 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Face-Mask Speech Enhancement Using Generative Adversarial Networks with Human-in-the-Loop Assessment Metrics
Jul 02, 2024The utilization of face masks is an essential healthcare measure, particularly during times of pandemics, yet it can present challenges in communication in our daily lives. To address this problem, we propose a novel approach known as the human-in-the-loop StarGAN (HL-StarGAN) face-masked speech enhancement method. HL-StarGAN comprises discriminator, classifier, metric assessment predictor, and generator that leverages an attention mechanism. The metric assessment predictor, referred to as MaskQSS, incorporates human participants in its development and serves as a "human-in-the-loop" module during the learning process of HL-StarGAN. The overall HL-StarGAN model was trained using an unsupervised learning strategy that simultaneously focuses on the reconstruction of the original clean speech and the optimization of human perception. To implement HL-StarGAN, we curated a face-masked speech database named "FMVD," which comprises recordings from 34 speakers in three distinct face-masked scenarios and a clean condition. We conducted subjective and objective tests on the proposed HL-StarGAN using this database. The outcomes of the test results are as follows: (1) MaskQSS successfully predicted the quality scores of face mask voices, outperforming several existing speech assessment methods. (2) The integration of the MaskQSS predictor enhanced the ability of HL-StarGAN to transform face mask voices into high-quality speech; this enhancement is evident in both objective and subjective tests, outperforming conventional StarGAN and CycleGAN-based systems.
* face-mask speech enhancement, generative adversarial networks, StarGAN, human-in-the-loop, unsupervised learning
IANS: Intelligibility-aware Null-steering Beamforming for Dual-Microphone Arrays
Jul 09, 2023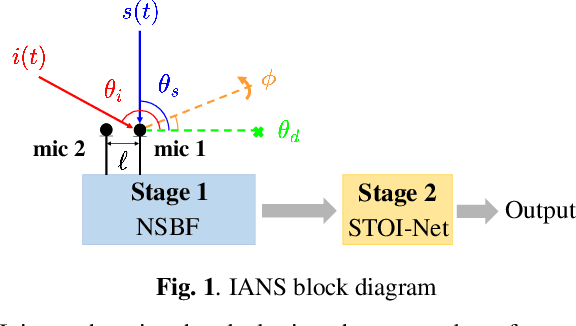
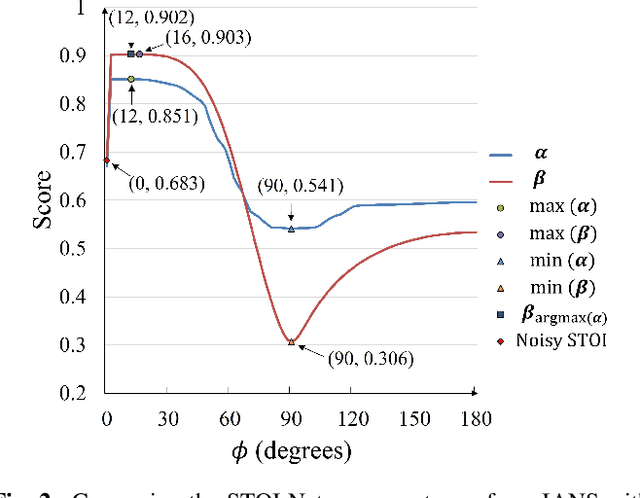
Beamforming techniques are popular in speech-related applications due to their effective spatial filtering capabilities. Nonetheless, conventional beamforming techniques generally depend heavily on either the target's direction-of-arrival (DOA), relative transfer function (RTF) or covariance matrix. This paper presents a new approach, the intelligibility-aware null-steering (IANS) beamforming framework, which uses the STOI-Net intelligibility prediction model to improve speech intelligibility without prior knowledge of the speech signal parameters mentioned earlier. The IANS framework combines a null-steering beamformer (NSBF) to generate a set of beamformed outputs, and STOI-Net, to determine the optimal result. Experimental results indicate that IANS can produce intelligibility-enhanced signals using a small dual-microphone array. The results are comparable to those obtained by null-steering beamformers with given knowledge of DOAs.
Continuous Speech for Improved Learning Pathological Voice Disorders
Feb 22, 2022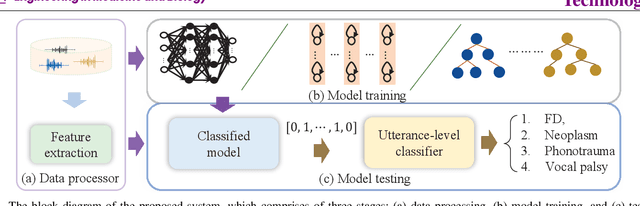
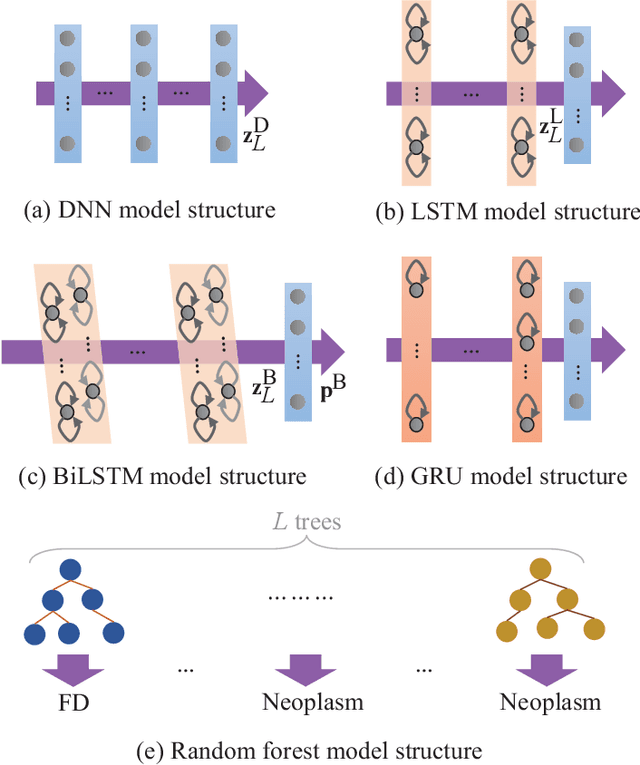
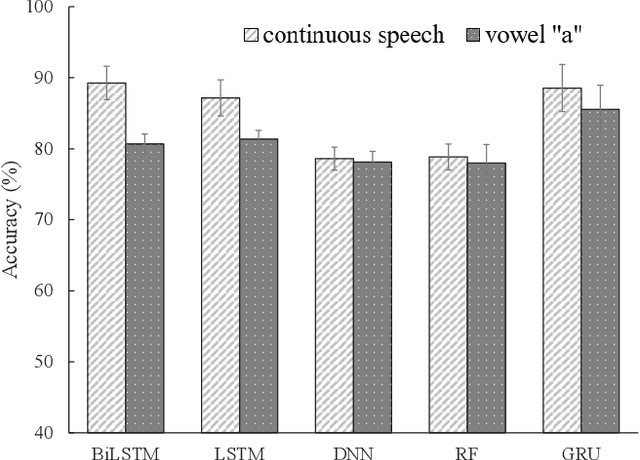
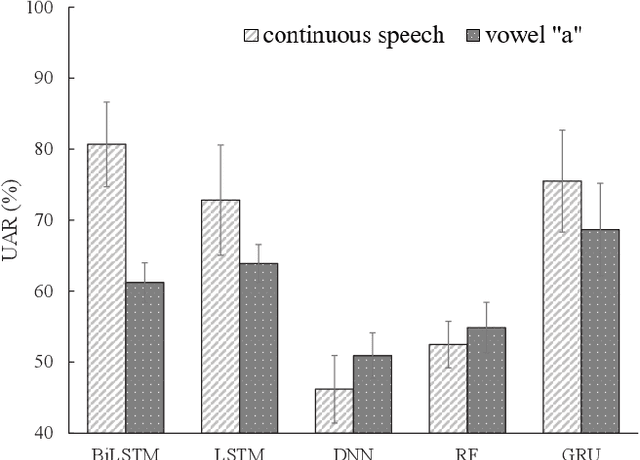
Goal: Numerous studies had successfully differentiated normal and abnormal voice samples. Nevertheless, further classification had rarely been attempted. This study proposes a novel approach, using continuous Mandarin speech instead of a single vowel, to classify four common voice disorders (i.e. functional dysphonia, neoplasm, phonotrauma, and vocal palsy). Methods: In the proposed framework, acoustic signals are transformed into mel-frequency cepstral coefficients, and a bi-directional long-short term memory network (BiLSTM) is adopted to model the sequential features. The experiments were conducted on a large-scale database, wherein 1,045 continuous speech were collected by the speech clinic of a hospital from 2012 to 2019. Results: Experimental results demonstrated that the proposed framework yields significant accuracy and unweighted average recall improvements of 78.12-89.27% and 50.92-80.68%, respectively, compared with systems that use a single vowel. Conclusions: The results are consistent with other machine learning algorithms, including gated recurrent units, random forest, deep neural networks, and LSTM. The sensitivities for each disorder were also analyzed, and the model capabilities were visualized via principal component analysis. An alternative experiment based on a balanced dataset again confirms the advantages of using continuous speech for learning voice disorders.
Speech Enhancement Based on Cyclegan with Noise-informed Training
Oct 19, 2021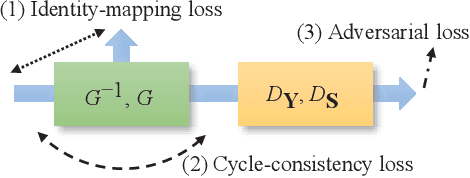
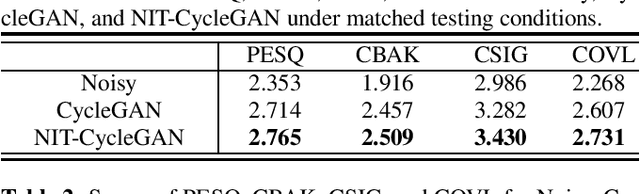
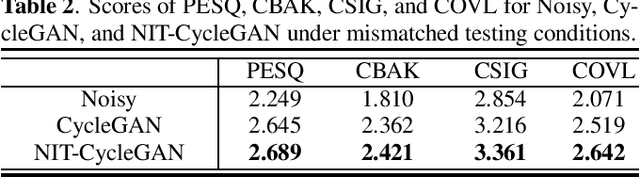
Speech enhancement (SE) approaches can be classified into supervised and unsupervised categories. For unsupervised SE, a well-known cycle-consistent generative adversarial network (CycleGAN) model, which comprises two generators and two discriminators, has been shown to provide a powerful nonlinear mapping ability and thus achieve a promising noise-suppression capability. However, a low-efficiency training process along with insufficient knowledge between noisy and clean speech may limit the enhancement performance of the CycleGAN SE at runtime. In this study, we propose a novel noise-informed-training CycleGAN approach that incorporates additional inputs into the generators and discriminators to assist the CycleGAN in learning a more accurate transformation of speech signals between the noise and clean domains. The additional input feature serves as an indicator that provides more information during the CycleGAN training stage. Experiment results confirm that the proposed approach can improve the CycleGAN SE model while achieving a better sound quality and fewer signal distortions.
Speech Enhancement-assisted Stargan Voice Conversion in Noisy Environments
Oct 19, 2021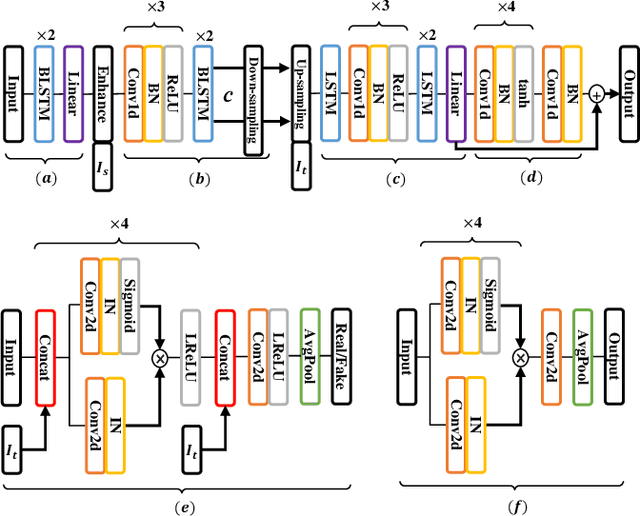

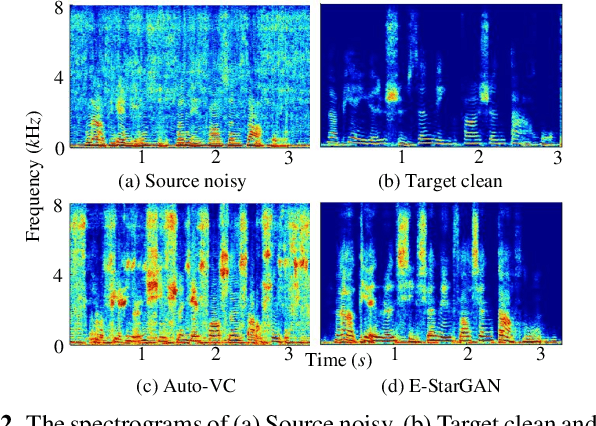
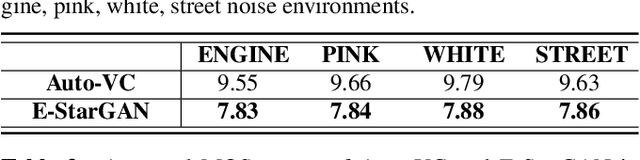
Numerous voice conversion (VC) techniques have been proposed for the conversion of voices among different speakers. Although the decent quality of converted speech can be observed when VC is applied in a clean environment, the quality will drop sharply when the system is running under noisy conditions. In order to address this issue, we propose a novel enhancement-based StarGAN (E-StarGAN) VC system, which leverages a speech enhancement (SE) technique for signal pre-processing. SE systems are generally used to reduce noise components in noisy speech and to generate enhanced speech for downstream application tasks. Therefore, we investigated the effectiveness of E-StarGAN, which combines VC and SE, and demonstrated the robustness of the proposed approach in various noisy environments. The results of VC experiments conducted on a Mandarin dataset show that when combined with SE, the proposed E-StarGAN VC model is robust to unseen noises. In addition, the subjective listening test results show that the proposed E-StarGAN model can improve the sound quality of speech signals converted from noise-corrupted source utterances.
Attention-based multi-task learning for speech-enhancement and speaker-identification in multi-speaker dialogue scenario
Jan 07, 2021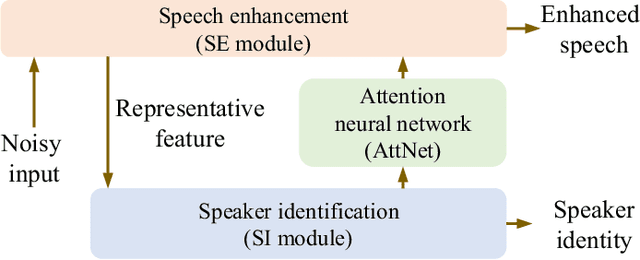
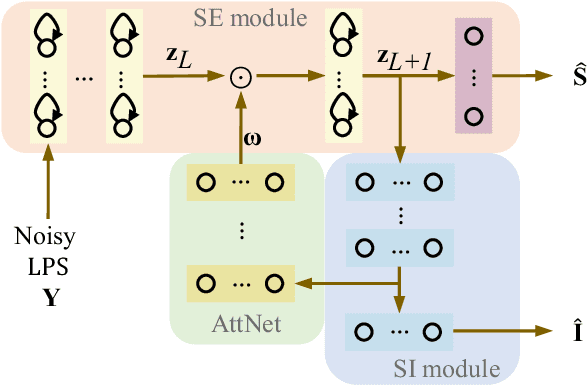
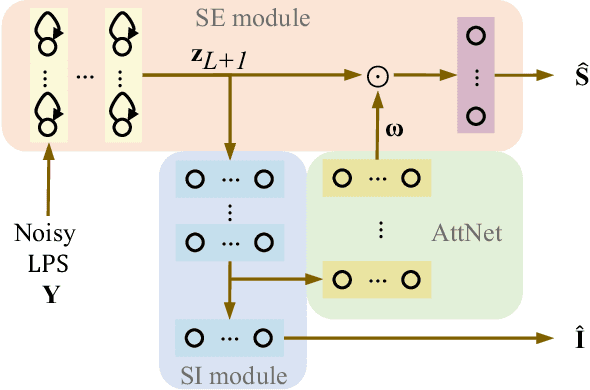
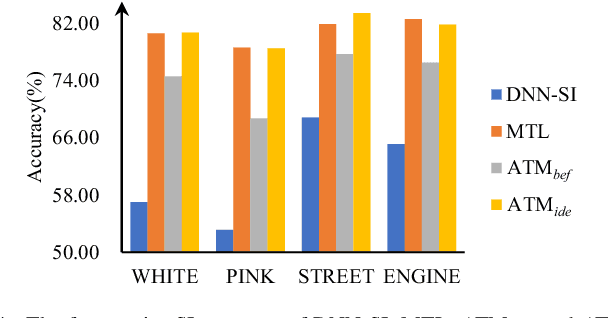
Multi-task learning (MTL) and the attention technique have been proven to effectively extract robust acoustic features for various speech-related applications in noisy environments. In this study, we integrated MTL and the attention-weighting mechanism and propose an attention-based MTL (ATM0 approach to realize a multi-model learning structure and to promote the speech enhancement (SE) and speaker identification (SI) systems simultaneously. There are three subsystems in the proposed ATM: SE, SI, and attention-Net (AttNet). In the proposed system, a long-short-term memory (LSTM) is used to perform SE, while a deep neural network (DNN) model is applied to construct SI and AttNet in ATM. The overall ATM system first extracts the representative features and then enhances the speech spectra in LSTM-SE and classifies speaker identity in DNN-SI. We conducted our experiment on Taiwan Mandarin hearing in noise test database. The evaluation results indicate that the proposed ATM system not only increases the quality and intelligibility of noisy speech input but also improves the accuracy of the SI system when compared to the conventional MTL approaches.
CITISEN: A Deep Learning-Based Speech Signal-Processing Mobile Application
Aug 21, 2020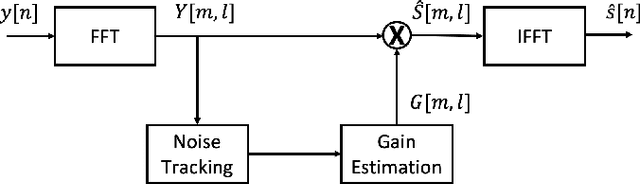
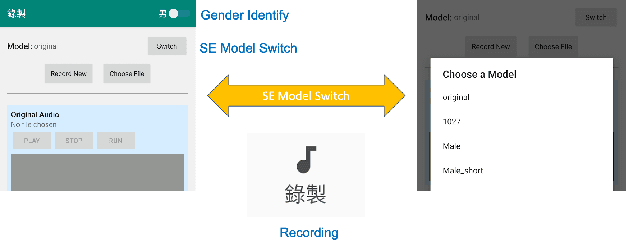
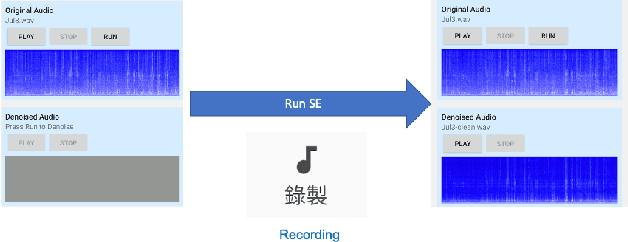
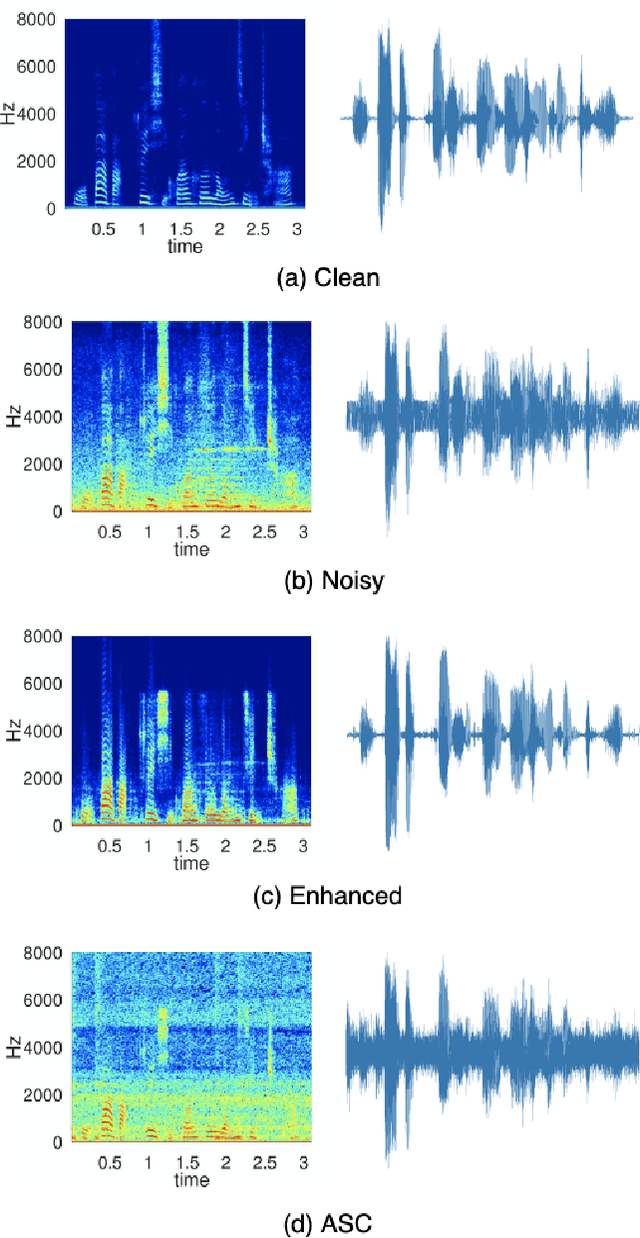
In this paper, we present a deep learning-based speech signal-processing mobile application, CITISEN, which can perform three functions: speech enhancement (SE), acoustic scene conversion (ASC), and model adaptation (MA). For SE, CITISEN can effectively reduce noise components from speech signals and accordingly enhance their clarity and intelligibility. For ASC, CITISEN can convert the current background sound to a different background sound. Finally, for MA, CITISEN can effectively adapt an SE model, with a few audio files, when it encounters unknown speakers or noise types; the adapted SE model is used to enhance the upcoming noisy utterances. Experimental results confirmed the effectiveness of CITISEN in performing these three functions via objective evaluation and subjective listening tests. The promising results reveal that the developed CITISEN mobile application can potentially be used as a front-end processor for various speech-related services such as voice communication, assistive hearing devices, and virtual reality headsets.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020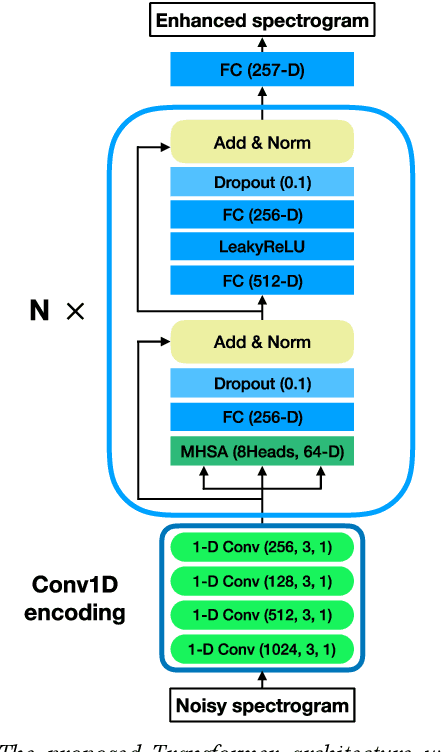
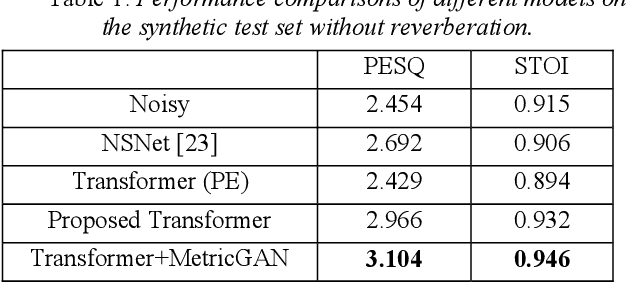
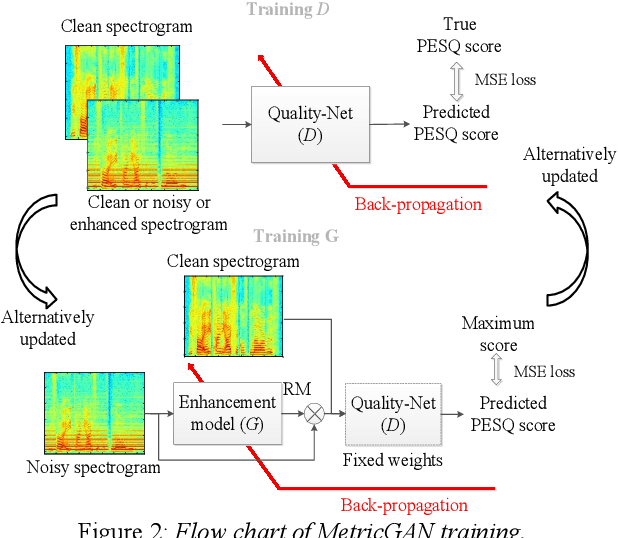

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.
Distributed Microphone Speech Enhancement based on Deep Learning
Nov 22, 2019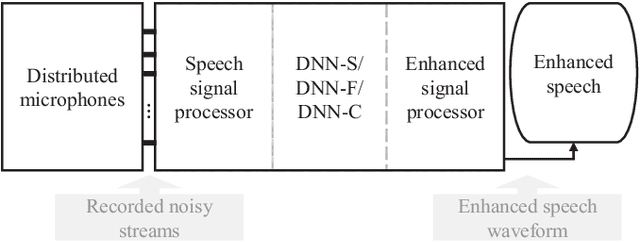

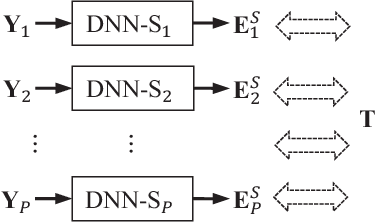
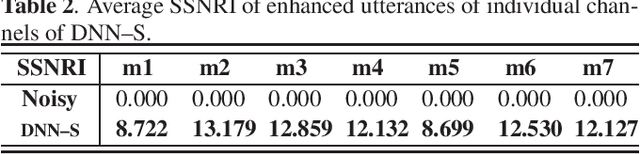
Speech-related applications deliver inferior performance in complex noise environments. Therefore, this study primarily addresses this problem by introducing speech-enhancement (SE) systems based on deep neural networks (DNNs) applied to a distributed microphone architecture. The first system constructs a DNN model for each microphone to enhance the recorded noisy speech signal, and the second system combines all the noisy recordings into a large feature structure that is then enhanced through a DNN model. As for the third system, a channel-dependent DNN is first used to enhance the corresponding noisy input, and all the channel-wise enhanced outputs are fed into a DNN fusion model to construct a nearly clean signal. All the three DNN SE systems are operated in the acoustic frequency domain of speech signals in a diffuse-noise field environment. Evaluation experiments were conducted on the Taiwan Mandarin Hearing in Noise Test (TMHINT) database, and the results indicate that all the three DNN-based SE systems provide the original noise-corrupted signals with improved speech quality and intelligibility, whereas the third system delivers the highest signal-to-noise ratio (SNR) improvement and optimal speech intelligibility.
Audio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks
Jan 24, 2018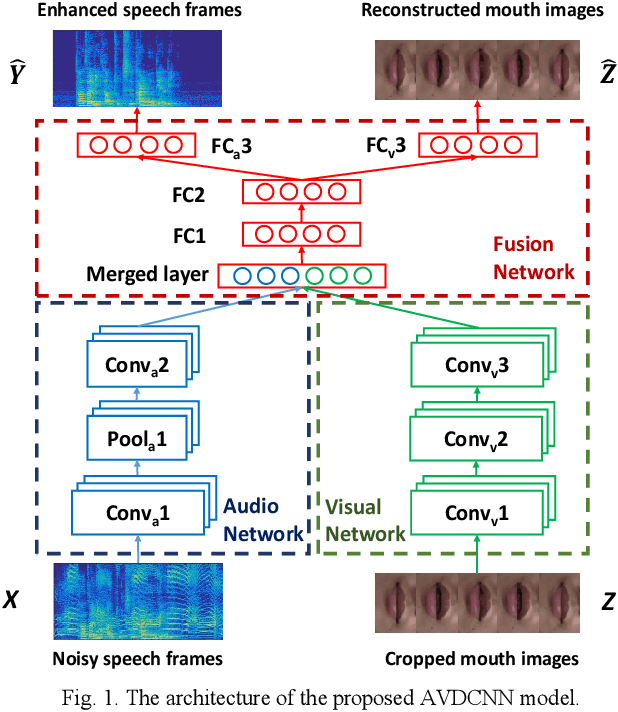
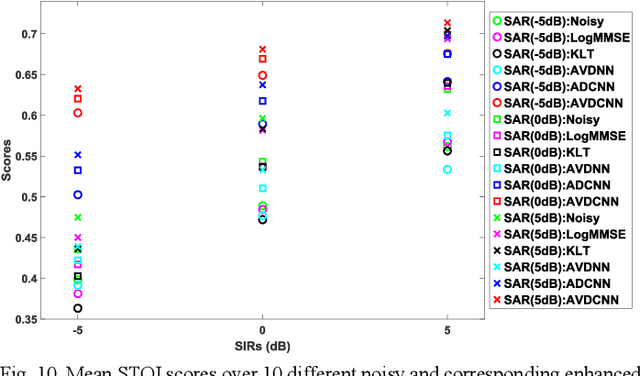
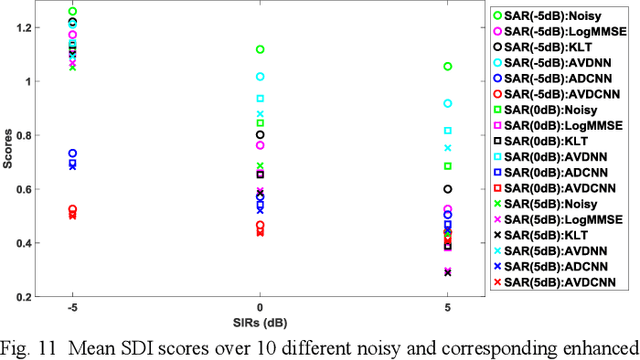
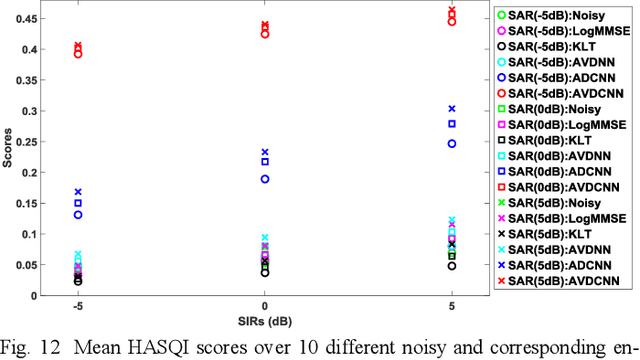
Speech enhancement (SE) aims to reduce noise in speech signals. Most SE techniques focus only on addressing audio information. In this work, inspired by multimodal learning, which utilizes data from different modalities, and the recent success of convolutional neural networks (CNNs) in SE, we propose an audio-visual deep CNNs (AVDCNN) SE model, which incorporates audio and visual streams into a unified network model. We also propose a multi-task learning framework for reconstructing audio and visual signals at the output layer. Precisely speaking, the proposed AVDCNN model is structured as an audio-visual encoder-decoder network, in which audio and visual data are first processed using individual CNNs, and then fused into a joint network to generate enhanced speech (the primary task) and reconstructed images (the secondary task) at the output layer. The model is trained in an end-to-end manner, and parameters are jointly learned through back-propagation. We evaluate enhanced speech using five instrumental criteria. Results show that the AVDCNN model yields a notably superior performance compared with an audio-only CNN-based SE model and two conventional SE approaches, confirming the effectiveness of integrating visual information into the SE process. In addition, the AVDCNN model also outperforms an existing audio-visual SE model, confirming its capability of effectively combining audio and visual information in SE.