 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration for Optimizing Contextual Bandits
Paper and Code
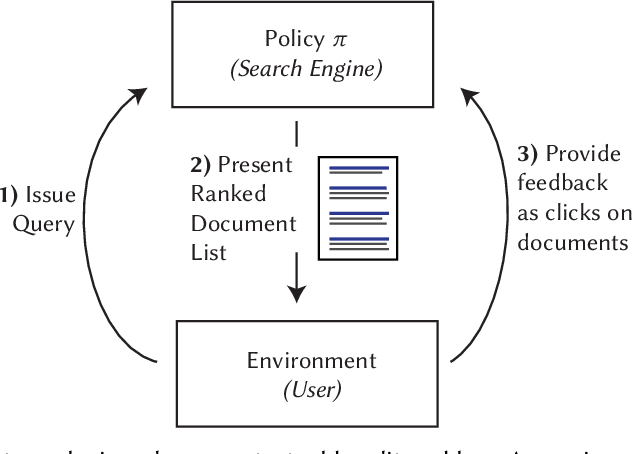
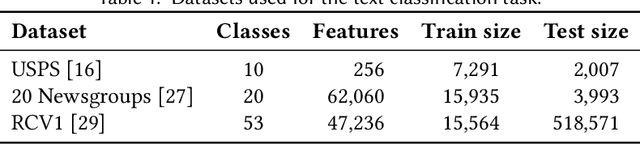
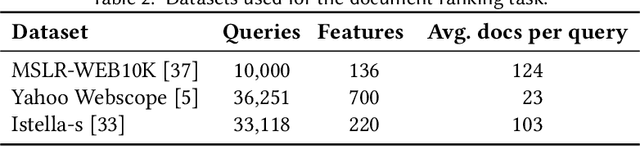
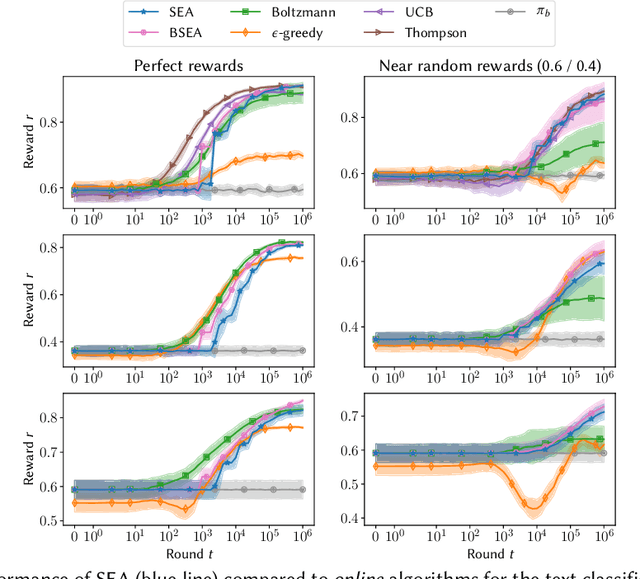
Contextual bandit problems are a natural fit for many information retrieval tasks, such as learning to rank, text classification, recommendation, etc. However, existing learning methods for contextual bandit problems have one of two drawbacks: they either do not explore the space of all possible document rankings (i.e., actions) and, thus, may miss the optimal ranking, or they present suboptimal rankings to a user and, thus, may harm the user experience. We introduce a new learning method for contextual bandit problems, Safe Exploration Algorithm (SEA), which overcomes the above drawbacks. SEA starts by using a baseline (or production) ranking system (i.e., policy), which does not harm the user experience and, thus, is safe to execute, but has suboptimal performance and, thus, needs to be improved. Then SEA uses counterfactual learning to learn a new policy based on the behavior of the baseline policy. SEA also uses high-confidence off-policy evaluation to estimate the performance of the newly learned policy. Once the performance of the newly learned policy is at least as good as the performance of the baseline policy, SEA starts using the new policy to execute new actions, allowing it to actively explore favorable regions of the action space. This way, SEA never performs worse than the baseline policy and, thus, does not harm the user experience, while still exploring the action space and, thus, being able to find an optimal policy. Our experiments using text classification and document retrieval confirm the above by comparing SEA (and a boundless variant called BSEA) to online and offline learning methods for contextual bandit problems.