 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexicase Selection at Scale
Paper and Code

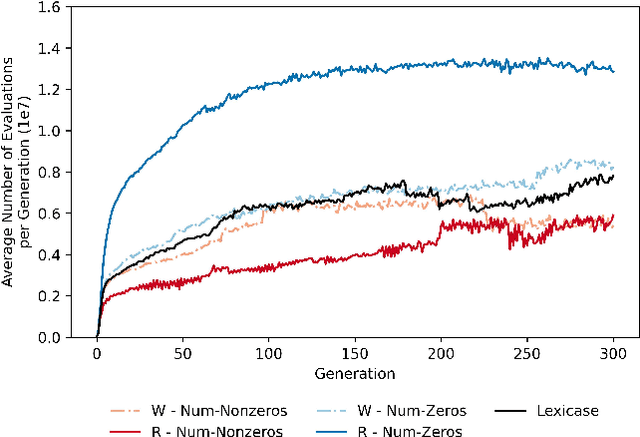

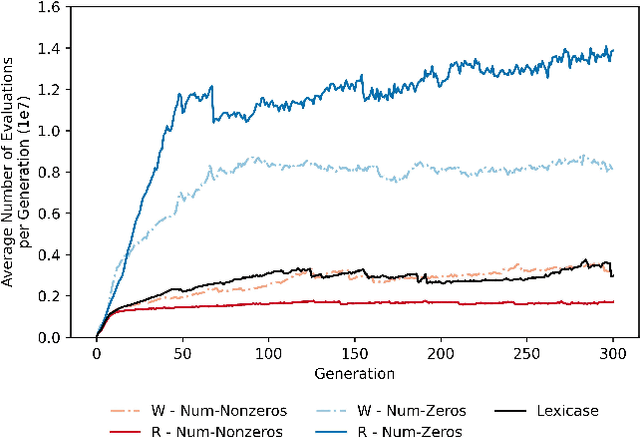
Lexicase selection is a semantic-aware parent selection method, which assesses individual test cases in a randomly-shuffled data stream. It has demonstrated success in multiple research areas including genetic programming, genetic algorithms, and more recently symbolic regression and deep learning. One potential drawback of lexicase selection and its variants is that the selection procedure requires evaluating training cases in a single data stream, making it difficult to handle tasks where the evaluation is computationally heavy or the dataset is large-scale, e.g., deep learning. In this work, we investigate how the weighted shuffle methods can be employed to improve the efficiency of lexicase selection. We propose a novel method, fast lexicase selection, which incorporates lexicase selection and weighted shuffle with partial evaluation. Experiments on both classic genetic programming and deep learning tasks indicate that the proposed method can significantly reduce the number of evaluation steps needed for lexicase selection to select an individual, improving its efficiency while maintaining the performance.