algorithms getting stuck at sub-optimal local optima. Many algorithms have been proposed to navigate these domains by explicitly maintaining diversity or equivalently promoting exploration, such as Novelty Search or other so-called Quality Diversity algorithms. In this paper, we present an approach with promise to solve deceptive domains without explicit diversity maintenance by optimizing a potentially large set of defined objectives. These objectives can be extracted directly from the environment by sub-aggregating the raw performance of individuals in a variety of ways. We use lexicase selection to optimize for these objectives as it has been shown to implicitly maintain population diversity. We compare this technique with a varying number of objectives to a commonly used quality diversity algorithm, MAP-Elites, on a set of discrete optimization as well as reinforcement learning domains with varying degrees of deception. We find that decomposing objectives into many objectives and optimizing them outperforms MAP-Elites on the deceptive domains that we explore. Furthermore, we find that this technique results in competitive performance on the diversity-focused metrics of QD-Score and Coverage, without explicitly optimizing for these things. Our ablation study shows that this technique is robust to different subaggregation techniques. However, when it comes to non-deceptive, or ``illumination" domains, quality diversity techniques generally outperform our objective-based framework with respect to exploration (but not exploitation), hinting at potential directions for future work.
Particularity
Jun 12, 2023We describe a design principle for adaptive systems under which adaptation is driven by particular challenges that the environment poses, as opposed to average or otherwise aggregated measures of performance over many challenges. We trace the development of this "particularity" approach from the use of lexicase selection in genetic programming to "particularist" approaches to other forms of machine learning and to the design of adaptive systems more generally.
Improving Recommendation System Serendipity Through Lexicase Selection
May 18, 2023
Recommender systems influence almost every aspect of our digital lives. Unfortunately, in striving to give us what we want, they end up restricting our open-mindedness. Current recommender systems promote echo chambers, where people only see the information they want to see, and homophily, where users of similar background see similar content. We propose a new serendipity metric to measure the presence of echo chambers and homophily in recommendation systems using cluster analysis. We then attempt to improve the diversity-preservation qualities of well known recommendation techniques by adopting a parent selection algorithm from the evolutionary computation literature known as lexicase selection. Our results show that lexicase selection, or a mixture of lexicase selection and ranking, outperforms its purely ranked counterparts in terms of personalization, coverage and our specifically designed serendipity benchmark, while only slightly under-performing in terms of accuracy (hit rate). We verify these results across a variety of recommendation list sizes. In this work we show that lexicase selection is able to maintain multiple diverse clusters of item recommendations that are each relevant for the specific user, while still maintaining a high hit-rate accuracy, a trade off that is not achieved by other methods.
Can the Problem-Solving Benefits of Quality Diversity Be Obtained Without Explicit Diversity Maintenance?
May 12, 2023When using Quality Diversity (QD) optimization to solve hard exploration or deceptive search problems, we assume that diversity is extrinsically valuable. This means that diversity is important to help us reach an objective, but is not an objective in itself. Often, in these domains, practitioners benchmark their QD algorithms against single objective optimization frameworks. In this paper, we argue that the correct comparison should be made to \emph{multi-objective} optimization frameworks. This is because single objective optimization frameworks rely on the aggregation of sub-objectives, which could result in decreased information that is crucial for maintaining diverse populations automatically. In order to facilitate a fair comparison between quality diversity and multi-objective optimization, we present a method that utilizes dimensionality reduction to automatically determine a set of behavioral descriptors for an individual, as well as a set of objectives for an individual to solve. Using the former, one can generate solutions using standard quality diversity optimization techniques, and using the latter, one can generate solutions using standard multi-objective optimization techniques. This allows for a level comparison between these two classes of algorithms, without requiring domain and algorithm specific modifications to facilitate a comparison.
A Static Analysis of Informed Down-Samples
Apr 17, 2023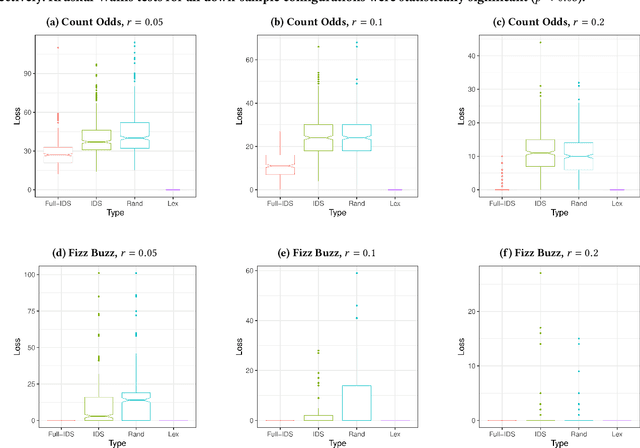
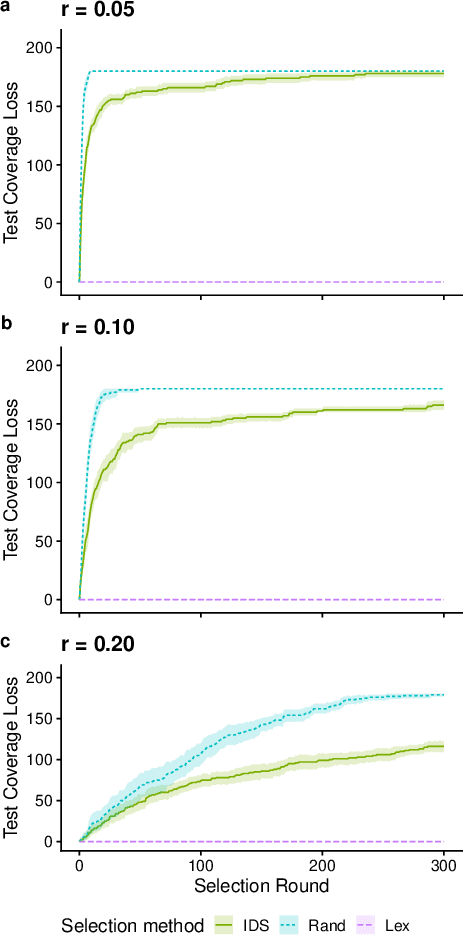
We present an analysis of the loss of population-level test coverage induced by different down-sampling strategies when combined with lexicase selection. We study recorded populations from the first generation of genetic programming runs, as well as entirely synthetic populations. Our findings verify the hypothesis that informed down-sampling better maintains population-level test coverage when compared to random down-sampling. Additionally, we show that both forms of down-sampling cause greater test coverage loss than standard lexicase selection with no down-sampling. However, given more information about the population, we found that informed down-sampling can further reduce its test coverage loss. We also recommend wider adoption of the static population analyses we present in this work.
Analyzing the Interaction Between Down-Sampling and Selection
Apr 14, 2023Genetic programming systems often use large training sets to evaluate the quality of candidate solutions for selection. However, evaluating populations on large training sets can be computationally expensive. Down-sampling training sets has long been used to decrease the computational cost of evaluation in a wide range of application domains. Indeed, recent studies have shown that both random and informed down-sampling can substantially improve problem-solving success for GP systems that use the lexicase parent selection algorithm. We use the PushGP framework to experimentally test whether these down-sampling techniques can also improve problem-solving success in the context of two other commonly used selection methods, fitness-proportionate and tournament selection, across eight GP problems (four program synthesis and four symbolic regression). We verified that down-sampling can benefit the problem-solving success of both fitness-proportionate and tournament selection. However, the number of problems wherein down-sampling improved problem-solving success varied by selection scheme, suggesting that the impact of down-sampling depends both on the problem and choice of selection scheme. Surprisingly, we found that down-sampling was most consistently beneficial when combined with lexicase selection as compared to tournament and fitness-proportionate selection. Overall, our results suggest that down-sampling should be considered more often when solving test-based GP problems.
Informed Down-Sampled Lexicase Selection: Identifying productive training cases for efficient problem solving
Jan 04, 2023



Genetic Programming (GP) often uses large training sets and requires all individuals to be evaluated on all training cases during selection. Random down-sampled lexicase selection evaluates individuals on only a random subset of the training cases allowing for more individuals to be explored with the same amount of program executions. However, creating a down-sample randomly might exclude important cases from the current down-sample for a number of generations, while cases that measure the same behavior (synonymous cases) may be overused despite their redundancy. In this work, we introduce Informed Down-Sampled Lexicase Selection. This method leverages population statistics to build down-samples that contain more distinct and therefore informative training cases. Through an empirical investigation across two different GP systems (PushGP and Grammar-Guided GP), we find that informed down-sampling significantly outperforms random down-sampling on a set of contemporary program synthesis benchmark problems. Through an analysis of the created down-samples, we find that important training cases are included in the down-sample consistently across independent evolutionary runs and systems. We hypothesize that this improvement can be attributed to the ability of Informed Down-Sampled Lexicase Selection to maintain more specialist individuals over the course of evolution, while also benefiting from reduced per-evaluation costs.
Lexicase Selection at Scale
Aug 23, 2022
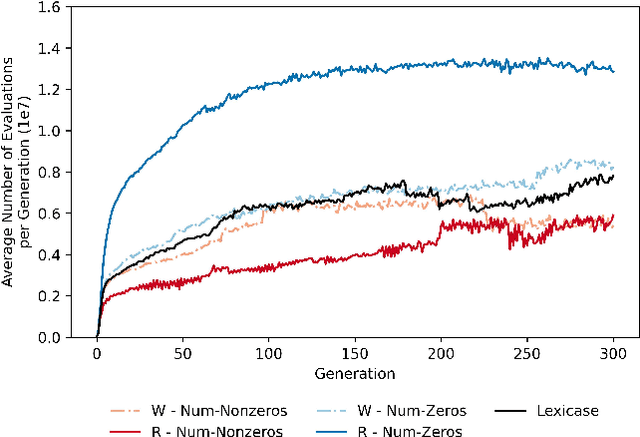

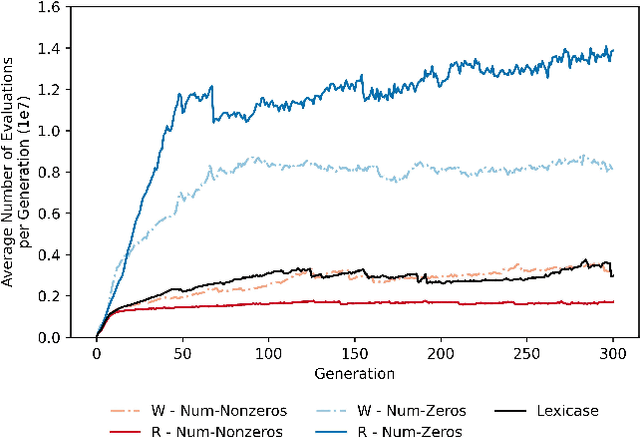
Lexicase selection is a semantic-aware parent selection method, which assesses individual test cases in a randomly-shuffled data stream. It has demonstrated success in multiple research areas including genetic programming, genetic algorithms, and more recently symbolic regression and deep learning. One potential drawback of lexicase selection and its variants is that the selection procedure requires evaluating training cases in a single data stream, making it difficult to handle tasks where the evaluation is computationally heavy or the dataset is large-scale, e.g., deep learning. In this work, we investigate how the weighted shuffle methods can be employed to improve the efficiency of lexicase selection. We propose a novel method, fast lexicase selection, which incorporates lexicase selection and weighted shuffle with partial evaluation. Experiments on both classic genetic programming and deep learning tasks indicate that the proposed method can significantly reduce the number of evaluation steps needed for lexicase selection to select an individual, improving its efficiency while maintaining the performance.
The Environmental Discontinuity Hypothesis for Down-Sampled Lexicase Selection
May 31, 2022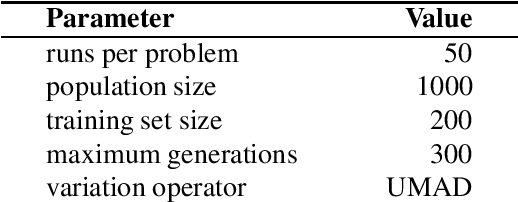
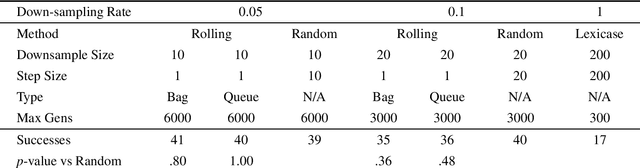
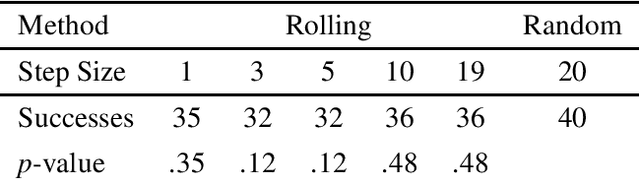
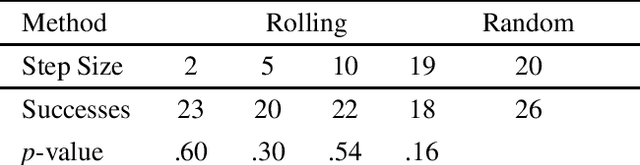
Down-sampling training data has long been shown to improve the generalization performance of a wide range of machine learning systems. Recently, down-sampling has proved effective in genetic programming (GP) runs that utilize the lexicase parent selection technique. Although this down-sampling procedure has been shown to significantly improve performance across a variety of problems, it does not seem to do so due to encouraging adaptability through environmental change. We hypothesize that the random sampling that is performed every generation causes discontinuities that result in the population being unable to adapt to the shifting environment. We investigate modifications to down-sampled lexicase selection in hopes of promoting incremental environmental change to scaffold evolution by reducing the amount of jarring discontinuities between the environments of successive generations. In our empirical studies, we find that forcing incremental environmental change is not significantly better for evolving solutions to program synthesis problems than simple random down-sampling. In response to this, we attempt to exacerbate the hypothesized prevalence of discontinuities by using only disjoint down-samples to see if it hinders performance. We find that this also does not significantly differ from the performance of regular random down-sampling. These negative results raise new questions about the ways in which the composition of sub-samples, which may include synonymous cases, may be expected to influence the performance of machine learning systems that use down-sampling.