 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Corpus Aware Training for Neural Machine Translation
Aug 07, 2025Corpus Aware Training (CAT) leverages valuable corpus metadata during training by injecting corpus information into each training example, and has been found effective in the literature, commonly known as the "tagging" approach. Models trained with CAT inherently learn the quality, domain and nuance between corpora directly from data, and can easily switch to different inference behavior. To achieve the best evaluation, CAT models pre-define a group of high quality data before training starts which can be error-prone and inefficient. In this work, we propose Optimal Corpus Aware Training (OCAT), which fine-tunes a CAT pre-trained model by freezing most of the model parameters and only tuning small set of corpus-related parameters. We show that OCAT is lightweight, resilient to overfitting, and effective in boosting model accuracy. We use WMT23 English to Chinese and English to German translation tasks as our test ground and show +3.6 and +1.8 chrF improvement, respectively, over vanilla training. Furthermore, our approach is on-par or slightly better than other state-of-the-art fine-tuning techniques while being less sensitive to hyperparameter settings.
Learning Language-Specific Layers for Multilingual Machine Translation
May 04, 2023Multilingual Machine Translation promises to improve translation quality between non-English languages. This is advantageous for several reasons, namely lower latency (no need to translate twice), and reduced error cascades (e.g., avoiding losing gender and formality information when translating through English). On the downside, adding more languages reduces model capacity per language, which is usually countered by increasing the overall model size, making training harder and inference slower. In this work, we introduce Language-Specific Transformer Layers (LSLs), which allow us to increase model capacity, while keeping the amount of computation and the number of parameters used in the forward pass constant. The key idea is to have some layers of the encoder be source or target language-specific, while keeping the remaining layers shared. We study the best way to place these layers using a neural architecture search inspired approach, and achieve an improvement of 1.3 chrF (1.5 spBLEU) points over not using LSLs on a separate decoder architecture, and 1.9 chrF (2.2 spBLEU) on a shared decoder one.
Efficient Inference For Neural Machine Translation
Oct 07, 2020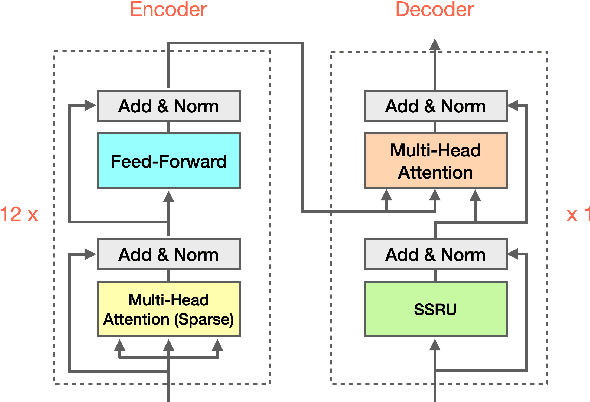
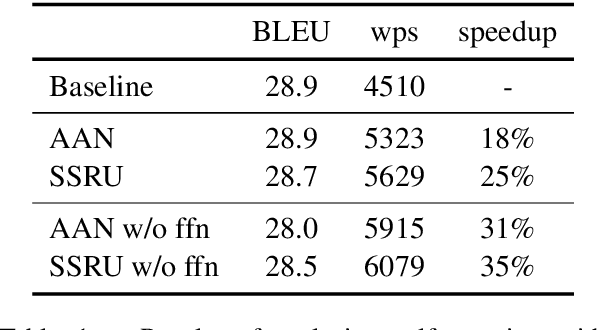
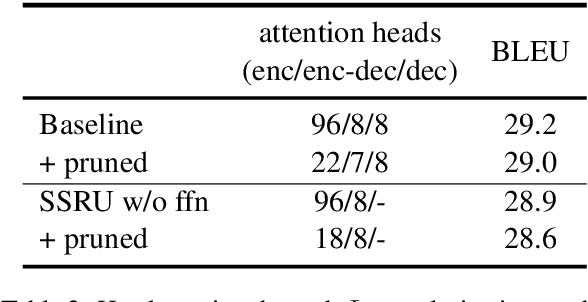
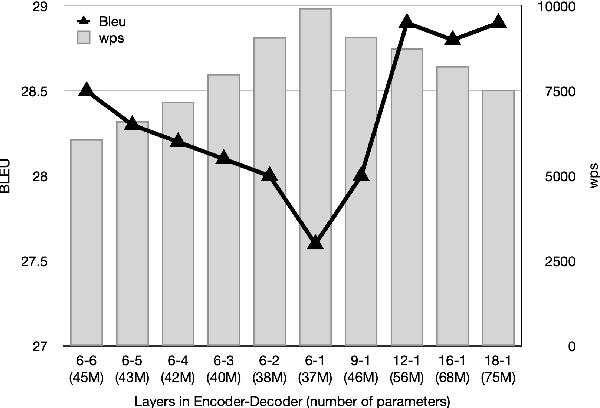
Large Transformer models have achieved state-of-the-art results in neural machine translation and have become standard in the field. In this work, we look for the optimal combination of known techniques to optimize inference speed without sacrificing translation quality. We conduct an empirical study that stacks various approaches and demonstrates that combination of replacing decoder self-attention with simplified recurrent units, adopting a deep encoder and a shallow decoder architecture and multi-head attention pruning can achieve up to 109% and 84% speedup on CPU and GPU respectively and reduce the number of parameters by 25% while maintaining the same translation quality in terms of BLEU.
Towards Structured Deep Neural Network for Automatic Speech Recognition
Nov 08, 2015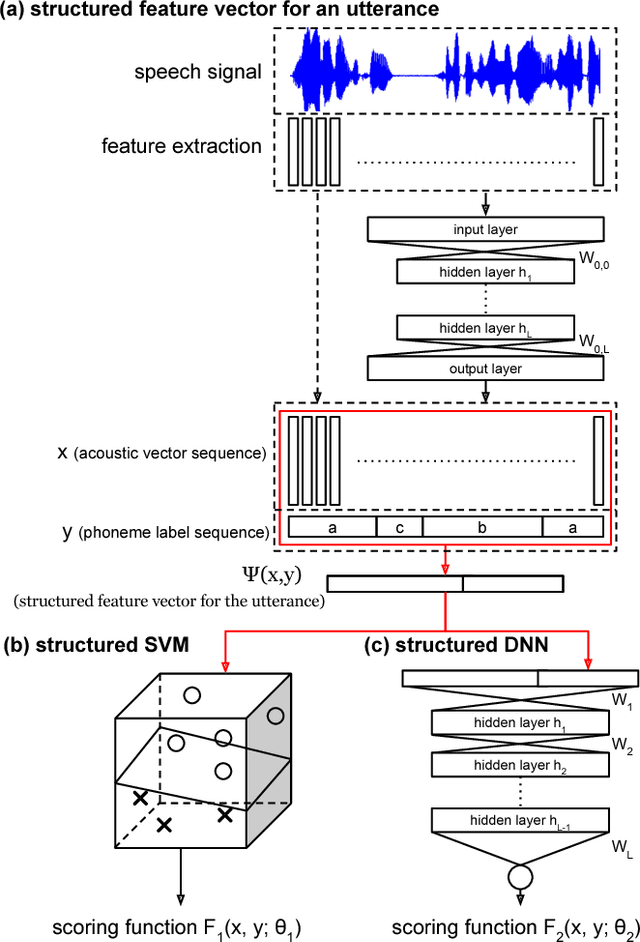

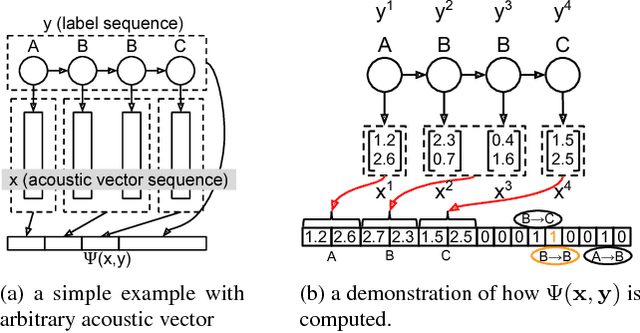
In this paper we propose the Structured Deep Neural Network (structured DNN) as a structured and deep learning framework. This approach can learn to find the best structured object (such as a label sequence) given a structured input (such as a vector sequence) by globally considering the mapping relationships between the structures rather than item by item. When automatic speech recognition is viewed as a special case of such a structured learning problem, where we have the acoustic vector sequence as the input and the phoneme label sequence as the output, it becomes possible to comprehensively learn utterance by utterance as a whole, rather than frame by frame. Structured Support Vector Machine (structured SVM) was proposed to perform ASR with structured learning previously, but limited by the linear nature of SVM. Here we propose structured DNN to use nonlinear transformations in multi-layers as a structured and deep learning approach. This approach was shown to beat structured SVM in preliminary experiments on TIMIT.