 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Multifaceted Computer-assisted Pronunciation Training Leveraging Hierarchical Selective State Space Model and Decoupled Cross-entropy Loss
Feb 11, 2025Prior efforts in building computer-assisted pronunciation training (CAPT) systems often treat automatic pronunciation assessment (APA) and mispronunciation detection and diagnosis (MDD) as separate fronts: the former aims to provide multiple pronunciation aspect scores across diverse linguistic levels, while the latter focuses instead on pinpointing the precise phonetic pronunciation errors made by non-native language learners. However, it is generally expected that a full-fledged CAPT system should perform both functionalities simultaneously and efficiently. In response to this surging demand, we in this work first propose HMamba, a novel CAPT approach that seamlessly integrates APA and MDD tasks in parallel. In addition, we introduce a novel loss function, decoupled cross-entropy loss (deXent), specifically tailored for MDD to facilitate better-supervised learning for detecting mispronounced phones, thereby enhancing overall performance. A comprehensive set of empirical results on the speechocean762 benchmark dataset demonstrates the effectiveness of our approach on APA. Notably, our proposed approach also yields a considerable improvement in MDD performance over a strong baseline, achieving an F1-score of 63.85%. Our codes are made available at https://github.com/Fuann/hmamba
An Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
Apr 12, 2024



Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
A Hierarchical Context-aware Modeling Approach for Multi-aspect and Multi-granular Pronunciation Assessment
Jun 07, 2023



Automatic Pronunciation Assessment (APA) plays a vital role in Computer-assisted Pronunciation Training (CAPT) when evaluating a second language (L2) learner's speaking proficiency. However, an apparent downside of most de facto methods is that they parallelize the modeling process throughout different speech granularities without accounting for the hierarchical and local contextual relationships among them. In light of this, a novel hierarchical approach is proposed in this paper for multi-aspect and multi-granular APA. Specifically, we first introduce the notion of sup-phonemes to explore more subtle semantic traits of L2 speakers. Second, a depth-wise separable convolution layer is exploited to better encapsulate the local context cues at the sub-word level. Finally, we use a score-restraint attention pooling mechanism to predict the sentence-level scores and optimize the component models with a multitask learning (MTL) framework. Extensive experiments carried out on a publicly-available benchmark dataset, viz. speechocean762, demonstrate the efficacy of our approach in relation to some cutting-edge baselines.
3M: An Effective Multi-view, Multi-granularity, and Multi-aspect Modeling Approach to English Pronunciation Assessment
Aug 19, 2022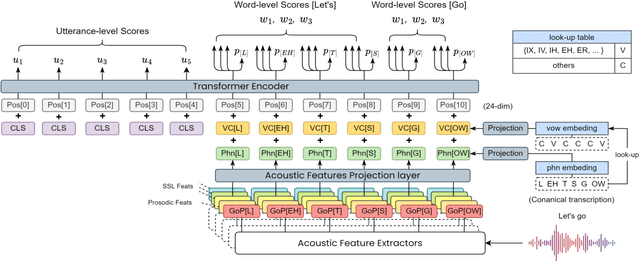
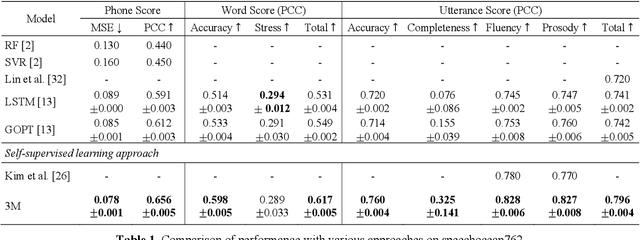
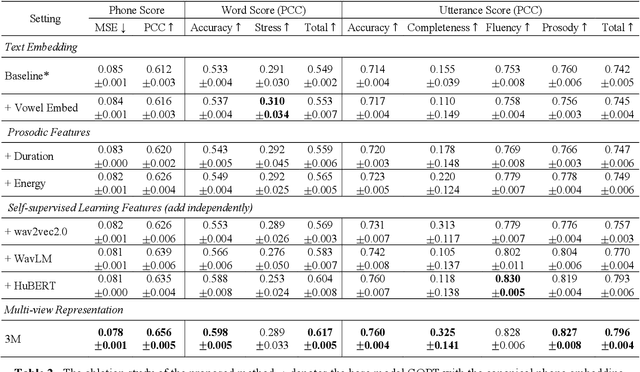
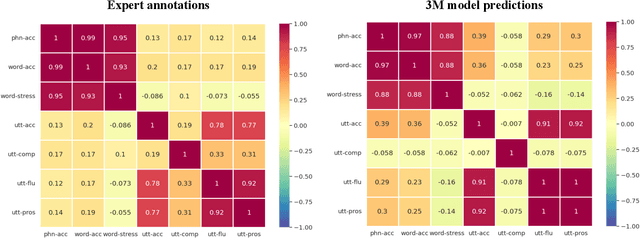
As an indispensable ingredient of computer-assisted pronunciation training (CAPT), automatic pronunciation assessment (APA) plays a pivotal role in aiding self-directed language learners by providing multi-aspect and timely feedback. However, there are at least two potential obstacles that might hinder its performance for practical use. On one hand, most of the studies focus exclusively on leveraging segmental (phonetic)-level features such as goodness of pronunciation (GOP); this, however, may cause a discrepancy of feature granularity when performing suprasegmental (prosodic)-level pronunciation assessment. On the other hand, automatic pronunciation assessments still suffer from the lack of large-scale labeled speech data of non-native speakers, which inevitably limits the performance of pronunciation assessment. In this paper, we tackle these problems by integrating multiple prosodic and phonological features to provide a multi-view, multi-granularity, and multi-aspect (3M) pronunciation modeling. Specifically, we augment GOP with prosodic and self-supervised learning (SSL) features, and meanwhile develop a vowel/consonant positional embedding for a more phonology-aware automatic pronunciation assessment. A series of experiments conducted on the publicly-available speechocean762 dataset show that our approach can obtain significant improvements on several assessment granularities in comparison with previous work, especially on the assessment of speaking fluency and speech prosody.
Maximum F1-score training for end-to-end mispronunciation detection and diagnosis of L2 English speech
Aug 31, 2021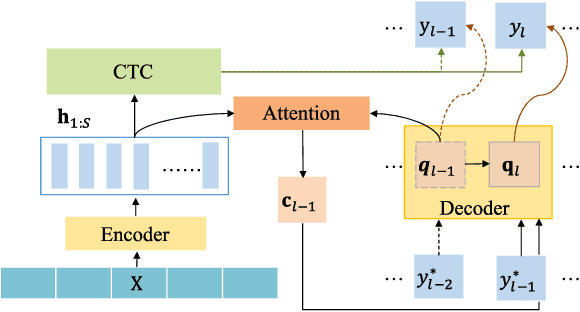


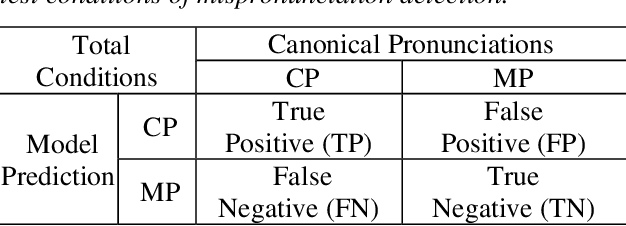
End-to-end (E2E) neural models are increasingly attracting attention as a promising modeling approach for mispronunciation detection and diagnosis (MDD). Typically, these models are trained by optimizing a cross-entropy criterion, which corresponds to improving the log-likelihood of the training data. However, there is a discrepancy between the objectives of model training and the MDD evaluation, since the performance of an MDD model is commonly evaluated in terms of F1-score instead of word error rate (WER). In view of this, we in this paper explore the use of a discriminative objective function for training E2E MDD models, which aims to maximize the expected F1-score directly. To further facilitate maximum F1-score training, we randomly perturb fractions of the labels of phonetic confusing pairs in the training utterances of L2 (second language) learners to generate artificial pronunciation error patterns for data augmentation. A series of experiments conducted on the L2-ARCTIC dataset show that our proposed method can yield considerable performance improvements in relation to some state-of-the-art E2E MDD approaches and the conventional GOP method.
Towards Robust Mispronunciation Detection and Diagnosis for L2 English Learners with Accent-Modulating Methods
Aug 26, 2021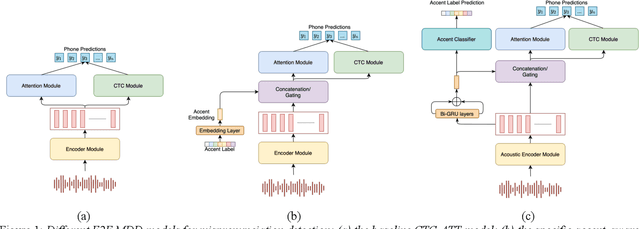
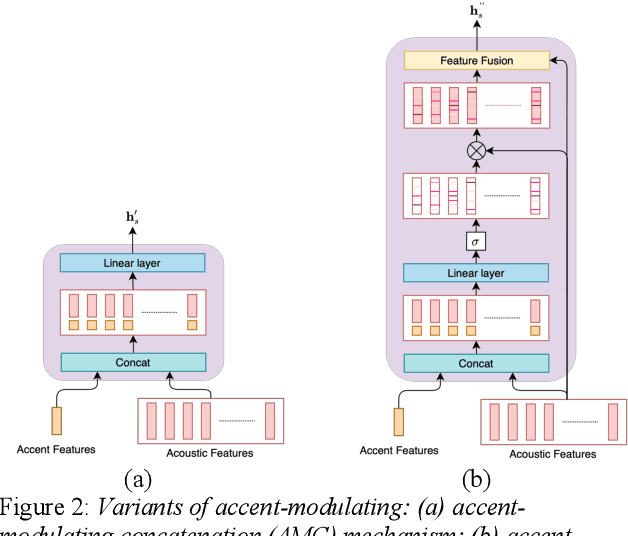
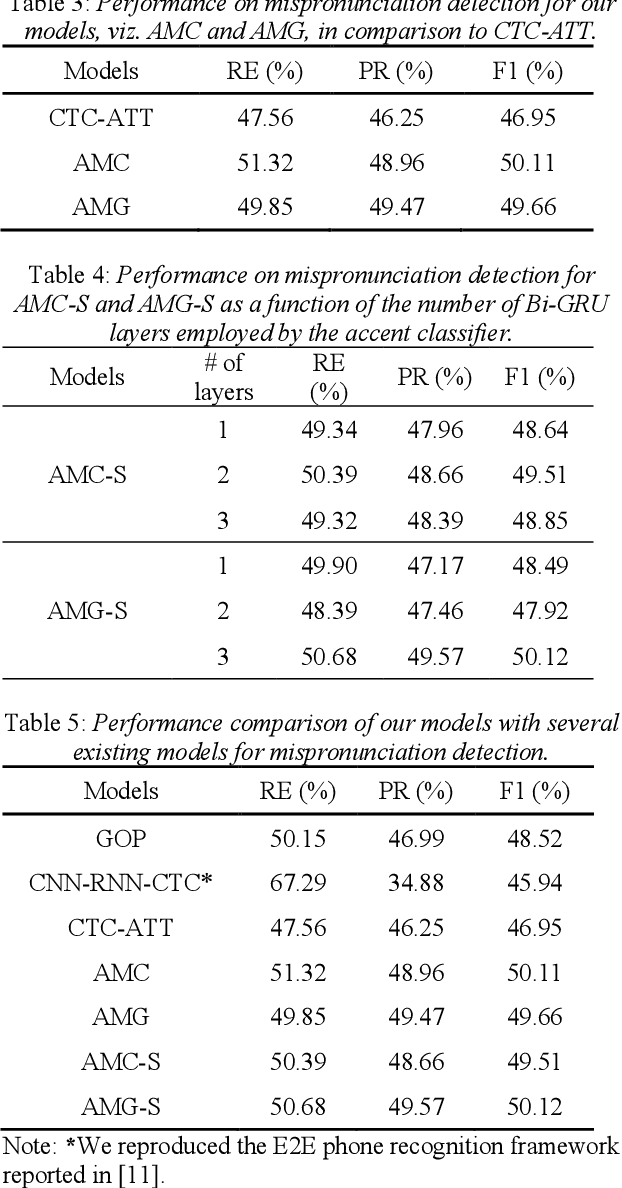
With the acceleration of globalization, more and more people are willing or required to learn second languages (L2). One of the major remaining challenges facing current mispronunciation and diagnosis (MDD) models for use in computer-assisted pronunciation training (CAPT) is to handle speech from L2 learners with a diverse set of accents. In this paper, we set out to mitigate the adverse effects of accent variety in building an L2 English MDD system with end-to-end (E2E) neural models. To this end, we first propose an effective modeling framework that infuses accent features into an E2E MDD model, thereby making the model more accent-aware. Going a step further, we design and present disparate accent-aware modules to perform accent-aware modulation of acoustic features in a fine-grained manner, so as to enhance the discriminating capability of the resulting MDD model. Extensive sets of experiments conducted on the L2-ARCTIC benchmark dataset show the merits of our MDD model, in comparison to some existing E2E-based strong baselines and the celebrated pronunciation scoring based method.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021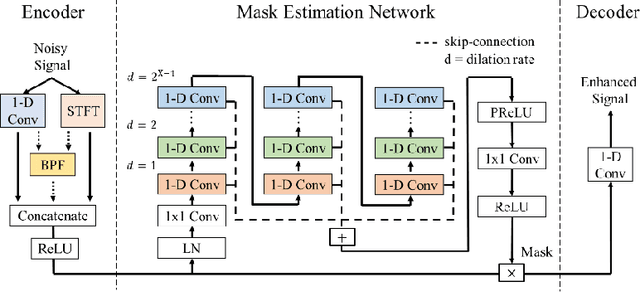
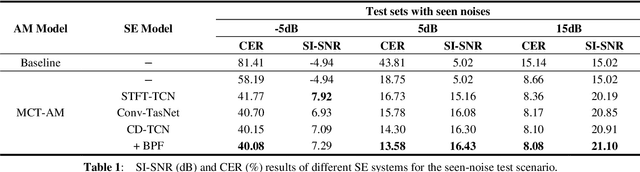
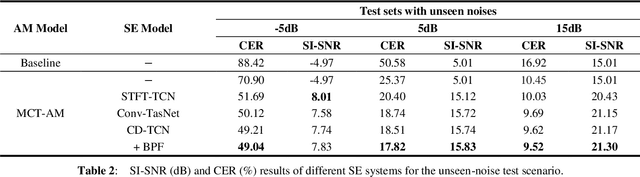
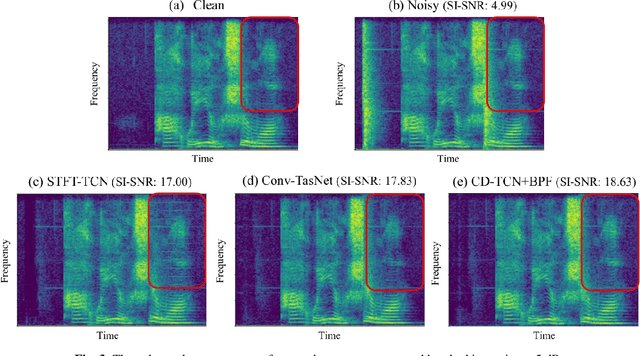
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 08, 2021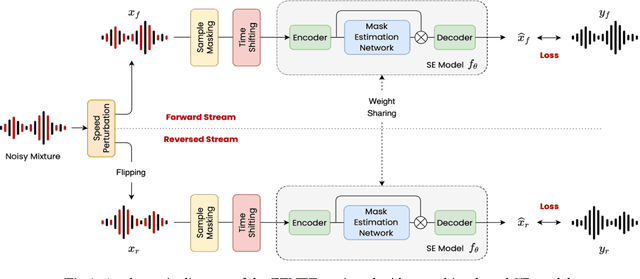
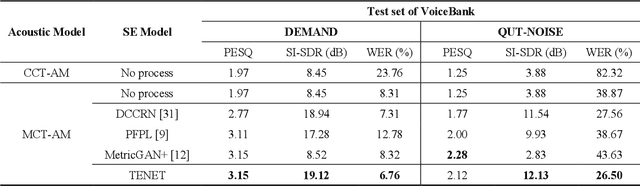
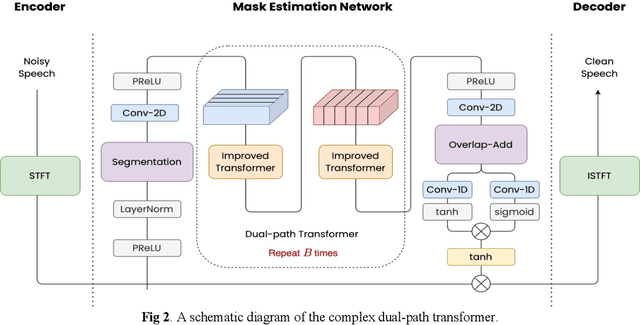
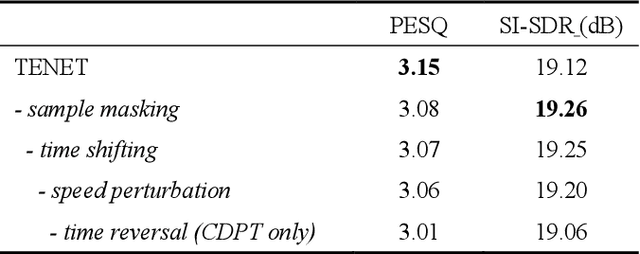
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 20, 2021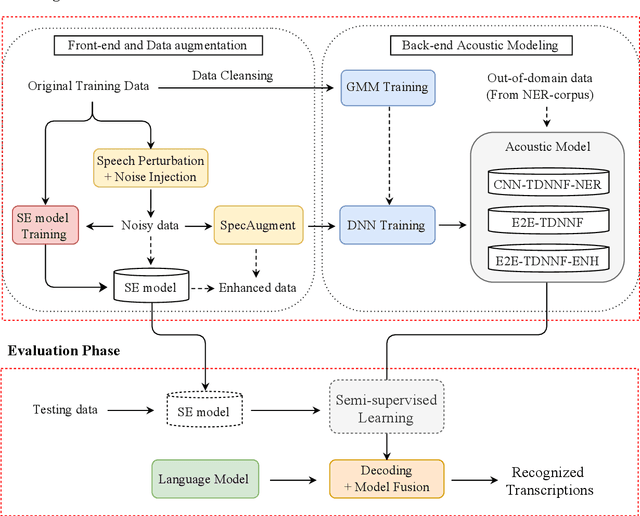
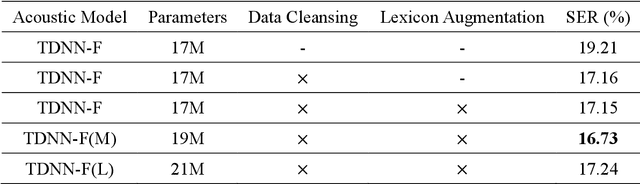
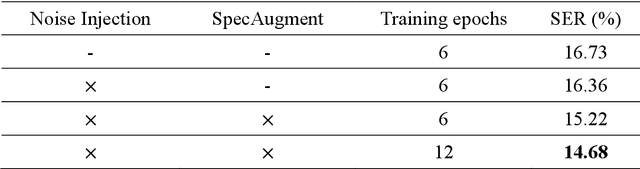
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
The NTNU System at the Interspeech 2020 Non-Native Children's Speech ASR Challenge
Jun 02, 2020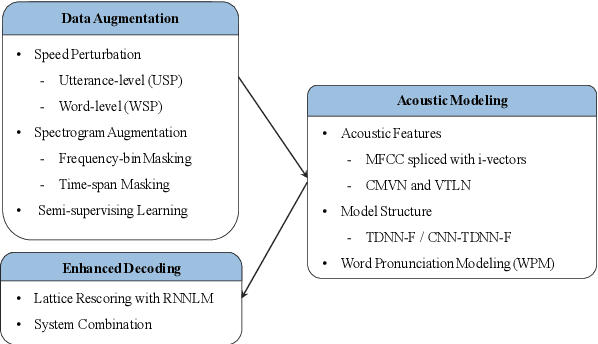
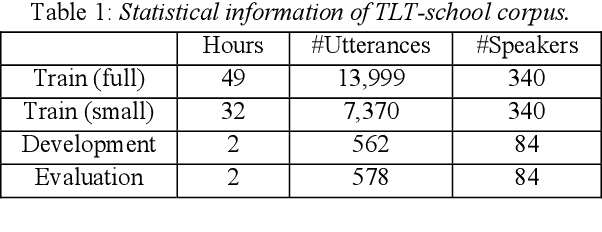
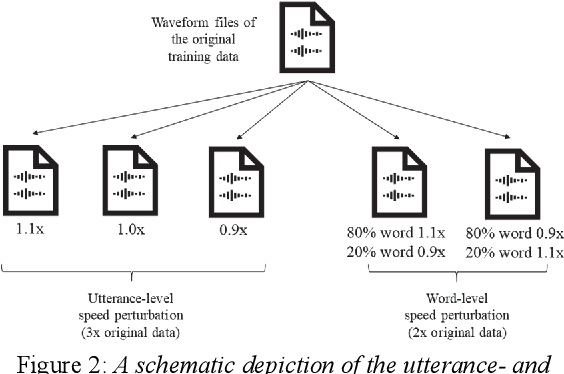
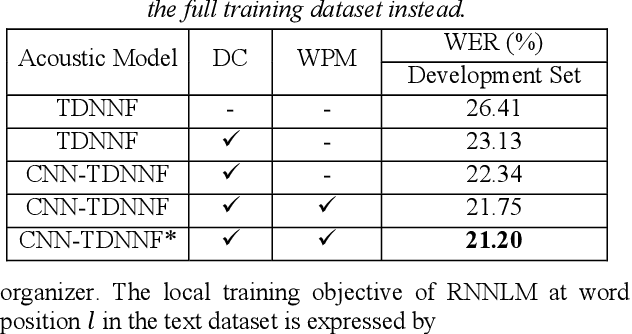
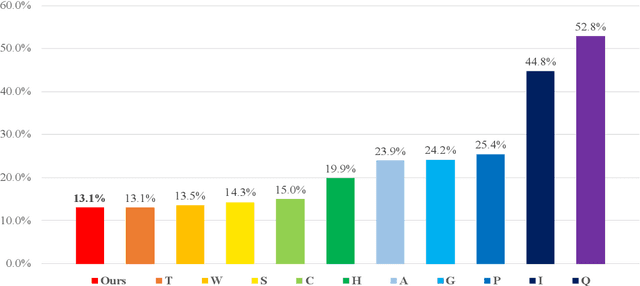
This paper describes the NTNU ASR system participating in the Interspeech 2020 Non-Native Children's Speech ASR Challenge supported by the SIG-CHILD group of ISCA. This ASR shared task is made much more challenging due to the coexisting diversity of non-native and children speaking characteristics. In the setting of closed-track evaluation, all participants were restricted to develop their systems merely based on the speech and text corpora provided by the organizer. To work around this under-resourced issue, we built our ASR system on top of CNN-TDNNF-based acoustic models, meanwhile harnessing the synergistic power of various data augmentation strategies, including both utterance- and word-level speed perturbation and spectrogram augmentation, alongside a simple yet effective data-cleansing approach. All variants of our ASR system employed an RNN-based language model to rescore the first-pass recognition hypotheses, which was trained solely on the text dataset released by the organizer. Our system with the best configuration came out in second place, resulting in a word error rate (WER) of 17.59 %, while those of the top-performing, second runner-up and official baseline systems are 15.67%, 18.71%, 35.09%, respectively.