 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-based User Representation through Gaussian Process Regression for Multi-interest Personalized Retrieval
Nov 15, 2023Accurate modeling of the diverse and dynamic interests of users remains a significant challenge in the design of personalized recommender systems. Existing user modeling methods, like single-point and multi-point representations, have limitations w.r.t. accuracy, diversity, computational cost, and adaptability. To overcome these deficiencies, we introduce density-based user representations (DURs), a novel model that leverages Gaussian process regression for effective multi-interest recommendation and retrieval. Our approach, GPR4DUR, exploits DURs to capture user interest variability without manual tuning, incorporates uncertainty-awareness, and scales well to large numbers of users. Experiments using real-world offline datasets confirm the adaptability and efficiency of GPR4DUR, while online experiments with simulated users demonstrate its ability to address the exploration-exploitation trade-off by effectively utilizing model uncertainty.
Ever Evolving Evaluator (EV3): Towards Flexible and Reliable Meta-Optimization for Knowledge Distillation
Oct 29, 2023
We introduce EV3, a novel meta-optimization framework designed to efficiently train scalable machine learning models through an intuitive explore-assess-adapt protocol. In each iteration of EV3, we explore various model parameter updates, assess them using pertinent evaluation methods, and adapt the model based on the optimal updates and previous progress history. EV3 offers substantial flexibility without imposing stringent constraints like differentiability on the key objectives relevant to the tasks of interest. Moreover, this protocol welcomes updates with biased gradients and allows for the use of a diversity of losses and optimizers. Additionally, in scenarios with multiple objectives, it can be used to dynamically prioritize tasks. With inspiration drawn from evolutionary algorithms, meta-learning, and neural architecture search, we investigate an application of EV3 to knowledge distillation. Our experimental results illustrate EV3's capability to safely explore model spaces, while hinting at its potential applicability across numerous domains due to its inherent flexibility and adaptability.
Overcoming Prior Misspecification in Online Learning to Rank
Jan 26, 2023The recent literature on online learning to rank (LTR) has established the utility of prior knowledge to Bayesian ranking bandit algorithms. However, a major limitation of existing work is the requirement for the prior used by the algorithm to match the true prior. In this paper, we propose and analyze adaptive algorithms that address this issue and additionally extend these results to the linear and generalized linear models. We also consider scalar relevance feedback on top of click feedback. Moreover, we demonstrate the efficacy of our algorithms using both synthetic and real-world experiments.
Merge Double Thompson Sampling for Large Scale Online Ranker Evaluation
Dec 11, 2018
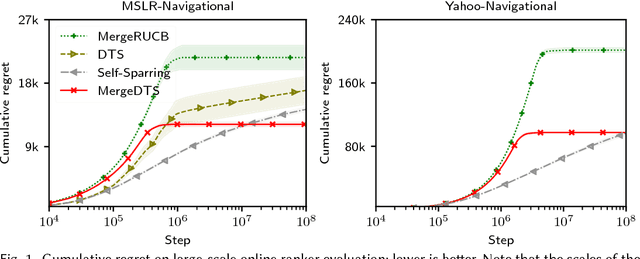
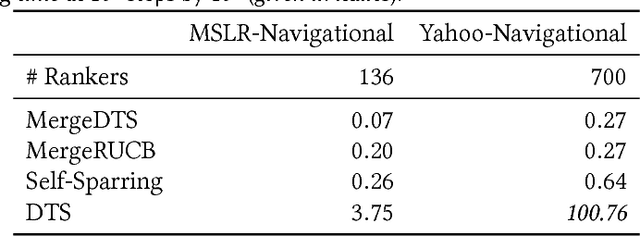
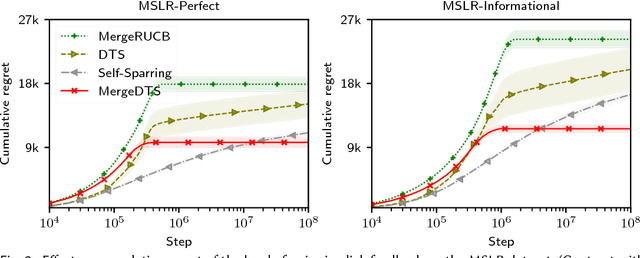
Online ranker evaluation is one of the key challenges in information retrieval. While the preferences of rankers can be inferred by interleaved comparison methods, how to effectively choose the pair of rankers to generate the result list without degrading the user experience too much can be formalized as a K-armed dueling bandit problem, which is an online partial-information learning framework, where feedback comes in the form of pair-wise preferences. A commercial search system may evaluate a large number of rankers concurrently, and scaling effectively in the presence of numerous rankers has not been fully studied. In this paper, we focus on solving the large-scale online ranker evaluation problem under the so-called Condorcet assumption, where there exists an optimal ranker that is preferred to all other rankers. We propose Merge Double Thompson Sampling (MergeDTS), which first utilizes a divide-and-conquer strategy that localizes the comparisons carried out by the algorithm to small batches of rankers, and then employs the Thompson Sampling (TS) to reduce the comparisons between suboptimal rankers inside these small batches. The effectiveness (regret) and efficiency (time complexity) of MergeDTS are extensively evaluated using examples from the domain of online evaluation for web search. Our main finding is that for large-scale Condorcet ranker evaluation problems MergeDTS outperforms the state-of-the-art dueling bandit algorithms.
BubbleRank: Safe Online Learning to Rerank
Jun 15, 2018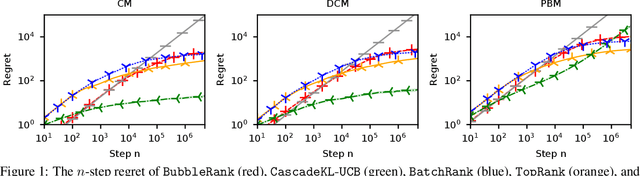
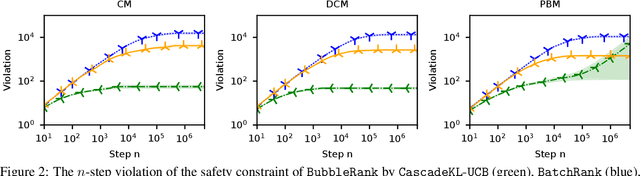
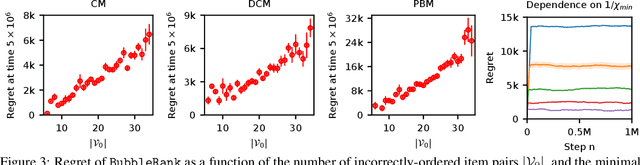
We study the problem of online learning to re-rank, where users provide feedback to improve the quality of displayed lists. Learning to rank has been traditionally studied in two settings. In the offline setting, rankers are typically learned from relevance labels of judges. These approaches have become the industry standard. However, they lack exploration, and thus are limited by the information content of offline data. In the online setting, an algorithm can propose a list and learn from the feedback on it in a sequential fashion. Bandit algorithms developed for this setting actively experiment, and in this way overcome the biases of offline data. But they also tend to ignore offline data, which results in a high initial cost of exploration. We propose BubbleRank, a bandit algorithm for re-ranking that combines the strengths of both settings. The algorithm starts with an initial base list and improves it gradually by swapping higher-ranked less attractive items for lower-ranked more attractive items. We prove an upper bound on the n-step regret of BubbleRank that degrades gracefully with the quality of the initial base list. Our theoretical findings are supported by extensive numerical experiments on a large real-world click dataset.
Online Learning to Rank in Stochastic Click Models
Jun 20, 2017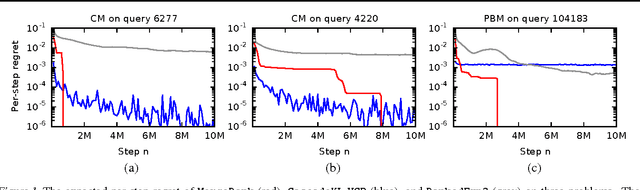
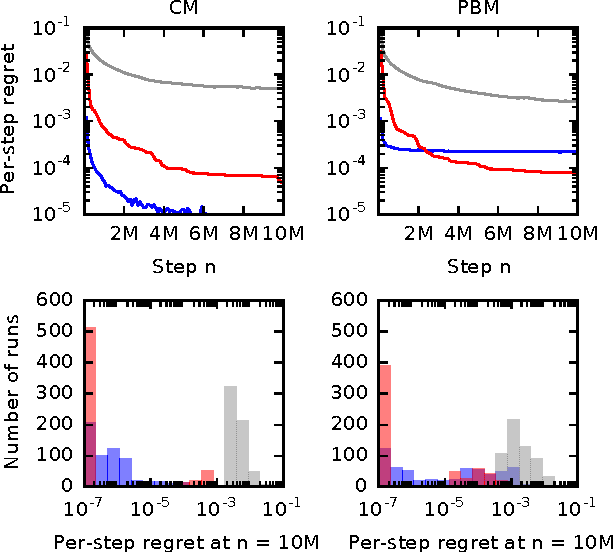
Online learning to rank is a core problem in information retrieval and machine learning. Many provably efficient algorithms have been recently proposed for this problem in specific click models. The click model is a model of how the user interacts with a list of documents. Though these results are significant, their impact on practice is limited, because all proposed algorithms are designed for specific click models and lack convergence guarantees in other models. In this work, we propose BatchRank, the first online learning to rank algorithm for a broad class of click models. The class encompasses two most fundamental click models, the cascade and position-based models. We derive a gap-dependent upper bound on the $T$-step regret of BatchRank and evaluate it on a range of web search queries. We observe that BatchRank outperforms ranked bandits and is more robust than CascadeKL-UCB, an existing algorithm for the cascade model.
Bayesian Optimization in a Billion Dimensions via Random Embeddings
Jan 10, 2016

Bayesian optimization techniques have been successfully applied to robotics, planning, sensor placement, recommendation, advertising, intelligent user interfaces and automatic algorithm configuration. Despite these successes, the approach is restricted to problems of moderate dimension, and several workshops on Bayesian optimization have identified its scaling to high-dimensions as one of the holy grails of the field. In this paper, we introduce a novel random embedding idea to attack this problem. The resulting Random EMbedding Bayesian Optimization (REMBO) algorithm is very simple, has important invariance properties, and applies to domains with both categorical and continuous variables. We present a thorough theoretical analysis of REMBO. Empirical results confirm that REMBO can effectively solve problems with billions of dimensions, provided the intrinsic dimensionality is low. They also show that REMBO achieves state-of-the-art performance in optimizing the 47 discrete parameters of a popular mixed integer linear programming solver.
Contextual Dueling Bandits
Jun 13, 2015
We consider the problem of learning to choose actions using contextual information when provided with limited feedback in the form of relative pairwise comparisons. We study this problem in the dueling-bandits framework of Yue et al. (2009), which we extend to incorporate context. Roughly, the learner's goal is to find the best policy, or way of behaving, in some space of policies, although "best" is not always so clearly defined. Here, we propose a new and natural solution concept, rooted in game theory, called a von Neumann winner, a randomized policy that beats or ties every other policy. We show that this notion overcomes important limitations of existing solutions, particularly the Condorcet winner which has typically been used in the past, but which requires strong and often unrealistic assumptions. We then present three efficient algorithms for online learning in our setting, and for approximating a von Neumann winner from batch-like data. The first of these algorithms achieves particularly low regret, even when data is adversarial, although its time and space requirements are linear in the size of the policy space. The other two algorithms require time and space only logarithmic in the size of the policy space when provided access to an oracle for solving classification problems on the space.
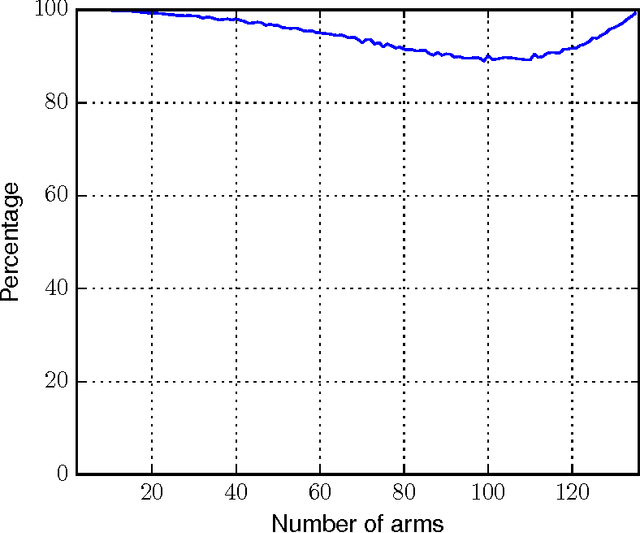
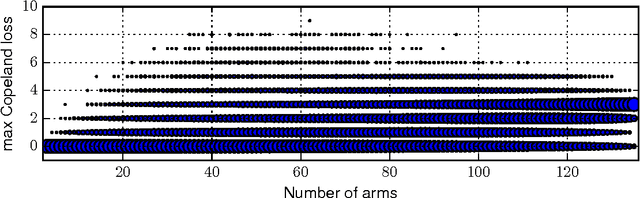
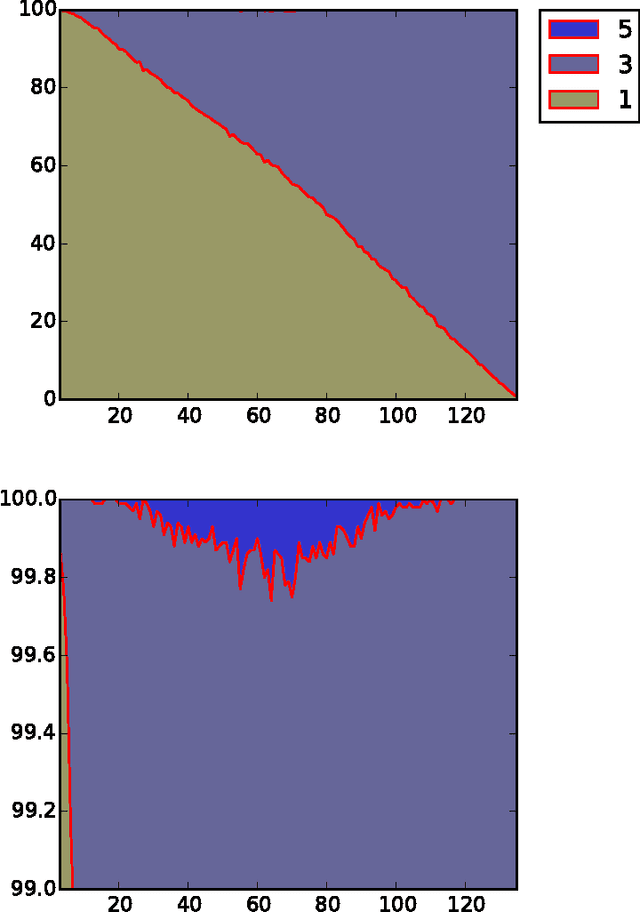
Copeland Dueling Bandits
Jun 01, 2015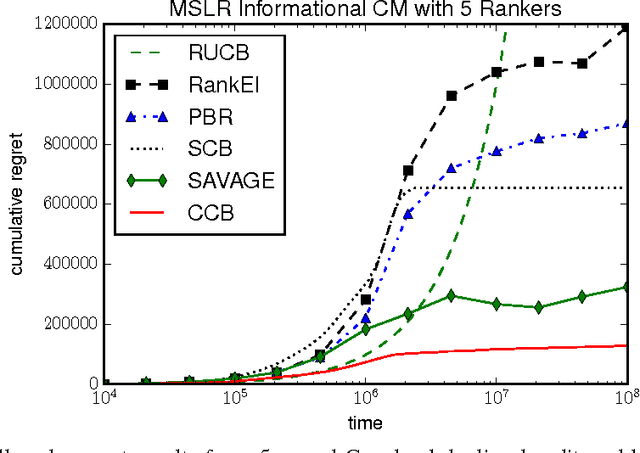
A version of the dueling bandit problem is addressed in which a Condorcet winner may not exist. Two algorithms are proposed that instead seek to minimize regret with respect to the Copeland winner, which, unlike the Condorcet winner, is guaranteed to exist. The first, Copeland Confidence Bound (CCB), is designed for small numbers of arms, while the second, Scalable Copeland Bandits (SCB), works better for large-scale problems. We provide theoretical results bounding the regret accumulated by CCB and SCB, both substantially improving existing results. Such existing results either offer bounds of the form $O(K \log T)$ but require restrictive assumptions, or offer bounds of the form $O(K^2 \log T)$ without requiring such assumptions. Our results offer the best of both worlds: $O(K \log T)$ bounds without restrictive assumptions.
Relative Upper Confidence Bound for the K-Armed Dueling Bandit Problem
Dec 17, 2013
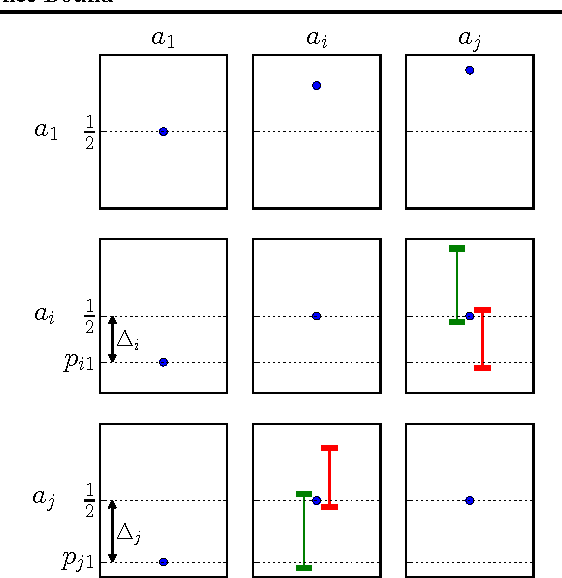
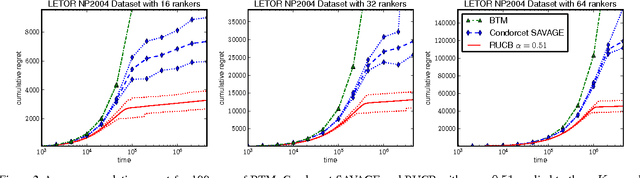
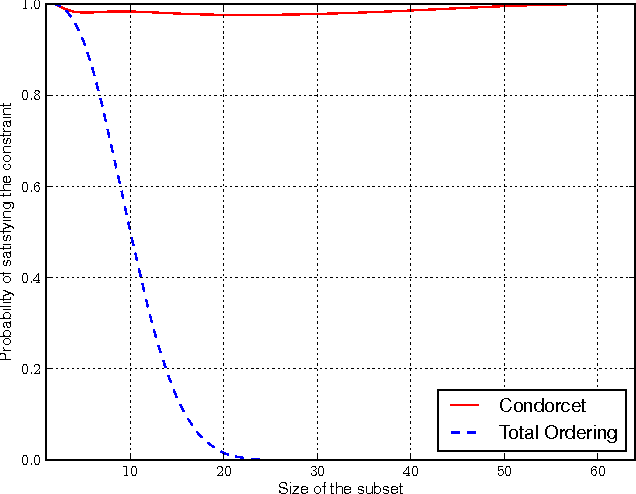
This paper proposes a new method for the K-armed dueling bandit problem, a variation on the regular K-armed bandit problem that offers only relative feedback about pairs of arms. Our approach extends the Upper Confidence Bound algorithm to the relative setting by using estimates of the pairwise probabilities to select a promising arm and applying Upper Confidence Bound with the winner as a benchmark. We prove a finite-time regret bound of order O(log t). In addition, our empirical results using real data from an information retrieval application show that it greatly outperforms the state of the art.