 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Repetition for Mitigating Position Bias in LLM-Based Ranking
Jul 23, 2025


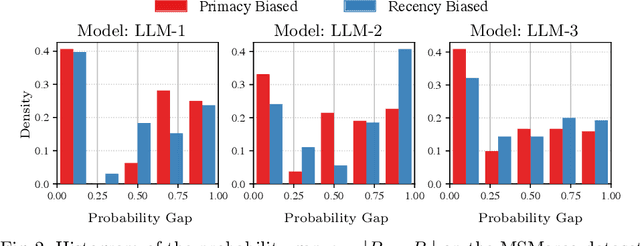
When using LLMs to rank items based on given criteria, or evaluate answers, the order of candidate items can influence the model's final decision. This sensitivity to item positioning in a LLM's prompt is known as position bias. Prior research shows that this bias exists even in large models, though its severity varies across models and tasks. In addition to position bias, LLMs also exhibit varying degrees of low repetition consistency, where repeating the LLM call with the same candidate ordering can lead to different rankings. To address both inconsistencies, a common approach is to prompt the model multiple times with different candidate orderings and aggregate the results via majority voting. However, this repetition strategy, significantly increases computational costs. Extending prior findings, we observe that both the direction -- favoring either the earlier or later candidate in the prompt -- and magnitude of position bias across instances vary substantially, even within a single dataset. This observation highlights the need for a per-instance mitigation strategy. To this end, we introduce a dynamic early-stopping method that adaptively determines the number of repetitions required for each instance. Evaluating our approach across three LLMs of varying sizes and on two tasks, namely re-ranking and alignment, we demonstrate that transitioning to a dynamic repetition strategy reduces the number of LLM calls by an average of 81%, while preserving the accuracy. Furthermore, we propose a confidence-based adaptation to our early-stopping method, reducing LLM calls by an average of 87% compared to static repetition, with only a slight accuracy trade-off relative to our original early-stopping method.
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
Oct 22, 2024
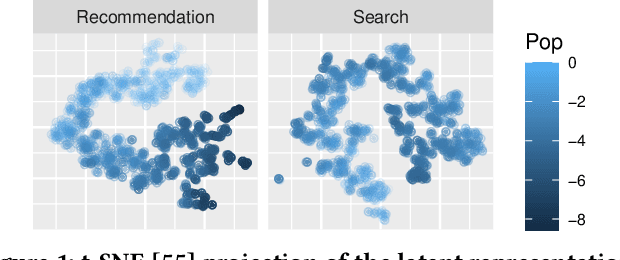


Generative retrieval for search and recommendation is a promising paradigm for retrieving items, offering an alternative to traditional methods that depend on external indexes and nearest-neighbor searches. Instead, generative models directly associate inputs with item IDs. Given the breakthroughs of Large Language Models (LLMs), these generative systems can play a crucial role in centralizing a variety of Information Retrieval (IR) tasks in a single model that performs tasks such as query understanding, retrieval, recommendation, explanation, re-ranking, and response generation. Despite the growing interest in such a unified generative approach for IR systems, the advantages of using a single, multi-task model over multiple specialized models are not well established in the literature. This paper investigates whether and when such a unified approach can outperform task-specific models in the IR tasks of search and recommendation, broadly co-existing in multiple industrial online platforms, such as Spotify, YouTube, and Netflix. Previous work shows that (1) the latent representations of items learned by generative recommenders are biased towards popularity, and (2) content-based and collaborative-filtering-based information can improve an item's representations. Motivated by this, our study is guided by two hypotheses: [H1] the joint training regularizes the estimation of each item's popularity, and [H2] the joint training regularizes the item's latent representations, where search captures content-based aspects of an item and recommendation captures collaborative-filtering aspects. Our extensive experiments with both simulated and real-world data support both [H1] and [H2] as key contributors to the effectiveness improvements observed in the unified search and recommendation generative models over the single-task approaches.
Group Membership Bias
Aug 05, 2023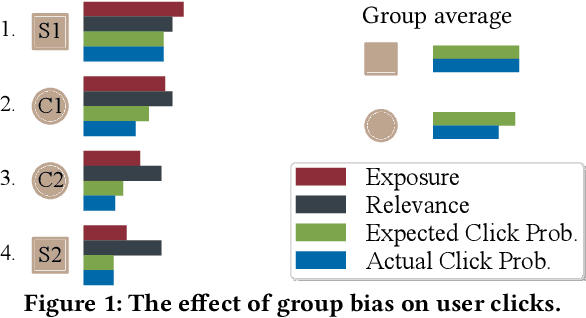
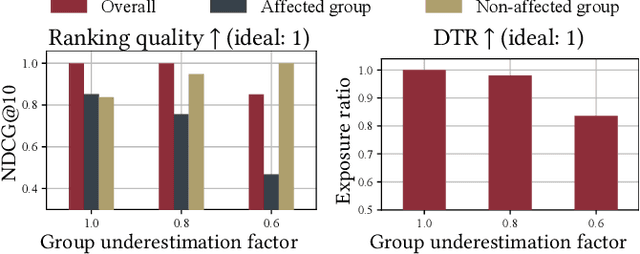

When learning to rank from user interactions, search and recommendation systems must address biases in user behavior to provide a high-quality ranking. One type of bias that has recently been studied in the ranking literature is when sensitive attributes, such as gender, have an impact on a user's judgment about an item's utility. For example, in a search for an expertise area, some users may be biased towards clicking on male candidates over female candidates. We call this type of bias group membership bias or group bias for short. Increasingly, we seek rankings that not only have high utility but are also fair to individuals and sensitive groups. Merit-based fairness measures rely on the estimated merit or utility of the items. With group bias, the utility of the sensitive groups is under-estimated, hence, without correcting for this bias, a supposedly fair ranking is not truly fair. In this paper, first, we analyze the impact of group bias on ranking quality as well as two well-known merit-based fairness metrics and show that group bias can hurt both ranking and fairness. Then, we provide a correction method for group bias that is based on the assumption that the utility score of items in different groups comes from the same distribution. This assumption has two potential issues of sparsity and equality-instead-of-equity, which we use an amortized approach to solve. We show that our correction method can consistently compensate for the negative impact of group bias on ranking quality and fairness metrics.
Recent Advances in the Foundations and Applications of Unbiased Learning to Rank
May 04, 2023Since its inception, the field of unbiased learning to rank (ULTR) has remained very active and has seen several impactful advancements in recent years. This tutorial provides both an introduction to the core concepts of the field and an overview of recent advancements in its foundations along with several applications of its methods. The tutorial is divided into four parts: Firstly, we give an overview of the different forms of bias that can be addressed with ULTR methods. Secondly, we present a comprehensive discussion of the latest estimation techniques in the ULTR field. Thirdly, we survey published results of ULTR in real-world applications. Fourthly, we discuss the connection between ULTR and fairness in ranking. We end by briefly reflecting on the future of ULTR research and its applications. This tutorial is intended to benefit both researchers and industry practitioners who are interested in developing new ULTR solutions or utilizing them in real-world applications.
On the Impact of Outlier Bias on User Clicks
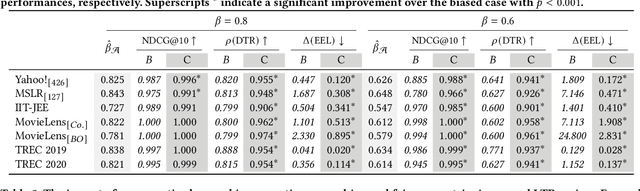
May 01, 2023User interaction data is an important source of supervision in counterfactual learning to rank (CLTR). Such data suffers from presentation bias. Much work in unbiased learning to rank (ULTR) focuses on position bias, i.e., items at higher ranks are more likely to be examined and clicked. Inter-item dependencies also influence examination probabilities, with outlier items in a ranking as an important example. Outliers are defined as items that observably deviate from the rest and therefore stand out in the ranking. In this paper, we identify and introduce the bias brought about by outlier items: users tend to click more on outlier items and their close neighbors. To this end, we first conduct a controlled experiment to study the effect of outliers on user clicks. Next, to examine whether the findings from our controlled experiment generalize to naturalistic situations, we explore real-world click logs from an e-commerce platform. We show that, in both scenarios, users tend to click significantly more on outlier items than on non-outlier items in the same rankings. We show that this tendency holds for all positions, i.e., for any specific position, an item receives more interactions when presented as an outlier as opposed to a non-outlier item. We conclude from our analysis that the effect of outliers on clicks is a type of bias that should be addressed in ULTR. We therefore propose an outlier-aware click model that accounts for both outlier and position bias, called outlier-aware position-based model ( OPBM). We estimate click propensities based on OPBM ; through extensive experiments performed on both real-world e-commerce data and semi-synthetic data, we verify the effectiveness of our outlier-aware click model. Our results show the superiority of OPBM against baselines in terms of ranking performance and true relevance estimation.
State Spaces Aren't Enough: Machine Translation Needs Attention
Apr 25, 2023Structured State Spaces for Sequences (S4) is a recently proposed sequence model with successful applications in various tasks, e.g. vision, language modeling, and audio. Thanks to its mathematical formulation, it compresses its input to a single hidden state, and is able to capture long range dependencies while avoiding the need for an attention mechanism. In this work, we apply S4 to Machine Translation (MT), and evaluate several encoder-decoder variants on WMT'14 and WMT'16. In contrast with the success in language modeling, we find that S4 lags behind the Transformer by approximately 4 BLEU points, and that it counter-intuitively struggles with long sentences. Finally, we show that this gap is caused by S4's inability to summarize the full source sentence in a single hidden state, and show that we can close the gap by introducing an attention mechanism.
Intersection of Parallels as an Early Stopping Criterion
Aug 19, 2022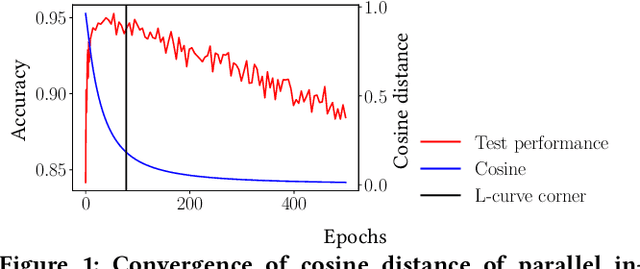
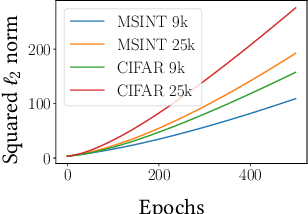
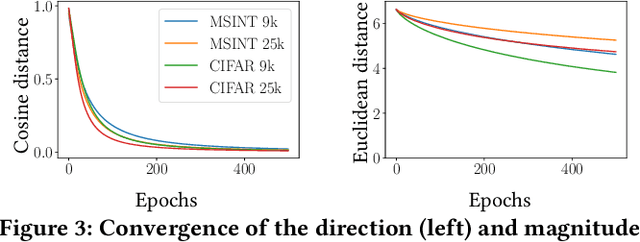
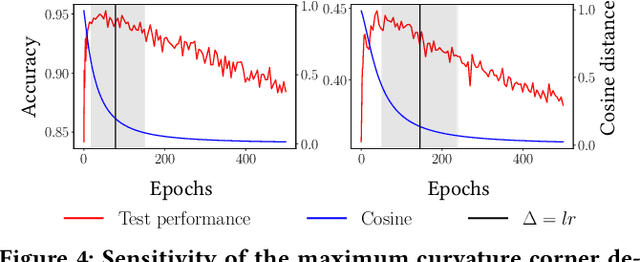
A common way to avoid overfitting in supervised learning is early stopping, where a held-out set is used for iterative evaluation during training to find a sweet spot in the number of training steps that gives maximum generalization. However, such a method requires a disjoint validation set, thus part of the labeled data from the training set is usually left out for this purpose, which is not ideal when training data is scarce. Furthermore, when the training labels are noisy, the performance of the model over a validation set may not be an accurate proxy for generalization. In this paper, we propose a method to spot an early stopping point in the training iterations without the need for a validation set. We first show that in the overparameterized regime the randomly initialized weights of a linear model converge to the same direction during training. Using this result, we propose to train two parallel instances of a linear model, initialized with different random seeds, and use their intersection as a signal to detect overfitting. In order to detect intersection, we use the cosine distance between the weights of the parallel models during training iterations. Noticing that the final layer of a NN is a linear map of pre-last layer activations to output logits, we build on our criterion for linear models and propose an extension to multi-layer networks, using the new notion of counterfactual weights. We conduct experiments on two areas that early stopping has noticeable impact on preventing overfitting of a NN: (i) learning from noisy labels; and (ii) learning to rank in IR. Our experiments on four widely used datasets confirm the effectiveness of our method for generalization. For a wide range of learning rates, our method, called Cosine-Distance Criterion (CDC), leads to better generalization on average than all the methods that we compare against in almost all of the tested cases.
Probabilistic Permutation Graph Search: Black-Box Optimization for Fairness in Ranking
Apr 28, 2022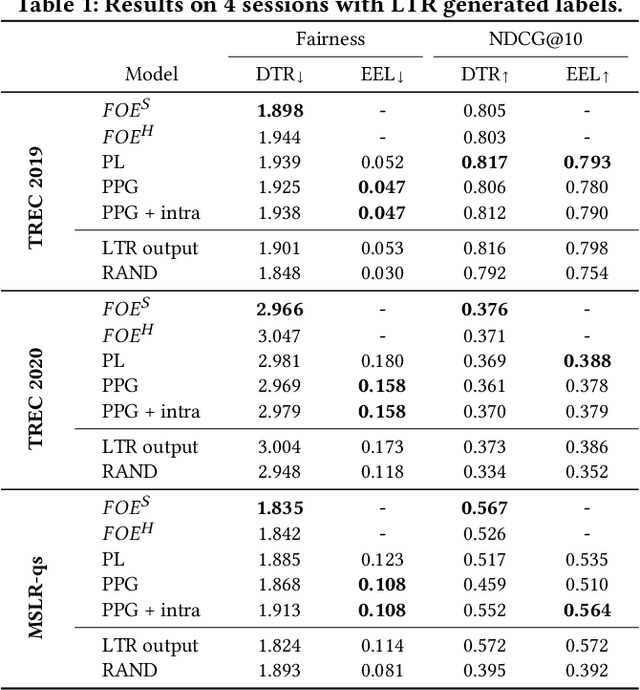
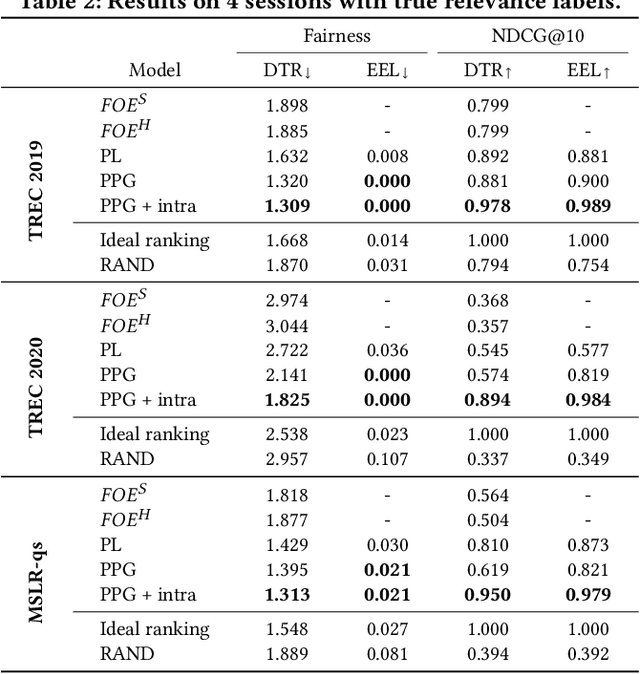
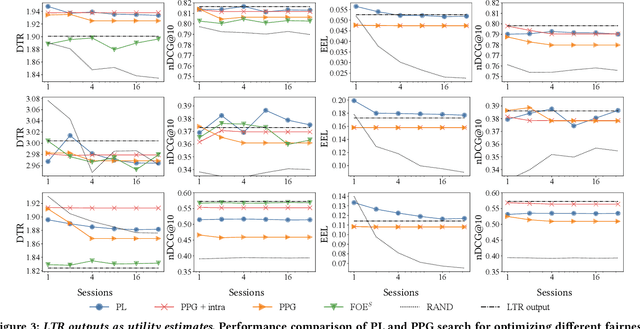
There are several measures for fairness in ranking, based on different underlying assumptions and perspectives. PL optimization with the REINFORCE algorithm can be used for optimizing black-box objective functions over permutations. In particular, it can be used for optimizing fairness measures. However, though effective for queries with a moderate number of repeating sessions, PL optimization has room for improvement for queries with a small number of repeating sessions. In this paper, we present a novel way of representing permutation distributions, based on the notion of permutation graphs. Similar to PL, our distribution representation, called PPG, can be used for black-box optimization of fairness. Different from PL, where pointwise logits are used as the distribution parameters, in PPG pairwise inversion probabilities together with a reference permutation construct the distribution. As such, the reference permutation can be set to the best sampled permutation regarding the objective function, making PPG suitable for both deterministic and stochastic rankings. Our experiments show that PPG, while comparable to PL for larger session repetitions (i.e., stochastic ranking), improves over PL for optimizing fairness metrics for queries with one session (i.e., deterministic ranking). Additionally, when accurate utility estimations are available, e.g., in tabular models, the performance of PPG in fairness optimization is significantly boosted compared to lower quality utility estimations from a learning to rank model, leading to a large performance gap with PL. Finally, the pairwise probabilities make it possible to impose pairwise constraints such as "item $d_1$ should always be ranked higher than item $d_2$." Such constraints can be used to simultaneously optimize the fairness metric and control another objective such as ranking performance.
Cross-Market Product Recommendation
Sep 13, 2021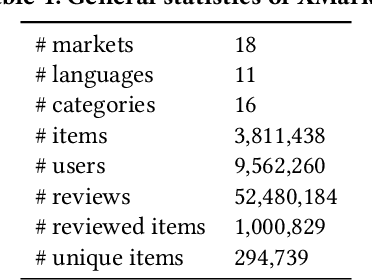
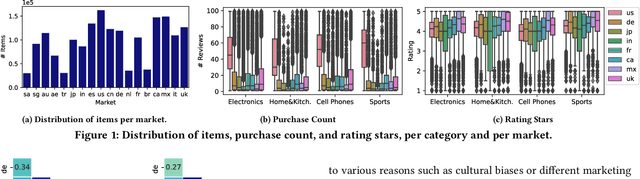
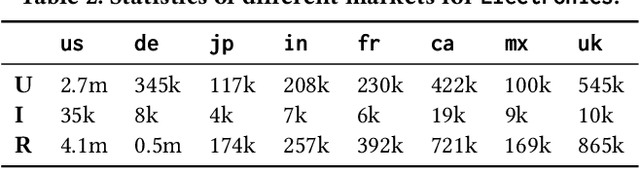
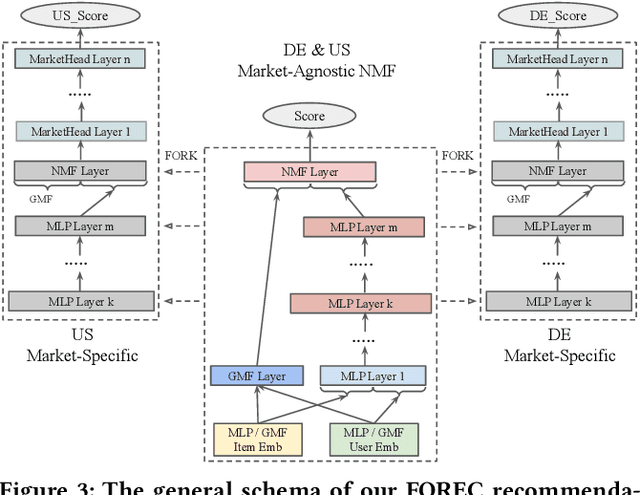
We study the problem of recommending relevant products to users in relatively resource-scarce markets by leveraging data from similar, richer in resource auxiliary markets. We hypothesize that data from one market can be used to improve performance in another. Only a few studies have been conducted in this area, partly due to the lack of publicly available experimental data. To this end, we collect and release XMarket, a large dataset covering 18 local markets on 16 different product categories, featuring 52.5 million user-item interactions. We introduce and formalize the problem of cross-market product recommendation, i.e., market adaptation. We explore different market-adaptation techniques inspired by state-of-the-art domain-adaptation and meta-learning approaches and propose a novel neural approach for market adaptation, named FOREC. Our model follows a three-step procedure -- pre-training, forking, and fine-tuning -- in order to fully utilize the data from an auxiliary market as well as the target market. We conduct extensive experiments studying the impact of market adaptation on different pairs of markets. Our proposed approach demonstrates robust effectiveness, consistently improving the performance on target markets compared to competitive baselines selected for our analysis. In particular, FOREC improves on average 24% and up to 50% in terms of nDCG@10, compared to the NMF baseline. Our analysis and experiments suggest specific future directions in this research area. We release our data and code for academic purposes.
Mixture-Based Correction for Position and Trust Bias in Counterfactual Learning to Rank
Aug 19, 2021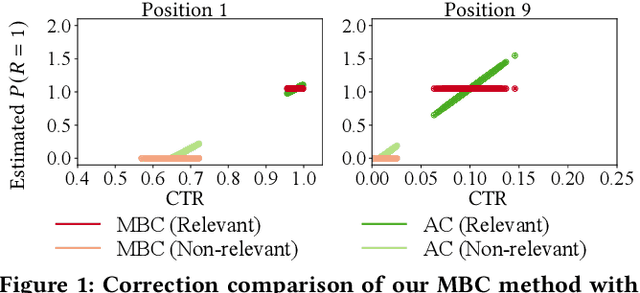
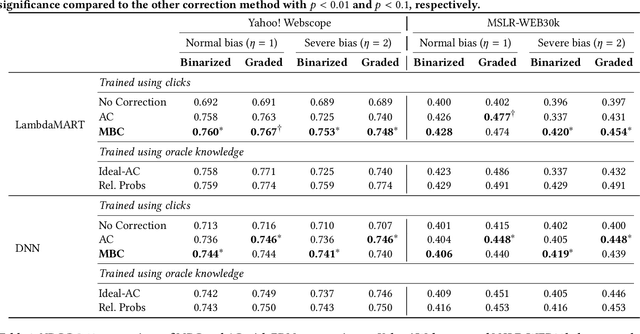
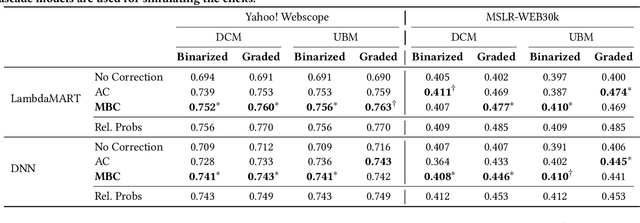
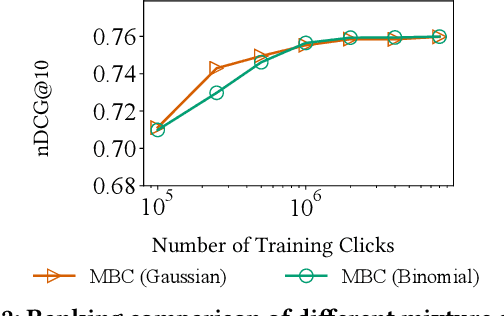
In counterfactual learning to rank (CLTR) user interactions are used as a source of supervision. Since user interactions come with bias, an important focus of research in this field lies in developing methods to correct for the bias of interactions. Inverse propensity scoring (IPS) is a popular method suitable for correcting position bias. Affine correction (AC) is a generalization of IPS that corrects for position bias and trust bias. IPS and AC provably remove bias, conditioned on an accurate estimation of the bias parameters. Estimating the bias parameters, in turn, requires an accurate estimation of the relevance probabilities. This cyclic dependency introduces practical limitations in terms of sensitivity, convergence and efficiency. We propose a new correction method for position and trust bias in CLTR in which, unlike the existing methods, the correction does not rely on relevance estimation. Our proposed method, mixture-based correction (MBC), is based on the assumption that the distribution of the CTRs over the items being ranked is a mixture of two distributions: the distribution of CTRs for relevant items and the distribution of CTRs for non-relevant items. We prove that our method is unbiased. The validity of our proof is not conditioned on accurate bias parameter estimation. Our experiments show that MBC, when used in different bias settings and accompanied by different LTR algorithms, outperforms AC, the state-of-the-art method for correcting position and trust bias, in some settings, while performing on par in other settings. Furthermore, MBC is orders of magnitude more efficient than AC in terms of the training time.