 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
Apr 12, 2024



Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
A Hierarchical Context-aware Modeling Approach for Multi-aspect and Multi-granular Pronunciation Assessment
Jun 07, 2023



Automatic Pronunciation Assessment (APA) plays a vital role in Computer-assisted Pronunciation Training (CAPT) when evaluating a second language (L2) learner's speaking proficiency. However, an apparent downside of most de facto methods is that they parallelize the modeling process throughout different speech granularities without accounting for the hierarchical and local contextual relationships among them. In light of this, a novel hierarchical approach is proposed in this paper for multi-aspect and multi-granular APA. Specifically, we first introduce the notion of sup-phonemes to explore more subtle semantic traits of L2 speakers. Second, a depth-wise separable convolution layer is exploited to better encapsulate the local context cues at the sub-word level. Finally, we use a score-restraint attention pooling mechanism to predict the sentence-level scores and optimize the component models with a multitask learning (MTL) framework. Extensive experiments carried out on a publicly-available benchmark dataset, viz. speechocean762, demonstrate the efficacy of our approach in relation to some cutting-edge baselines.
3M: An Effective Multi-view, Multi-granularity, and Multi-aspect Modeling Approach to English Pronunciation Assessment
Aug 19, 2022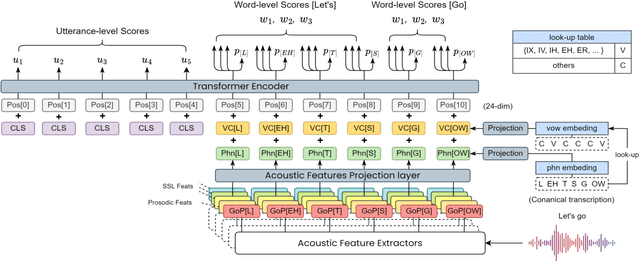
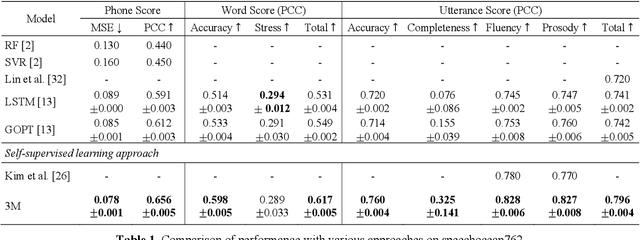
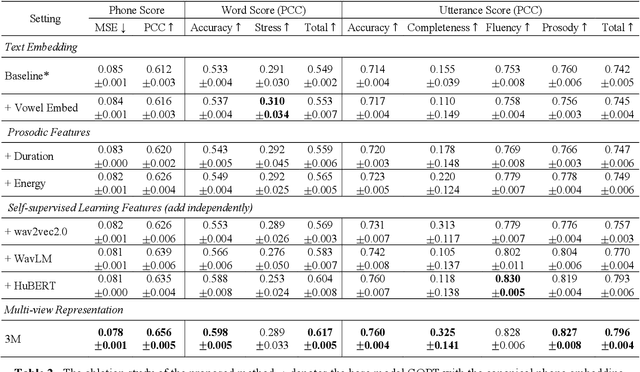
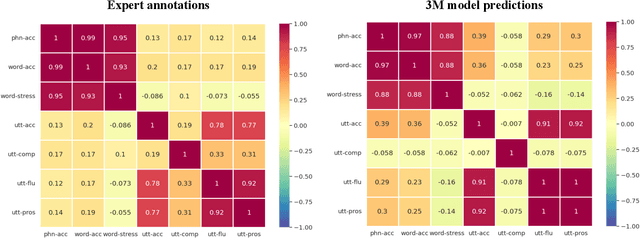
As an indispensable ingredient of computer-assisted pronunciation training (CAPT), automatic pronunciation assessment (APA) plays a pivotal role in aiding self-directed language learners by providing multi-aspect and timely feedback. However, there are at least two potential obstacles that might hinder its performance for practical use. On one hand, most of the studies focus exclusively on leveraging segmental (phonetic)-level features such as goodness of pronunciation (GOP); this, however, may cause a discrepancy of feature granularity when performing suprasegmental (prosodic)-level pronunciation assessment. On the other hand, automatic pronunciation assessments still suffer from the lack of large-scale labeled speech data of non-native speakers, which inevitably limits the performance of pronunciation assessment. In this paper, we tackle these problems by integrating multiple prosodic and phonological features to provide a multi-view, multi-granularity, and multi-aspect (3M) pronunciation modeling. Specifically, we augment GOP with prosodic and self-supervised learning (SSL) features, and meanwhile develop a vowel/consonant positional embedding for a more phonology-aware automatic pronunciation assessment. A series of experiments conducted on the publicly-available speechocean762 dataset show that our approach can obtain significant improvements on several assessment granularities in comparison with previous work, especially on the assessment of speaking fluency and speech prosody.