 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Language-Specific Layers for Multilingual Machine Translation
May 04, 2023Multilingual Machine Translation promises to improve translation quality between non-English languages. This is advantageous for several reasons, namely lower latency (no need to translate twice), and reduced error cascades (e.g., avoiding losing gender and formality information when translating through English). On the downside, adding more languages reduces model capacity per language, which is usually countered by increasing the overall model size, making training harder and inference slower. In this work, we introduce Language-Specific Transformer Layers (LSLs), which allow us to increase model capacity, while keeping the amount of computation and the number of parameters used in the forward pass constant. The key idea is to have some layers of the encoder be source or target language-specific, while keeping the remaining layers shared. We study the best way to place these layers using a neural architecture search inspired approach, and achieve an improvement of 1.3 chrF (1.5 spBLEU) points over not using LSLs on a separate decoder architecture, and 1.9 chrF (2.2 spBLEU) on a shared decoder one.
State Spaces Aren't Enough: Machine Translation Needs Attention
Apr 25, 2023Structured State Spaces for Sequences (S4) is a recently proposed sequence model with successful applications in various tasks, e.g. vision, language modeling, and audio. Thanks to its mathematical formulation, it compresses its input to a single hidden state, and is able to capture long range dependencies while avoiding the need for an attention mechanism. In this work, we apply S4 to Machine Translation (MT), and evaluate several encoder-decoder variants on WMT'14 and WMT'16. In contrast with the success in language modeling, we find that S4 lags behind the Transformer by approximately 4 BLEU points, and that it counter-intuitively struggles with long sentences. Finally, we show that this gap is caused by S4's inability to summarize the full source sentence in a single hidden state, and show that we can close the gap by introducing an attention mechanism.
Non-Autoregressive Neural Machine Translation: A Call for Clarity
May 21, 2022

Non-autoregressive approaches aim to improve the inference speed of translation models by only requiring a single forward pass to generate the output sequence instead of iteratively producing each predicted token. Consequently, their translation quality still tends to be inferior to their autoregressive counterparts due to several issues involving output token interdependence. In this work, we take a step back and revisit several techniques that have been proposed for improving non-autoregressive translation models and compare their combined translation quality and speed implications under third-party testing environments. We provide novel insights for establishing strong baselines using length prediction or CTC-based architecture variants and contribute standardized BLEU, chrF++, and TER scores using sacreBLEU on four translation tasks, which crucially have been missing as inconsistencies in the use of tokenized BLEU lead to deviations of up to 1.7 BLEU points. Our open-sourced code is integrated into fairseq for reproducibility.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Explainability-aided Domain Generalization for Image Classification
Apr 05, 2021
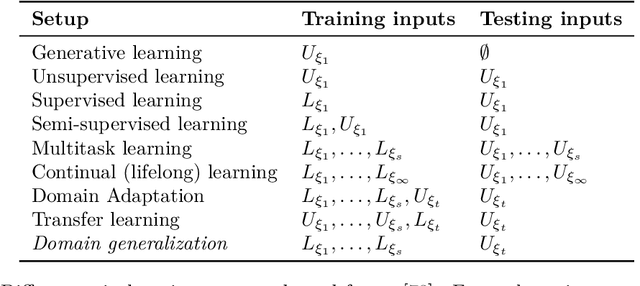

Traditionally, for most machine learning settings, gaining some degree of explainability that tries to give users more insights into how and why the network arrives at its predictions, restricts the underlying model and hinders performance to a certain degree. For example, decision trees are thought of as being more explainable than deep neural networks but they lack performance on visual tasks. In this work, we empirically demonstrate that applying methods and architectures from the explainability literature can, in fact, achieve state-of-the-art performance for the challenging task of domain generalization while offering a framework for more insights into the prediction and training process. For that, we develop a set of novel algorithms including DivCAM, an approach where the network receives guidance during training via gradient based class activation maps to focus on a diverse set of discriminative features, as well as ProDrop and D-Transformers which apply prototypical networks to the domain generalization task, either with self-challenging or attention alignment. Since these methods offer competitive performance on top of explainability, we argue that the proposed methods can be used as a tool to improve the robustness of deep neural network architectures.
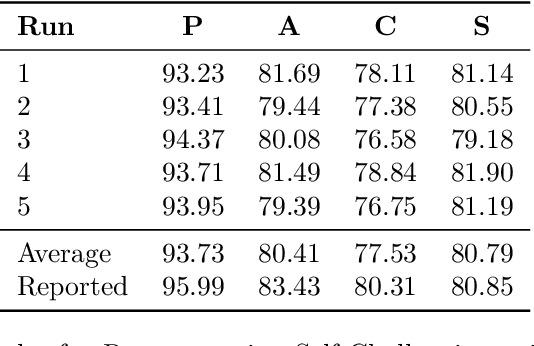
Collaborative Filtering under Model Uncertainty
Aug 25, 2020

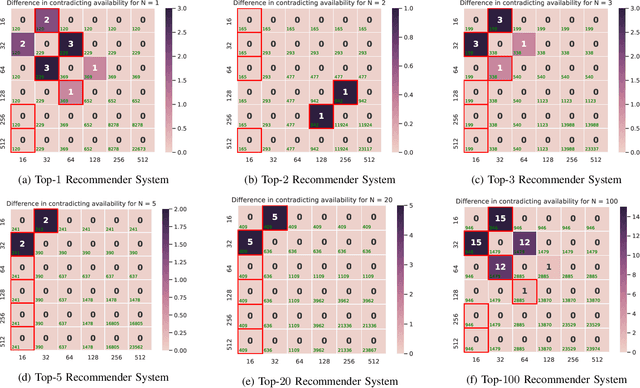
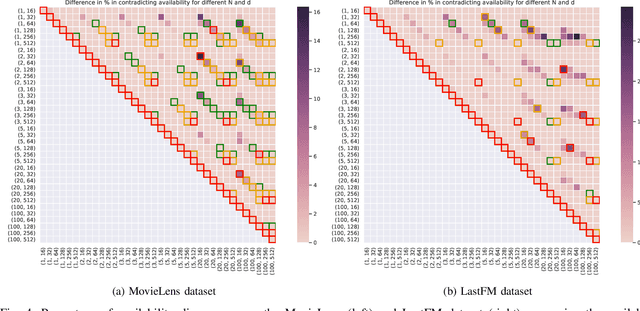
In their work, Dean, Rich, and Recht create a model to research recourse and availability of items in a recommender system. We used the definition of predictive multiplicity by Marx, Pin Calmon, and Ustun to examine different variations of this model, using different values for two model parameters. Pairwise comparison of their models show, that most of these models produce very similar results in terms of discrepancy and ambiguity for the availability and only in some cases the availability sets differ significantly.
Descending through a Crowded Valley - Benchmarking Deep Learning Optimizers
Jul 07, 2020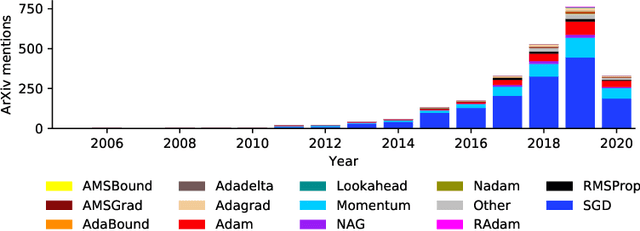
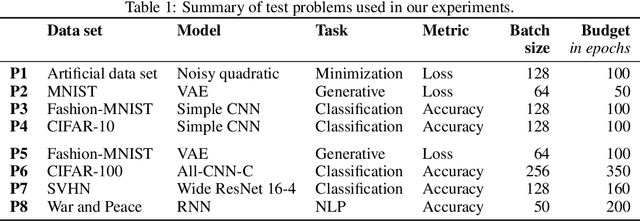
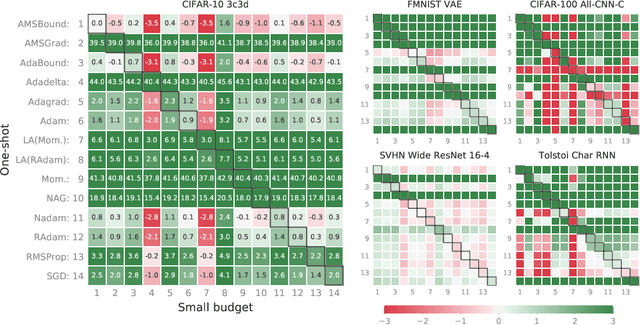
Choosing the optimizer is among the most crucial decisions of deep learning engineers, and it is not an easy one. The growing literature now lists literally hundreds of optimization methods. In the absence of clear theoretical guidance and conclusive empirical evidence, the decision is often done according to personal anecdotes. In this work, we aim to replace these anecdotes, if not with evidence, then at least with heuristics. To do so, we perform an extensive, standardized benchmark of more than a dozen particularly popular deep learning optimizers while giving a concise overview of the wide range of possible choices. Analyzing almost 35 000 individual runs, we contribute the following three points: Optimizer performance varies greatly across tasks. We observe that evaluating multiple optimizers with default parameters works approximately as well as tuning the hyperparameters of a single, fixed optimizer. While we can not identify an individual optimization method clearly dominating across all tested tasks, we identify a significantly reduced subset of specific algorithms and parameter choices that generally provided competitive results in our experiments. This subset includes popular favorites and some less well-known contenders. We have open-sourced all our experimental results, making it available to use as well-tuned baselines when evaluating novel optimization methods and therefore reducing the necessary computational efforts.
Recurrent Neural Networks (RNNs): A gentle Introduction and Overview
Nov 23, 2019State-of-the-art solutions in the areas of "Language Modelling & Generating Text", "Speech Recognition", "Generating Image Descriptions" or "Video Tagging" have been using Recurrent Neural Networks as the foundation for their approaches. Understanding the underlying concepts is therefore of tremendous importance if we want to keep up with recent or upcoming publications in those areas. In this work we give a short overview over some of the most important concepts in the realm of Recurrent Neural Networks which enables readers to easily understand the fundamentals such as but not limited to "Backpropagation through Time" or "Long Short-Term Memory Units" as well as some of the more recent advances like the "Attention Mechanism" or "Pointer Networks". We also give recommendations for further reading regarding more complex topics where it is necessary.