 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscreteSLU: A Large Language Model with Self-Supervised Discrete Speech Units for Spoken Language Understanding
Jun 13, 2024



The integration of pre-trained text-based large language models (LLM) with speech input has enabled instruction-following capabilities for diverse speech tasks. This integration requires the use of a speech encoder, a speech adapter, and an LLM, trained on diverse tasks. We propose the use of discrete speech units (DSU), rather than continuous-valued speech encoder outputs, that are converted to the LLM token embedding space using the speech adapter. We generate DSU using a self-supervised speech encoder followed by k-means clustering. The proposed model shows robust performance on speech inputs from seen/unseen domains and instruction-following capability in spoken question answering. We also explore various types of DSU extracted from different layers of the self-supervised speech encoder, as well as Mel frequency Cepstral Coefficients (MFCC). Our findings suggest that the ASR task and datasets are not crucial in instruction-tuning for spoken question answering tasks.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023



When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
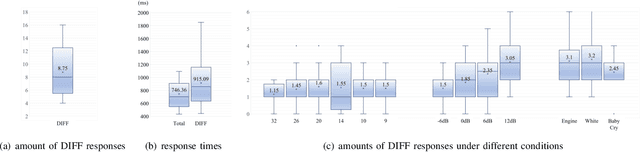
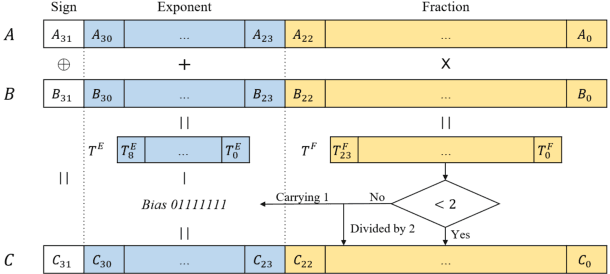
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.
Efficient Inference For Neural Machine Translation
Oct 07, 2020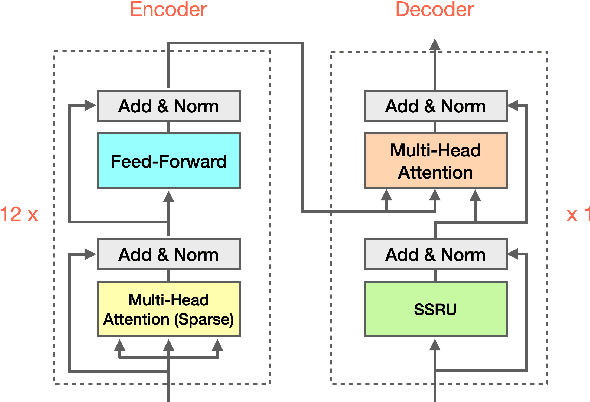
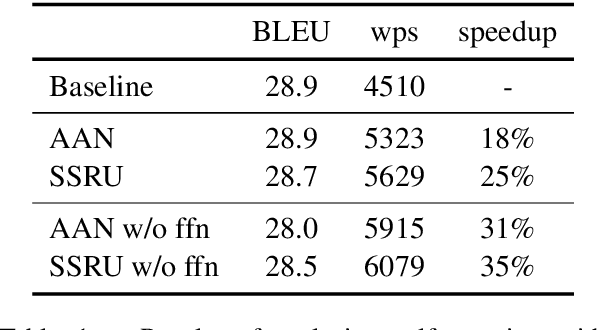
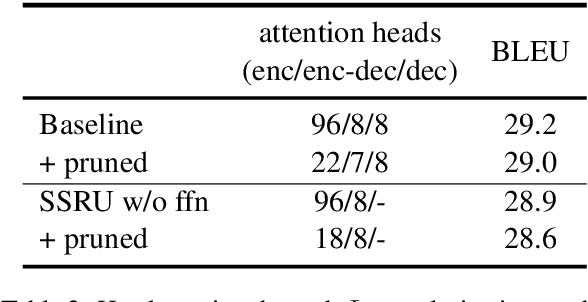
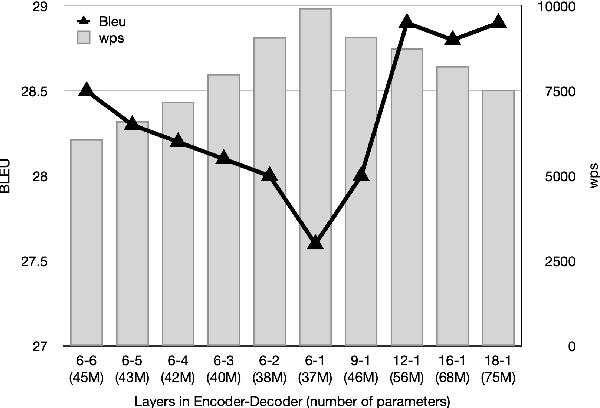
Large Transformer models have achieved state-of-the-art results in neural machine translation and have become standard in the field. In this work, we look for the optimal combination of known techniques to optimize inference speed without sacrificing translation quality. We conduct an empirical study that stacks various approaches and demonstrates that combination of replacing decoder self-attention with simplified recurrent units, adopting a deep encoder and a shallow decoder architecture and multi-head attention pruning can achieve up to 109% and 84% speedup on CPU and GPU respectively and reduce the number of parameters by 25% while maintaining the same translation quality in terms of BLEU.
Detecting dementia in Mandarin Chinese using transfer learning from a parallel corpus
Mar 03, 2019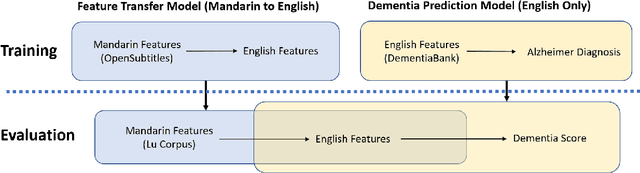
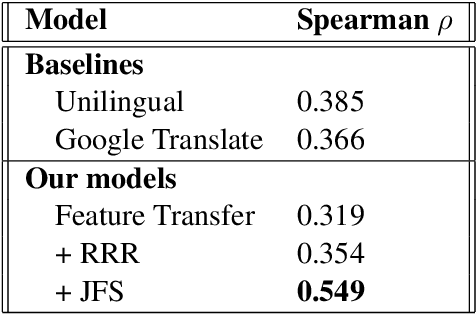
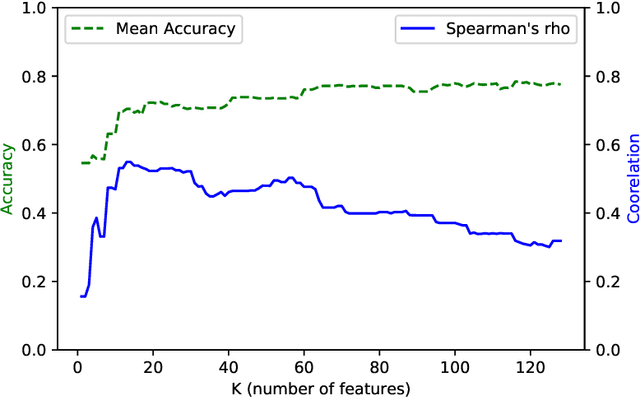
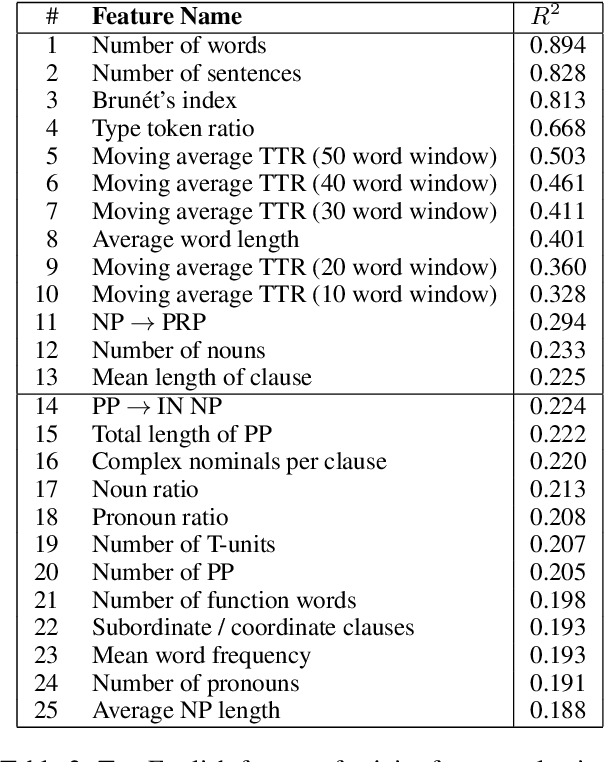
Machine learning has shown promise for automatic detection of Alzheimer's disease (AD) through speech; however, efforts are hampered by a scarcity of data, especially in languages other than English. We propose a method to learn a correspondence between independently engineered lexicosyntactic features in two languages, using a large parallel corpus of out-of-domain movie dialogue data. We apply it to dementia detection in Mandarin Chinese, and demonstrate that our method outperforms both unilingual and machine translation-based baselines. This appears to be the first study that transfers feature domains in detecting cognitive decline.
Robustness against the channel effect in pathological voice detection
Dec 02, 2018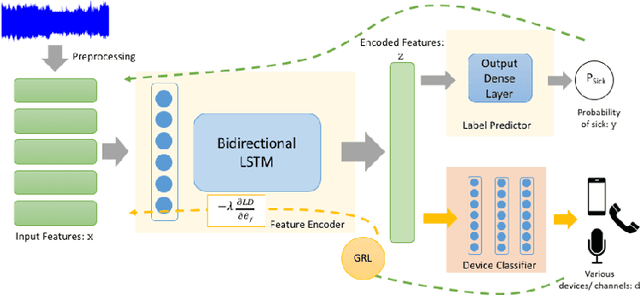
Many people are suffering from voice disorders, which can adversely affect the quality of their lives. In response, some researchers have proposed algorithms for automatic assessment of these disorders, based on voice signals. However, these signals can be sensitive to the recording devices. Indeed, the channel effect is a pervasive problem in machine learning for healthcare. In this study, we propose a detection system for pathological voice, which is robust against the channel effect. This system is based on a bidirectional LSTM network. To increase the performance robustness against channel mismatch, we integrate domain adversarial training (DAT) to eliminate the differences between the devices. When we train on data recorded on a high-quality microphone and evaluate on smartphone data without labels, our robust detection system increases the PR-AUC from 0.8448 to 0.9455 (and 0.9522 with target sample labels). To the best of our knowledge, this is the first study applying unsupervised domain adaptation to pathological voice detection. Notably, our system does not need target device sample labels, which allows for generalization to many new devices.
A study on speech enhancement using exponent-only floating point quantized neural network
Oct 30, 2018
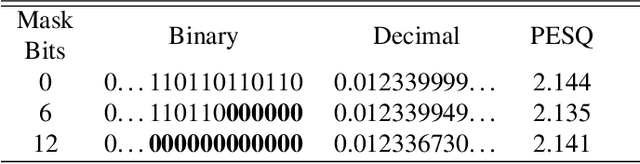
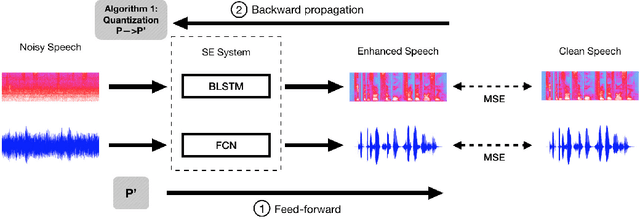
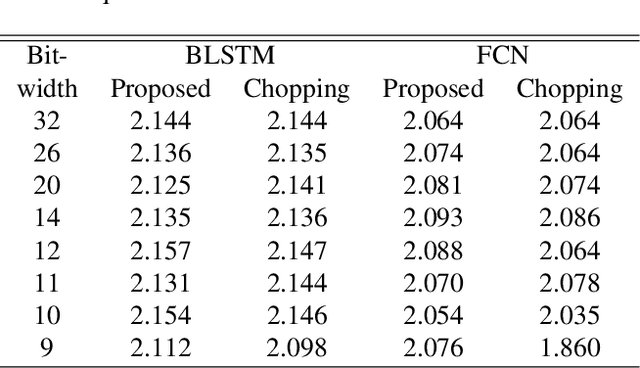
Numerous studies have investigated the effectiveness of neural network quantization on pattern classification tasks. The present study, for the first time, investigated the performance of speech enhancement (a regression task in speech processing) using a novel exponent-only floating-point quantized neural network (EOFP-QNN). The proposed EOFP-QNN consists of two stages: mantissa-quantization and exponent-quantization. In the mantissa-quantization stage, EOFP-QNN learns how to quantize the mantissa bits of the model parameters while preserving the regression accuracy using the least mantissa precision. In the exponent-quantization stage, the exponent part of the parameters is further quantized without causing any additional performance degradation. We evaluated the proposed EOFP quantization technique on two types of neural networks, namely, bidirectional long short-term memory (BLSTM) and fully convolutional neural network (FCN), on a speech enhancement task. Experimental results showed that the model sizes can be significantly reduced (the model sizes of the quantized BLSTM and FCN models were only 18.75% and 21.89%, respectively, compared to those of the original models) while maintaining satisfactory speech-enhancement performance.