 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do neural networks listen to? Exploring the crucial bands in Speech Enhancement using Sinc-convolution
Mar 04, 2024This study introduces a reformed Sinc-convolution (Sincconv) framework tailored for the encoder component of deep networks for speech enhancement (SE). The reformed Sincconv, based on parametrized sinc functions as band-pass filters, offers notable advantages in terms of training efficiency, filter diversity, and interpretability. The reformed Sinc-conv is evaluated in conjunction with various SE models, showcasing its ability to boost SE performance. Furthermore, the reformed Sincconv provides valuable insights into the specific frequency components that are prioritized in an SE scenario. This opens up a new direction of SE research and improving our knowledge of their operating dynamics.
ConSep: a Noise- and Reverberation-Robust Speech Separation Framework by Magnitude Conditioning
Mar 04, 2024Speech separation has recently made significant progress thanks to the fine-grained vision used in time-domain methods. However, several studies have shown that adopting Short-Time Fourier Transform (STFT) for feature extraction could be beneficial when encountering harsher conditions, such as noise or reverberation. Therefore, we propose a magnitude-conditioned time-domain framework, ConSep, to inherit the beneficial characteristics. The experiment shows that ConSep promotes performance in anechoic, noisy, and reverberant settings compared to two celebrated methods, SepFormer and Bi-Sep. Furthermore, we visualize the components of ConSep to strengthen the advantages and cohere with the actualities we have found in preliminary studies.
Naaloss: Rethinking the objective of speech enhancement
Aug 24, 2023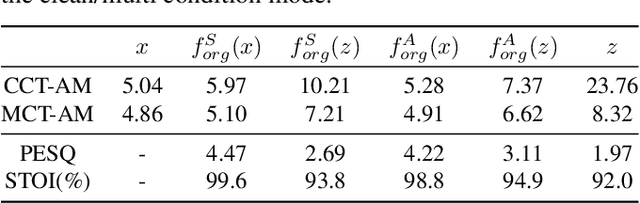
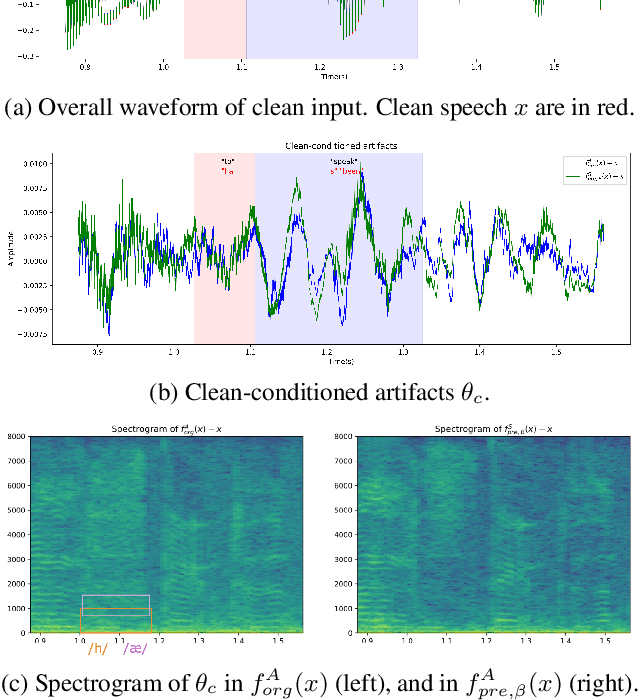
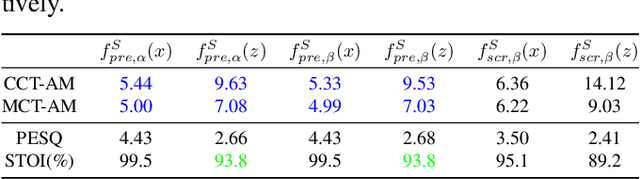
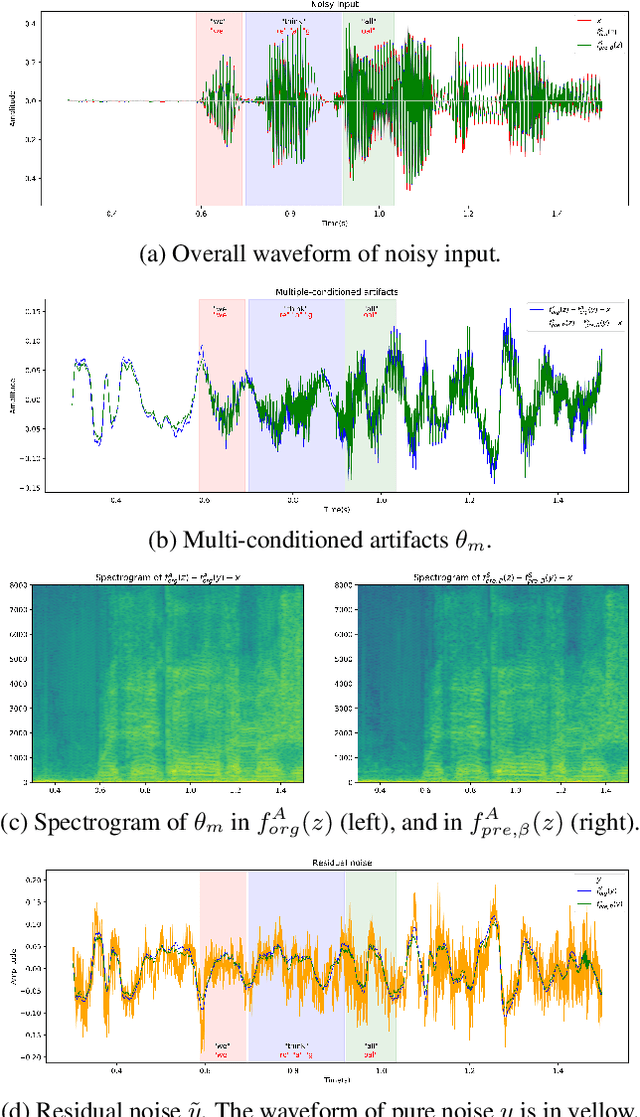
Reducing noise interference is crucial for automatic speech recognition (ASR) in a real-world scenario. However, most single-channel speech enhancement (SE) generates "processing artifacts" that negatively affect ASR performance. Hence, in this study, we suggest a Noise- and Artifacts-aware loss function, NAaLoss, to ameliorate the influence of artifacts from a novel perspective. NAaLoss considers the loss of estimation, de-artifact, and noise ignorance, enabling the learned SE to individually model speech, artifacts, and noise. We examine two SE models (simple/advanced) learned with NAaLoss under various input scenarios (clean/noisy) using two configurations of the ASR system (with/without noise robustness). Experiments reveal that NAaLoss significantly improves the ASR performance of most setups while preserving the quality of SE toward perception and intelligibility. Furthermore, we visualize artifacts through waveforms and spectrograms, and explain their impact on ASR.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021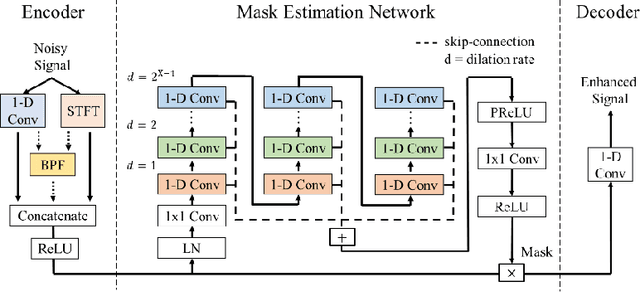
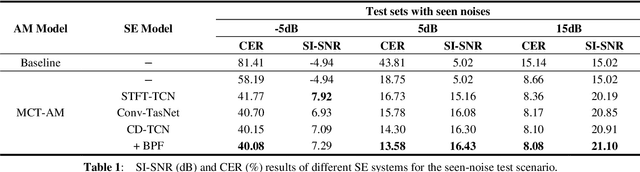
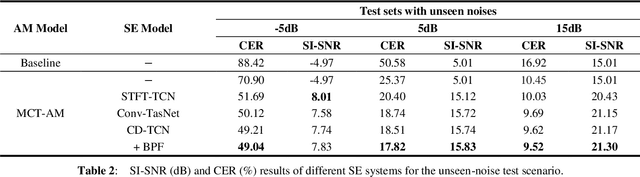
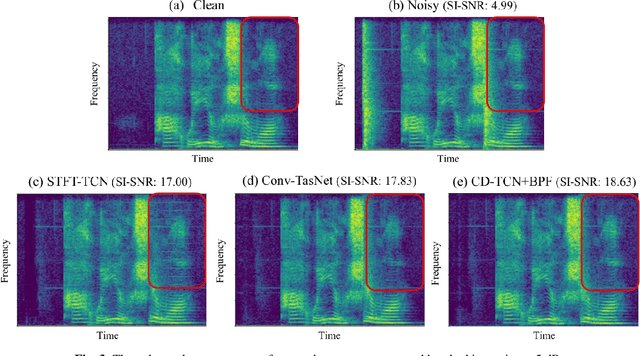
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 08, 2021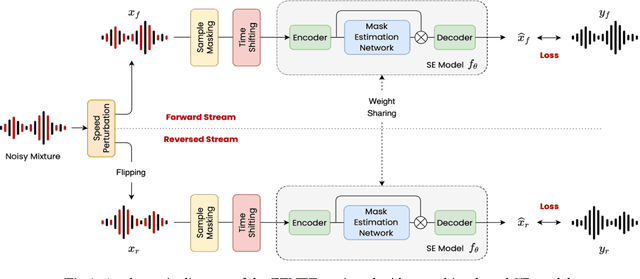
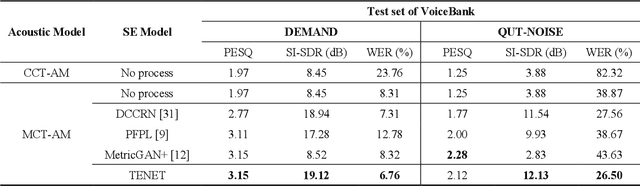
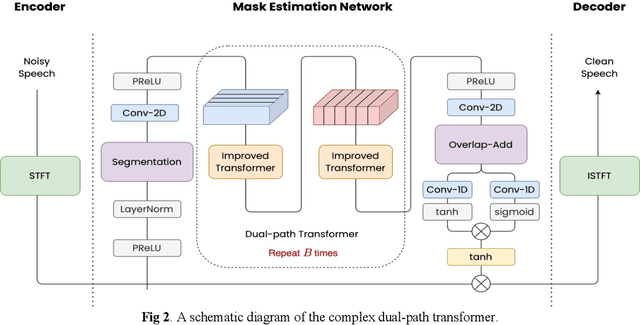
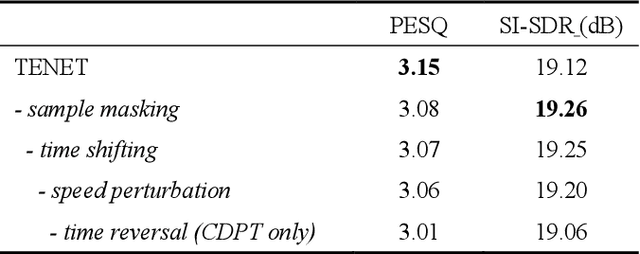
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.
Speech enhancement guided by contextual articulatory information
Nov 15, 2020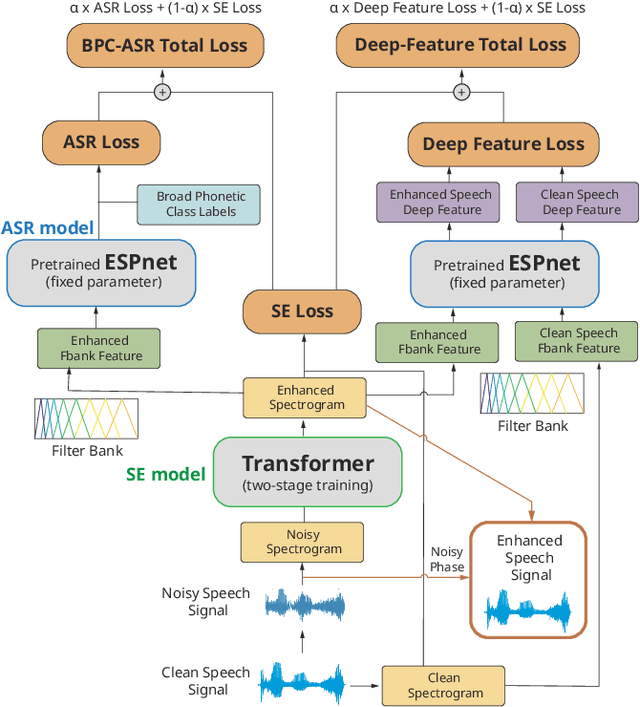
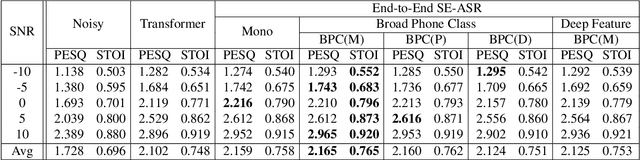
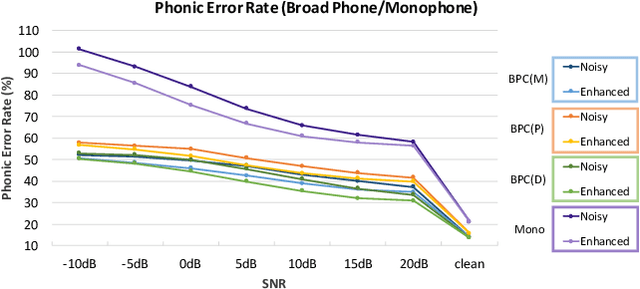
Previous studies have confirmed the effectiveness of leveraging articulatory information to attain improved speech enhancement (SE) performance. By augmenting the original acoustic features with the place/manner of articulatory features, the SE process can be guided to consider the articulatory properties of the input speech when performing enhancement. Hence, we believe that the contextual information of articulatory attributes should include useful information and can further benefit SE. In this study, we propose an SE system that incorporates contextual articulatory information; such information is obtained using broad phone class (BPC) end-to-end automatic speech recognition (ASR). Meanwhile, two training strategies are developed to train the SE system based on the BPC-based ASR: multitask-learning and deep-feature training strategies. Experimental results on the TIMIT dataset confirm that the contextual articulatory information facilitates an SE system in achieving better results. Moreover, in contrast to another SE system that is trained with monophonic ASR, the BPC-based ASR (providing contextual articulatory information) can improve the SE performance more effectively under different signal-to-noise ratios(SNR).
Incorporating Broad Phonetic Information for Speech Enhancement
Aug 13, 2020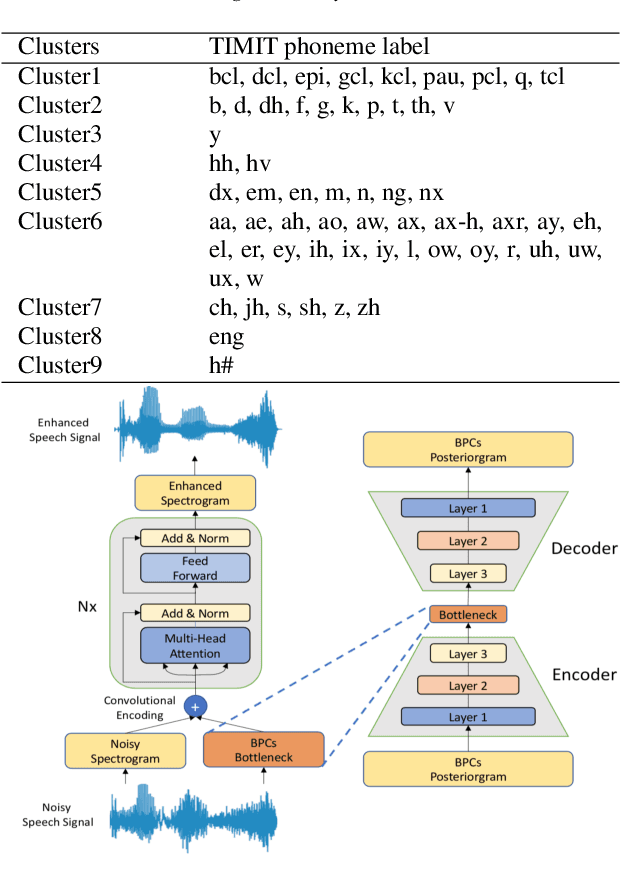
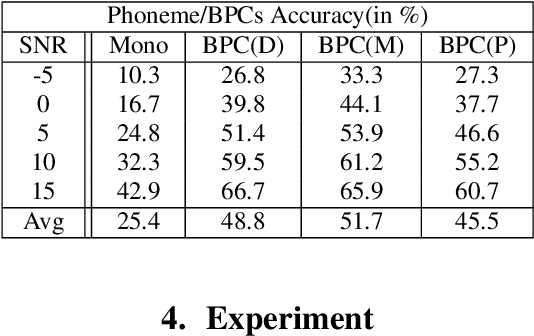
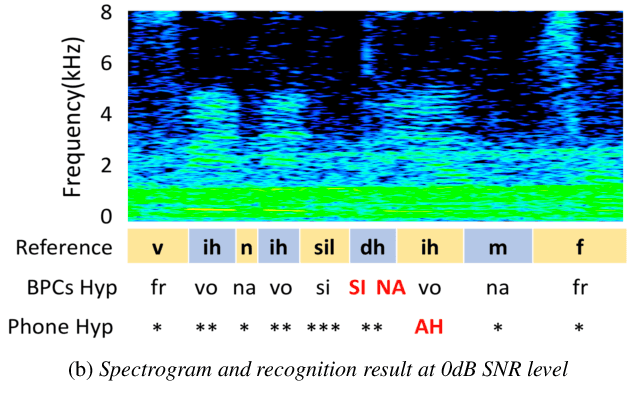

In noisy conditions, knowing speech contents facilitates listeners to more effectively suppress background noise components and to retrieve pure speech signals. Previous studies have also confirmed the benefits of incorporating phonetic information in a speech enhancement (SE) system to achieve better denoising performance. To obtain the phonetic information, we usually prepare a phoneme-based acoustic model, which is trained using speech waveforms and phoneme labels. Despite performing well in normal noisy conditions, when operating in very noisy conditions, however, the recognized phonemes may be erroneous and thus misguide the SE process. To overcome the limitation, this study proposes to incorporate the broad phonetic class (BPC) information into the SE process. We have investigated three criteria to build the BPC, including two knowledge-based criteria: place and manner of articulatory and one data-driven criterion. Moreover, the recognition accuracies of BPCs are much higher than that of phonemes, thus providing more accurate phonetic information to guide the SE process under very noisy conditions. Experimental results demonstrate that the proposed SE with the BPC information framework can achieve notable performance improvements over the baseline system and an SE system using monophonic information in terms of both speech quality intelligibility on the TIMIT dataset.
Distributed Microphone Speech Enhancement based on Deep Learning
Nov 22, 2019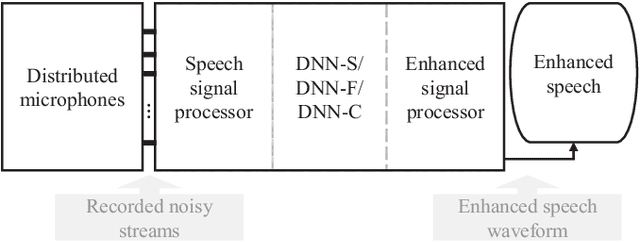

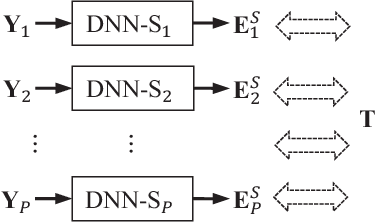
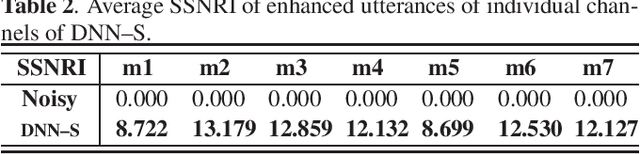
Speech-related applications deliver inferior performance in complex noise environments. Therefore, this study primarily addresses this problem by introducing speech-enhancement (SE) systems based on deep neural networks (DNNs) applied to a distributed microphone architecture. The first system constructs a DNN model for each microphone to enhance the recorded noisy speech signal, and the second system combines all the noisy recordings into a large feature structure that is then enhanced through a DNN model. As for the third system, a channel-dependent DNN is first used to enhance the corresponding noisy input, and all the channel-wise enhanced outputs are fed into a DNN fusion model to construct a nearly clean signal. All the three DNN SE systems are operated in the acoustic frequency domain of speech signals in a diffuse-noise field environment. Evaluation experiments were conducted on the Taiwan Mandarin Hearing in Noise Test (TMHINT) database, and the results indicate that all the three DNN-based SE systems provide the original noise-corrupted signals with improved speech quality and intelligibility, whereas the third system delivers the highest signal-to-noise ratio (SNR) improvement and optimal speech intelligibility.