 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
Large Language Multimodal Models for 5-Year Chronic Disease Cohort Prediction Using EHR Data
Mar 02, 2024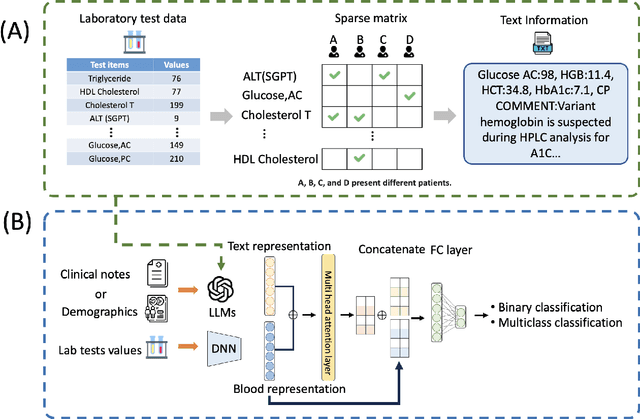
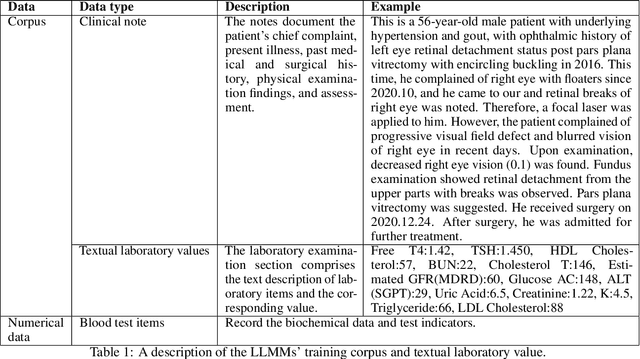

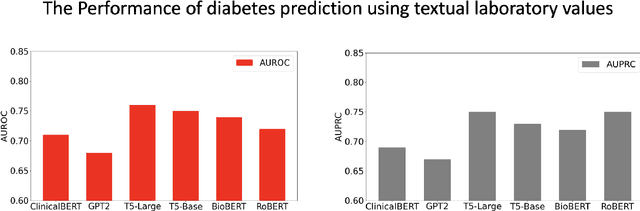
Chronic diseases such as diabetes are the leading causes of morbidity and mortality worldwide. Numerous research studies have been attempted with various deep learning models in diagnosis. However, most previous studies had certain limitations, including using publicly available datasets (e.g. MIMIC), and imbalanced data. In this study, we collected five-year electronic health records (EHRs) from the Taiwan hospital database, including 1,420,596 clinical notes, 387,392 laboratory test results, and more than 1,505 laboratory test items, focusing on research pre-training large language models. We proposed a novel Large Language Multimodal Models (LLMMs) framework incorporating multimodal data from clinical notes and laboratory test results for the prediction of chronic disease risk. Our method combined a text embedding encoder and multi-head attention layer to learn laboratory test values, utilizing a deep neural network (DNN) module to merge blood features with chronic disease semantics into a latent space. In our experiments, we observe that clinicalBERT and PubMed-BERT, when combined with attention fusion, can achieve an accuracy of 73% in multiclass chronic diseases and diabetes prediction. By transforming laboratory test values into textual descriptions and employing the Flan T-5 model, we achieved a 76% Area Under the ROC Curve (AUROC), demonstrating the effectiveness of leveraging numerical text data for training and inference in language models. This approach significantly improves the accuracy of early-stage diabetes prediction.
Continuous Speech for Improved Learning Pathological Voice Disorders
Feb 22, 2022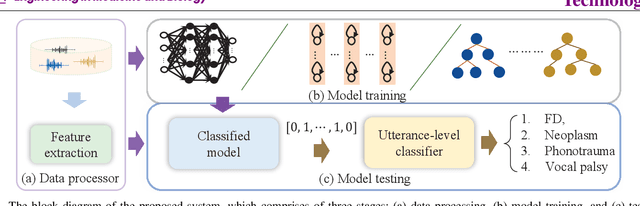
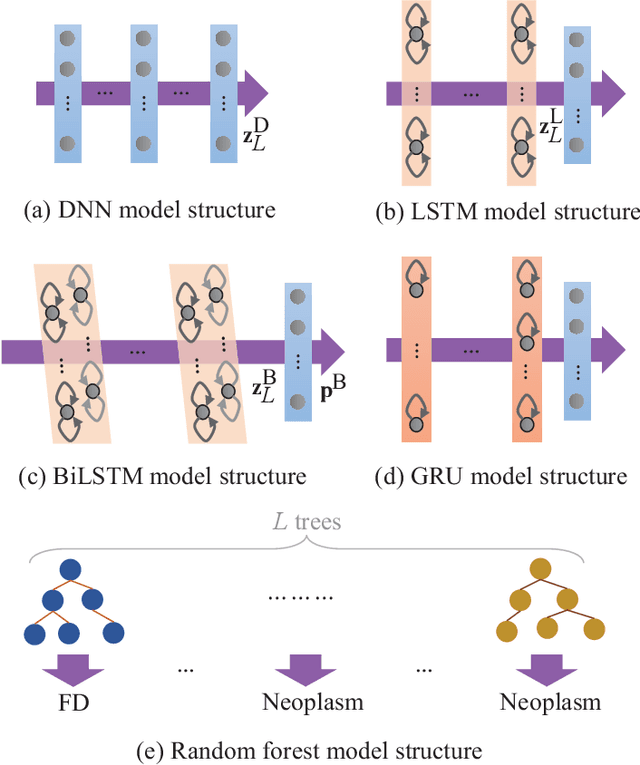
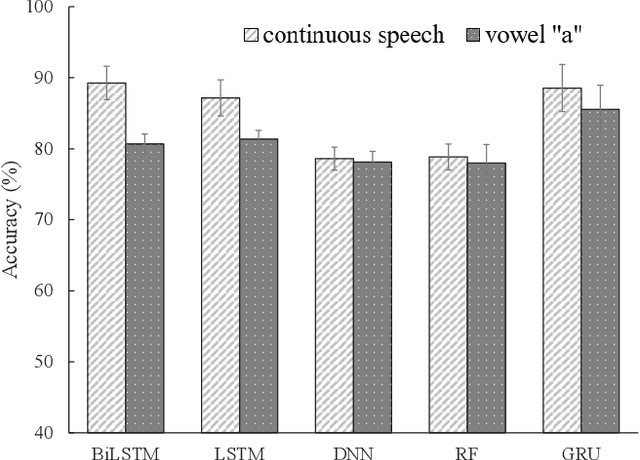
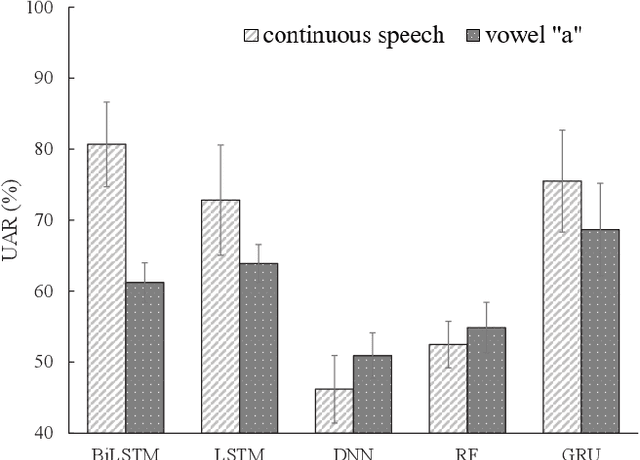
Goal: Numerous studies had successfully differentiated normal and abnormal voice samples. Nevertheless, further classification had rarely been attempted. This study proposes a novel approach, using continuous Mandarin speech instead of a single vowel, to classify four common voice disorders (i.e. functional dysphonia, neoplasm, phonotrauma, and vocal palsy). Methods: In the proposed framework, acoustic signals are transformed into mel-frequency cepstral coefficients, and a bi-directional long-short term memory network (BiLSTM) is adopted to model the sequential features. The experiments were conducted on a large-scale database, wherein 1,045 continuous speech were collected by the speech clinic of a hospital from 2012 to 2019. Results: Experimental results demonstrated that the proposed framework yields significant accuracy and unweighted average recall improvements of 78.12-89.27% and 50.92-80.68%, respectively, compared with systems that use a single vowel. Conclusions: The results are consistent with other machine learning algorithms, including gated recurrent units, random forest, deep neural networks, and LSTM. The sensitivities for each disorder were also analyzed, and the model capabilities were visualized via principal component analysis. An alternative experiment based on a balanced dataset again confirms the advantages of using continuous speech for learning voice disorders.
Robustness against the channel effect in pathological voice detection
Dec 02, 2018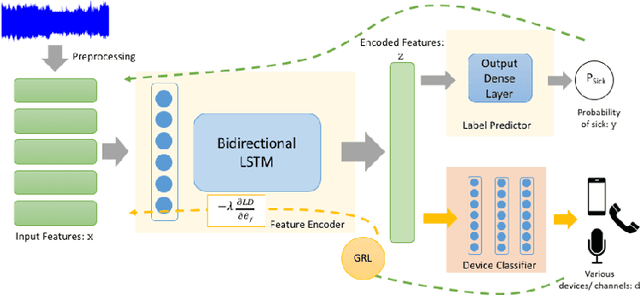
Many people are suffering from voice disorders, which can adversely affect the quality of their lives. In response, some researchers have proposed algorithms for automatic assessment of these disorders, based on voice signals. However, these signals can be sensitive to the recording devices. Indeed, the channel effect is a pervasive problem in machine learning for healthcare. In this study, we propose a detection system for pathological voice, which is robust against the channel effect. This system is based on a bidirectional LSTM network. To increase the performance robustness against channel mismatch, we integrate domain adversarial training (DAT) to eliminate the differences between the devices. When we train on data recorded on a high-quality microphone and evaluate on smartphone data without labels, our robust detection system increases the PR-AUC from 0.8448 to 0.9455 (and 0.9522 with target sample labels). To the best of our knowledge, this is the first study applying unsupervised domain adaptation to pathological voice detection. Notably, our system does not need target device sample labels, which allows for generalization to many new devices.