 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Paper and Code
Nov 08, 2021
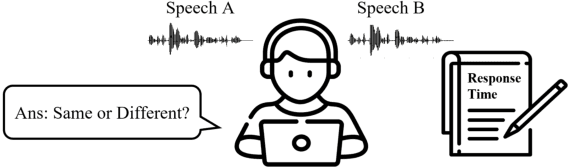
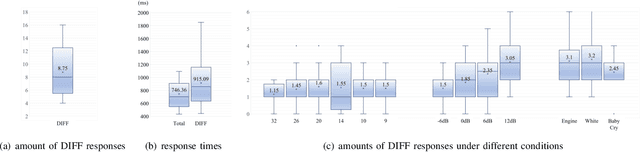
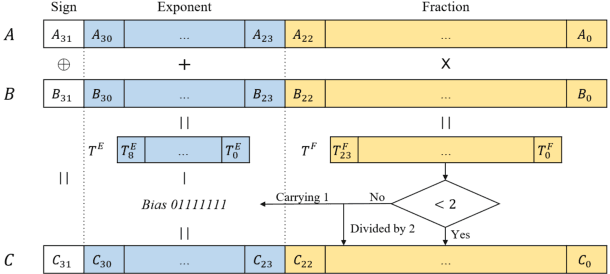
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.