 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Neural Operators through Multiphysics Pretraining
Nov 13, 2025


Although neural operators are widely used in data-driven physical simulations, their training remains computationally expensive. Recent advances address this issue via downstream learning, where a model pretrained on simpler problems is fine-tuned on more complex ones. In this research, we investigate transformer-based neural operators, which have previously been applied only to specific problems, in a more general transfer learning setting. We evaluate their performance across diverse PDE problems, including extrapolation to unseen parameters, incorporation of new variables, and transfer from multi-equation datasets. Our results demonstrate that advanced neural operator architectures can effectively transfer knowledge across PDE problems.
Towards stable real-world equation discovery with assessing differentiating quality influence
Nov 09, 2023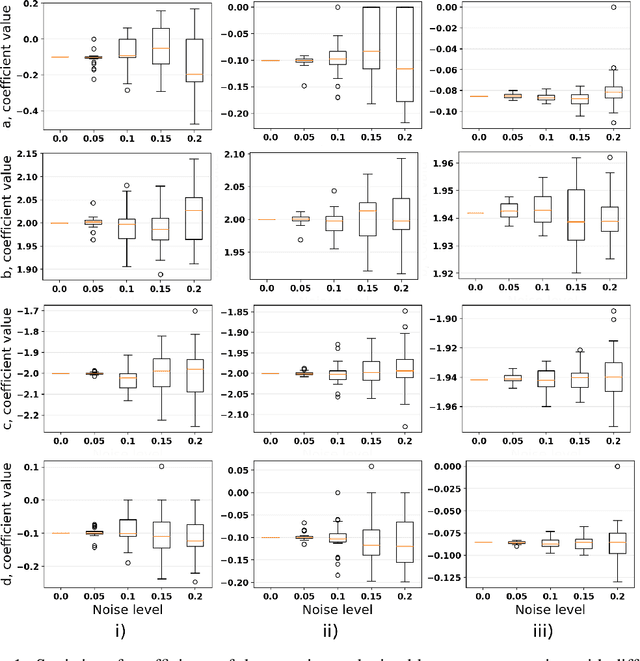
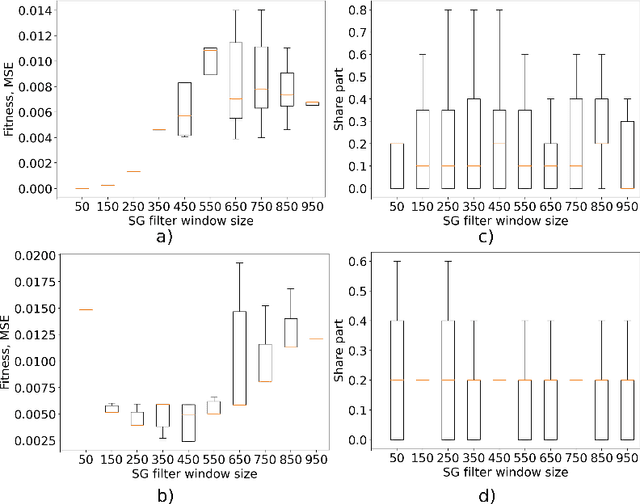
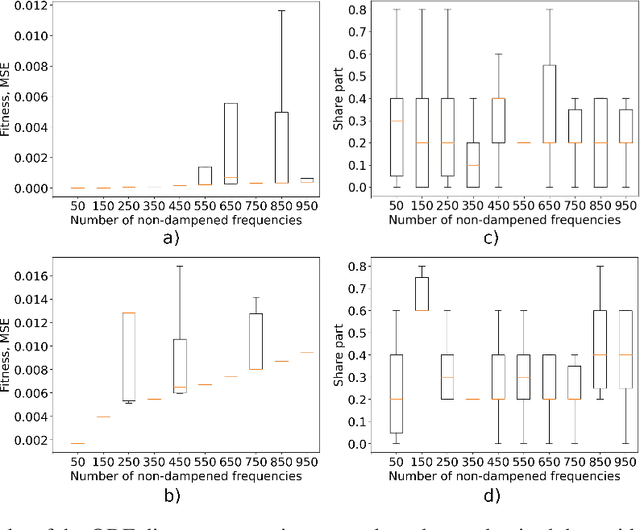
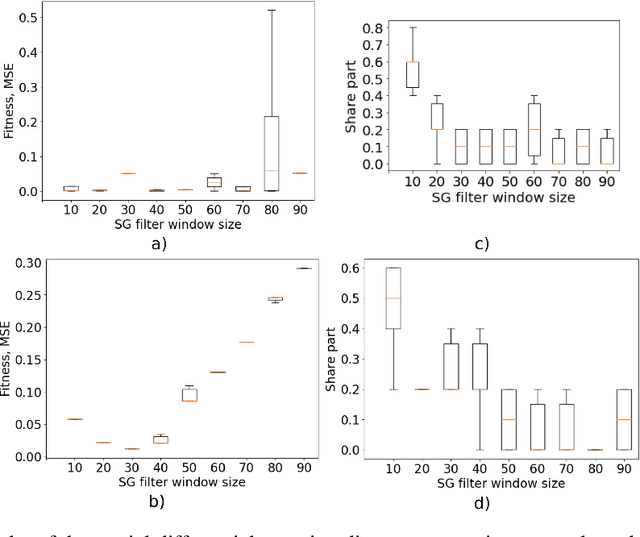
This paper explores the critical role of differentiation approaches for data-driven differential equation discovery. Accurate derivatives of the input data are essential for reliable algorithmic operation, particularly in real-world scenarios where measurement quality is inevitably compromised. We propose alternatives to the commonly used finite differences-based method, notorious for its instability in the presence of noise, which can exacerbate random errors in the data. Our analysis covers four distinct methods: Savitzky-Golay filtering, spectral differentiation, smoothing based on artificial neural networks, and the regularization of derivative variation. We evaluate these methods in terms of applicability to problems, similar to the real ones, and their ability to ensure the convergence of equation discovery algorithms, providing valuable insights for robust modeling of real-world processes.
Mixture-Based Correction for Position and Trust Bias in Counterfactual Learning to Rank
Aug 19, 2021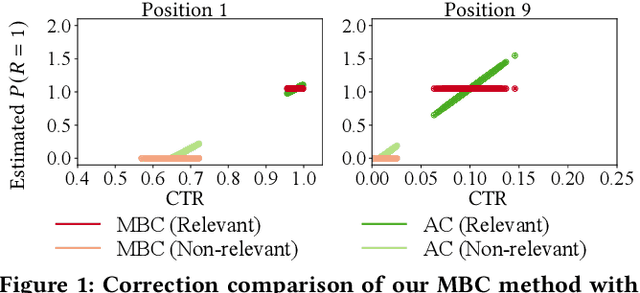
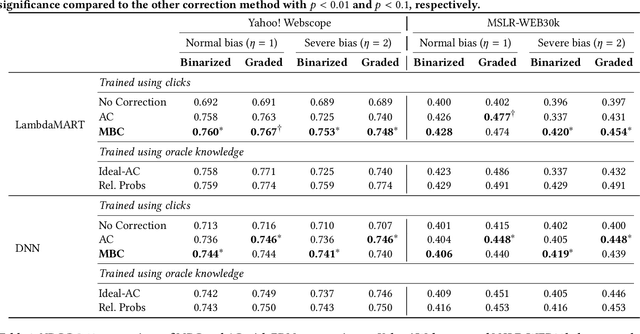
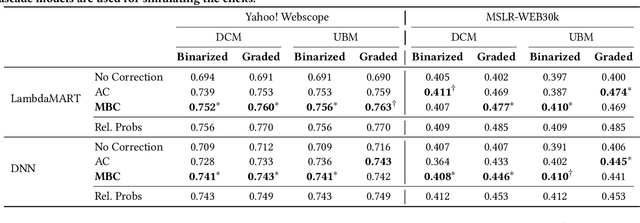
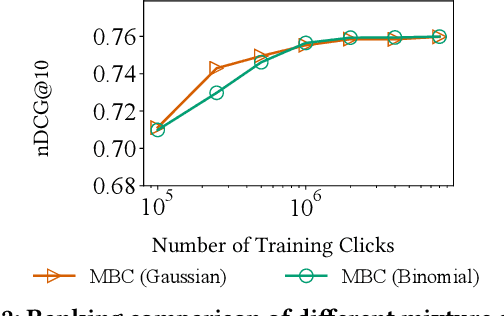
In counterfactual learning to rank (CLTR) user interactions are used as a source of supervision. Since user interactions come with bias, an important focus of research in this field lies in developing methods to correct for the bias of interactions. Inverse propensity scoring (IPS) is a popular method suitable for correcting position bias. Affine correction (AC) is a generalization of IPS that corrects for position bias and trust bias. IPS and AC provably remove bias, conditioned on an accurate estimation of the bias parameters. Estimating the bias parameters, in turn, requires an accurate estimation of the relevance probabilities. This cyclic dependency introduces practical limitations in terms of sensitivity, convergence and efficiency. We propose a new correction method for position and trust bias in CLTR in which, unlike the existing methods, the correction does not rely on relevance estimation. Our proposed method, mixture-based correction (MBC), is based on the assumption that the distribution of the CTRs over the items being ranked is a mixture of two distributions: the distribution of CTRs for relevant items and the distribution of CTRs for non-relevant items. We prove that our method is unbiased. The validity of our proof is not conditioned on accurate bias parameter estimation. Our experiments show that MBC, when used in different bias settings and accompanied by different LTR algorithms, outperforms AC, the state-of-the-art method for correcting position and trust bias, in some settings, while performing on par in other settings. Furthermore, MBC is orders of magnitude more efficient than AC in terms of the training time.
NUQSGD: Provably Communication-efficient Data-parallel SGD via Nonuniform Quantization
May 01, 2021

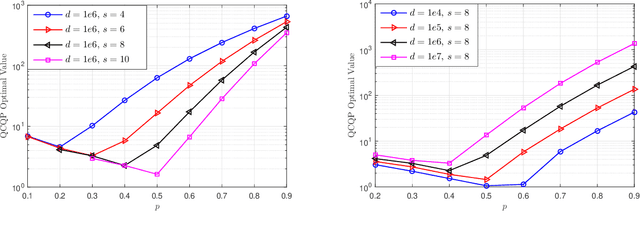
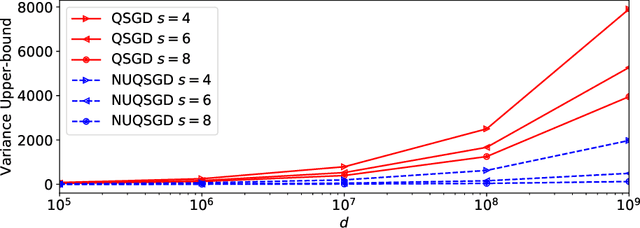
As the size and complexity of models and datasets grow, so does the need for communication-efficient variants of stochastic gradient descent that can be deployed to perform parallel model training. One popular communication-compression method for data-parallel SGD is QSGD (Alistarh et al., 2017), which quantizes and encodes gradients to reduce communication costs. The baseline variant of QSGD provides strong theoretical guarantees, however, for practical purposes, the authors proposed a heuristic variant which we call QSGDinf, which demonstrated impressive empirical gains for distributed training of large neural networks. In this paper, we build on this work to propose a new gradient quantization scheme, and show that it has both stronger theoretical guarantees than QSGD, and matches and exceeds the empirical performance of the QSGDinf heuristic and of other compression methods.
Safe Exploration for Optimizing Contextual Bandits
Feb 02, 2020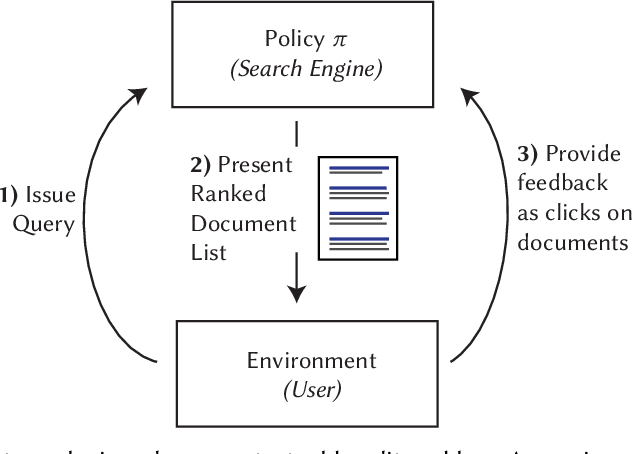
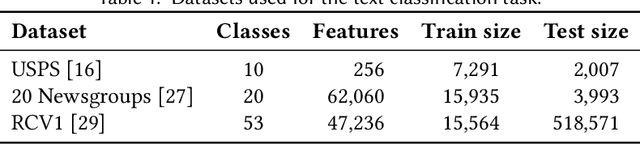
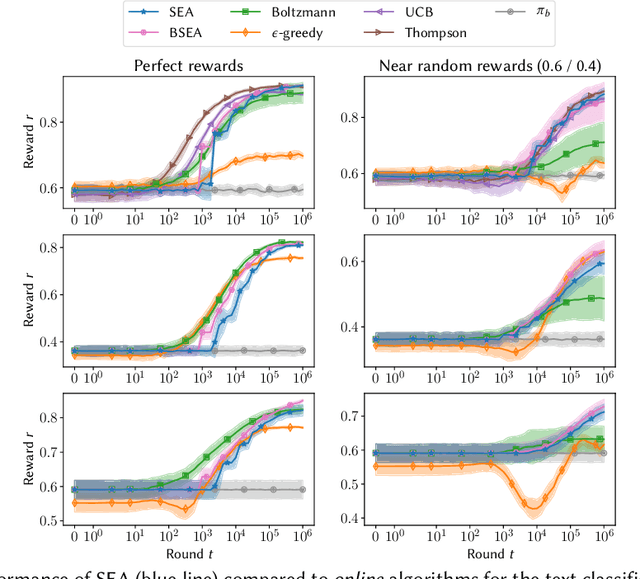
Contextual bandit problems are a natural fit for many information retrieval tasks, such as learning to rank, text classification, recommendation, etc. However, existing learning methods for contextual bandit problems have one of two drawbacks: they either do not explore the space of all possible document rankings (i.e., actions) and, thus, may miss the optimal ranking, or they present suboptimal rankings to a user and, thus, may harm the user experience. We introduce a new learning method for contextual bandit problems, Safe Exploration Algorithm (SEA), which overcomes the above drawbacks. SEA starts by using a baseline (or production) ranking system (i.e., policy), which does not harm the user experience and, thus, is safe to execute, but has suboptimal performance and, thus, needs to be improved. Then SEA uses counterfactual learning to learn a new policy based on the behavior of the baseline policy. SEA also uses high-confidence off-policy evaluation to estimate the performance of the newly learned policy. Once the performance of the newly learned policy is at least as good as the performance of the baseline policy, SEA starts using the new policy to execute new actions, allowing it to actively explore favorable regions of the action space. This way, SEA never performs worse than the baseline policy and, thus, does not harm the user experience, while still exploring the action space and, thus, being able to find an optimal policy. Our experiments using text classification and document retrieval confirm the above by comparing SEA (and a boundless variant called BSEA) to online and offline learning methods for contextual bandit problems.
Merge Double Thompson Sampling for Large Scale Online Ranker Evaluation
Dec 11, 2018
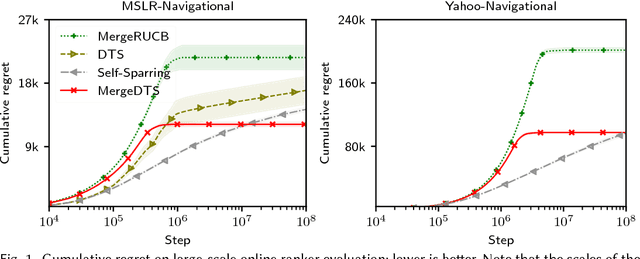
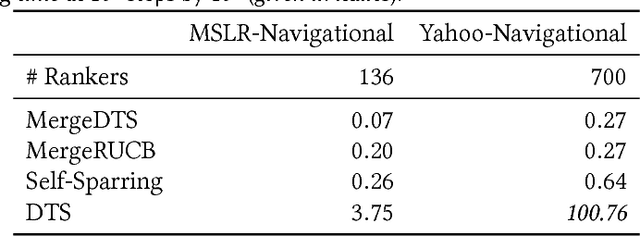
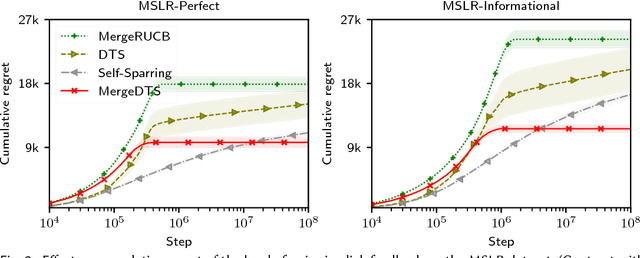
Online ranker evaluation is one of the key challenges in information retrieval. While the preferences of rankers can be inferred by interleaved comparison methods, how to effectively choose the pair of rankers to generate the result list without degrading the user experience too much can be formalized as a K-armed dueling bandit problem, which is an online partial-information learning framework, where feedback comes in the form of pair-wise preferences. A commercial search system may evaluate a large number of rankers concurrently, and scaling effectively in the presence of numerous rankers has not been fully studied. In this paper, we focus on solving the large-scale online ranker evaluation problem under the so-called Condorcet assumption, where there exists an optimal ranker that is preferred to all other rankers. We propose Merge Double Thompson Sampling (MergeDTS), which first utilizes a divide-and-conquer strategy that localizes the comparisons carried out by the algorithm to small batches of rankers, and then employs the Thompson Sampling (TS) to reduce the comparisons between suboptimal rankers inside these small batches. The effectiveness (regret) and efficiency (time complexity) of MergeDTS are extensively evaluated using examples from the domain of online evaluation for web search. Our main finding is that for large-scale Condorcet ranker evaluation problems MergeDTS outperforms the state-of-the-art dueling bandit algorithms.
BubbleRank: Safe Online Learning to Rerank
Jun 15, 2018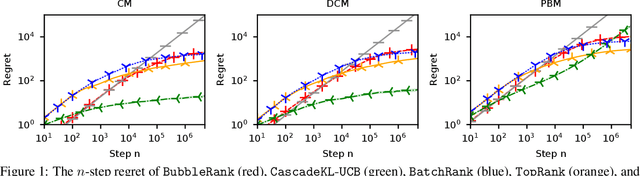
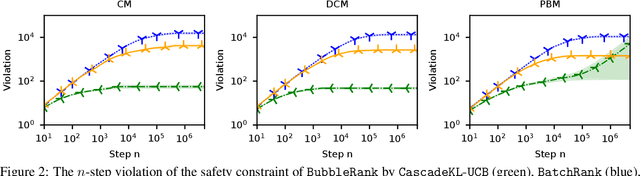
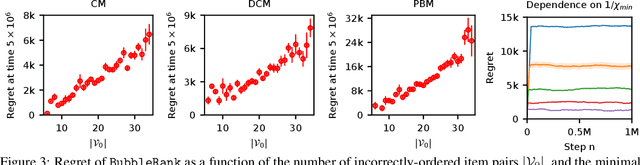
We study the problem of online learning to re-rank, where users provide feedback to improve the quality of displayed lists. Learning to rank has been traditionally studied in two settings. In the offline setting, rankers are typically learned from relevance labels of judges. These approaches have become the industry standard. However, they lack exploration, and thus are limited by the information content of offline data. In the online setting, an algorithm can propose a list and learn from the feedback on it in a sequential fashion. Bandit algorithms developed for this setting actively experiment, and in this way overcome the biases of offline data. But they also tend to ignore offline data, which results in a high initial cost of exploration. We propose BubbleRank, a bandit algorithm for re-ranking that combines the strengths of both settings. The algorithm starts with an initial base list and improves it gradually by swapping higher-ranked less attractive items for lower-ranked more attractive items. We prove an upper bound on the n-step regret of BubbleRank that degrades gracefully with the quality of the initial base list. Our theoretical findings are supported by extensive numerical experiments on a large real-world click dataset.