 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks
Jan 24, 2018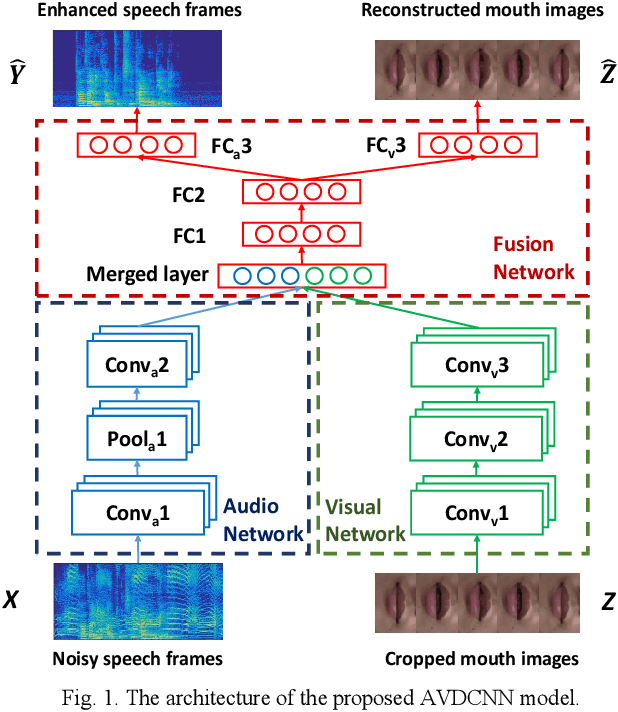
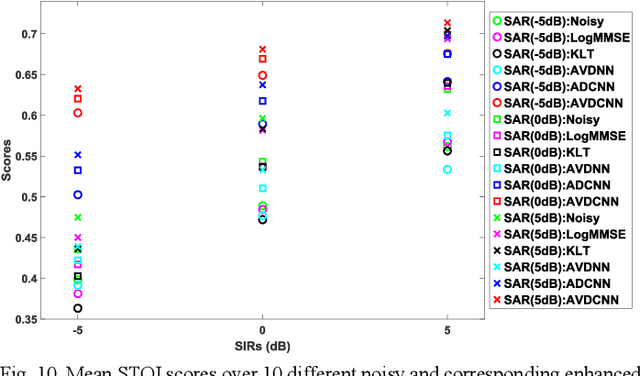
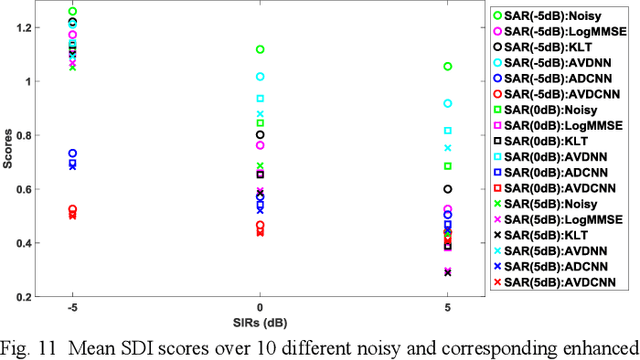
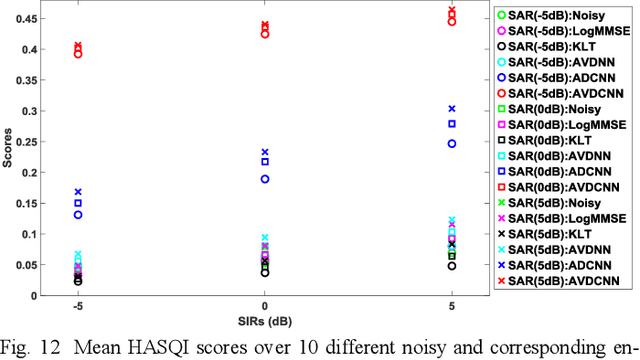
Speech enhancement (SE) aims to reduce noise in speech signals. Most SE techniques focus only on addressing audio information. In this work, inspired by multimodal learning, which utilizes data from different modalities, and the recent success of convolutional neural networks (CNNs) in SE, we propose an audio-visual deep CNNs (AVDCNN) SE model, which incorporates audio and visual streams into a unified network model. We also propose a multi-task learning framework for reconstructing audio and visual signals at the output layer. Precisely speaking, the proposed AVDCNN model is structured as an audio-visual encoder-decoder network, in which audio and visual data are first processed using individual CNNs, and then fused into a joint network to generate enhanced speech (the primary task) and reconstructed images (the secondary task) at the output layer. The model is trained in an end-to-end manner, and parameters are jointly learned through back-propagation. We evaluate enhanced speech using five instrumental criteria. Results show that the AVDCNN model yields a notably superior performance compared with an audio-only CNN-based SE model and two conventional SE approaches, confirming the effectiveness of integrating visual information into the SE process. In addition, the AVDCNN model also outperforms an existing audio-visual SE model, confirming its capability of effectively combining audio and visual information in SE.