 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBubbleRank: Safe Online Learning to Rerank
Paper and Code
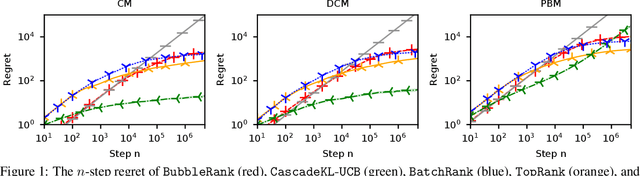
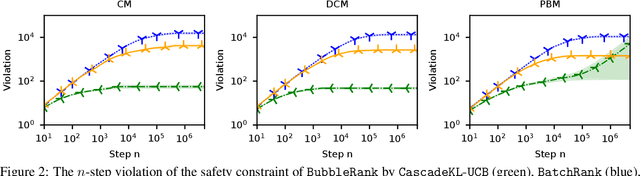
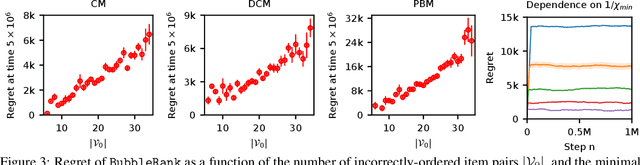
We study the problem of online learning to re-rank, where users provide feedback to improve the quality of displayed lists. Learning to rank has been traditionally studied in two settings. In the offline setting, rankers are typically learned from relevance labels of judges. These approaches have become the industry standard. However, they lack exploration, and thus are limited by the information content of offline data. In the online setting, an algorithm can propose a list and learn from the feedback on it in a sequential fashion. Bandit algorithms developed for this setting actively experiment, and in this way overcome the biases of offline data. But they also tend to ignore offline data, which results in a high initial cost of exploration. We propose BubbleRank, a bandit algorithm for re-ranking that combines the strengths of both settings. The algorithm starts with an initial base list and improves it gradually by swapping higher-ranked less attractive items for lower-ranked more attractive items. We prove an upper bound on the n-step regret of BubbleRank that degrades gracefully with the quality of the initial base list. Our theoretical findings are supported by extensive numerical experiments on a large real-world click dataset.