 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Modality Limitations: A Unified MLLM Approach to Automated Speaking Assessment with Effective Curriculum Learning
Aug 18, 2025Traditional Automated Speaking Assessment (ASA) systems exhibit inherent modality limitations: text-based approaches lack acoustic information while audio-based methods miss semantic context. Multimodal Large Language Models (MLLM) offer unprecedented opportunities for comprehensive ASA by simultaneously processing audio and text within unified frameworks. This paper presents a very first systematic study of MLLM for comprehensive ASA, demonstrating the superior performance of MLLM across the aspects of content and language use . However, assessment on the delivery aspect reveals unique challenges, which is deemed to require specialized training strategies. We thus propose Speech-First Multimodal Training (SFMT), leveraging a curriculum learning principle to establish more robust modeling foundations of speech before cross-modal synergetic fusion. A series of experiments on a benchmark dataset show MLLM-based systems can elevate the holistic assessment performance from a PCC value of 0.783 to 0.846. In particular, SFMT excels in the evaluation of the delivery aspect, achieving an absolute accuracy improvement of 4% over conventional training approaches, which also paves a new avenue for ASA.
An Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
Apr 12, 2024



Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
A Hierarchical Context-aware Modeling Approach for Multi-aspect and Multi-granular Pronunciation Assessment
Jun 07, 2023



Automatic Pronunciation Assessment (APA) plays a vital role in Computer-assisted Pronunciation Training (CAPT) when evaluating a second language (L2) learner's speaking proficiency. However, an apparent downside of most de facto methods is that they parallelize the modeling process throughout different speech granularities without accounting for the hierarchical and local contextual relationships among them. In light of this, a novel hierarchical approach is proposed in this paper for multi-aspect and multi-granular APA. Specifically, we first introduce the notion of sup-phonemes to explore more subtle semantic traits of L2 speakers. Second, a depth-wise separable convolution layer is exploited to better encapsulate the local context cues at the sub-word level. Finally, we use a score-restraint attention pooling mechanism to predict the sentence-level scores and optimize the component models with a multitask learning (MTL) framework. Extensive experiments carried out on a publicly-available benchmark dataset, viz. speechocean762, demonstrate the efficacy of our approach in relation to some cutting-edge baselines.
3M: An Effective Multi-view, Multi-granularity, and Multi-aspect Modeling Approach to English Pronunciation Assessment
Aug 19, 2022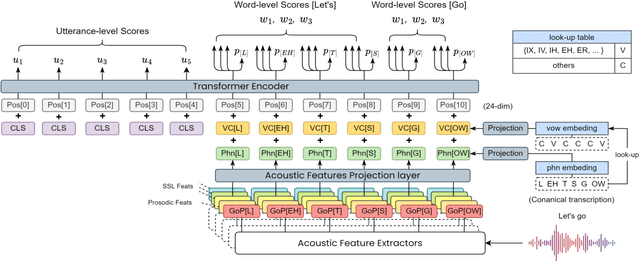
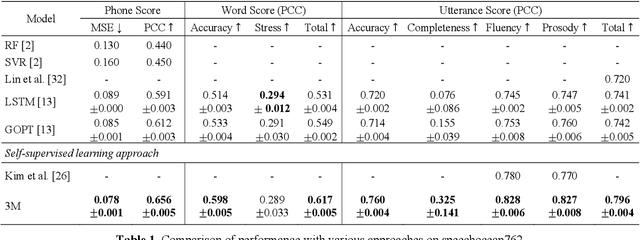
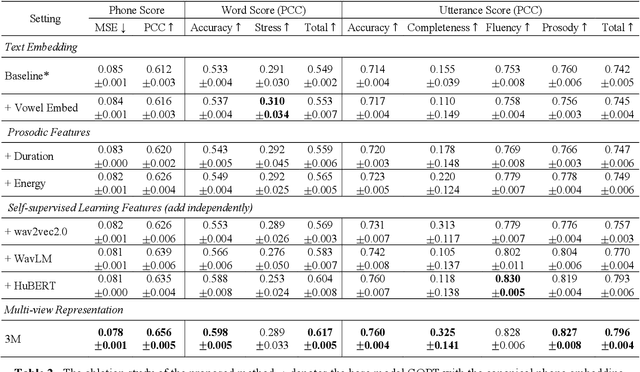
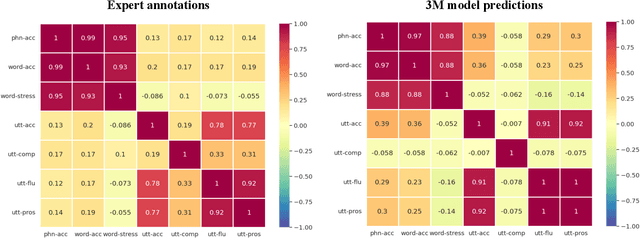
As an indispensable ingredient of computer-assisted pronunciation training (CAPT), automatic pronunciation assessment (APA) plays a pivotal role in aiding self-directed language learners by providing multi-aspect and timely feedback. However, there are at least two potential obstacles that might hinder its performance for practical use. On one hand, most of the studies focus exclusively on leveraging segmental (phonetic)-level features such as goodness of pronunciation (GOP); this, however, may cause a discrepancy of feature granularity when performing suprasegmental (prosodic)-level pronunciation assessment. On the other hand, automatic pronunciation assessments still suffer from the lack of large-scale labeled speech data of non-native speakers, which inevitably limits the performance of pronunciation assessment. In this paper, we tackle these problems by integrating multiple prosodic and phonological features to provide a multi-view, multi-granularity, and multi-aspect (3M) pronunciation modeling. Specifically, we augment GOP with prosodic and self-supervised learning (SSL) features, and meanwhile develop a vowel/consonant positional embedding for a more phonology-aware automatic pronunciation assessment. A series of experiments conducted on the publicly-available speechocean762 dataset show that our approach can obtain significant improvements on several assessment granularities in comparison with previous work, especially on the assessment of speaking fluency and speech prosody.
Improving End-To-End Modeling for Mispronunciation Detection with Effective Augmentation Mechanisms
Oct 17, 2021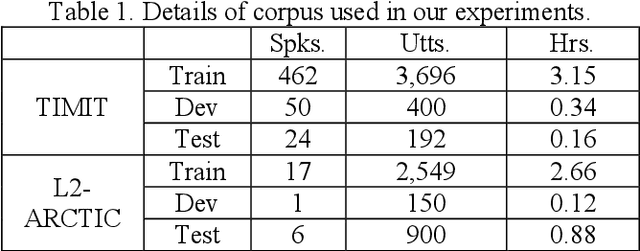
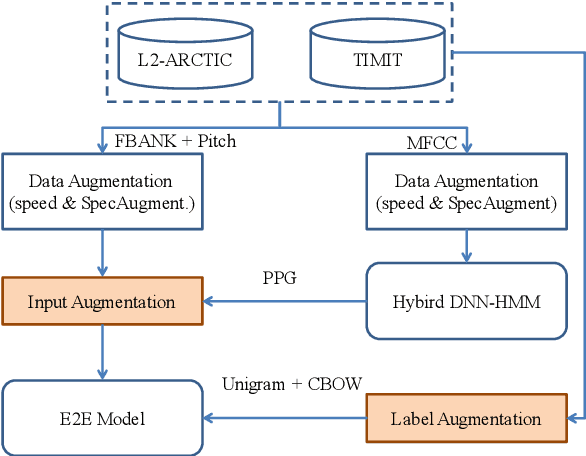
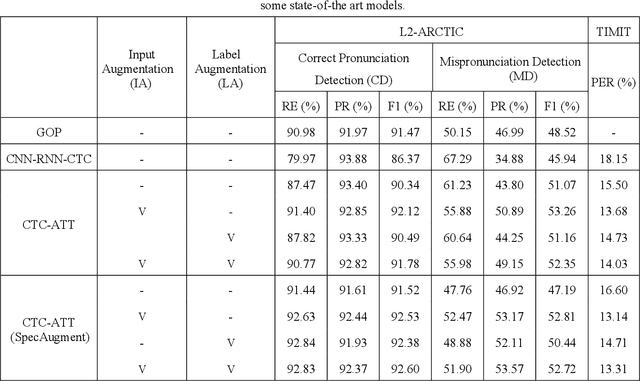
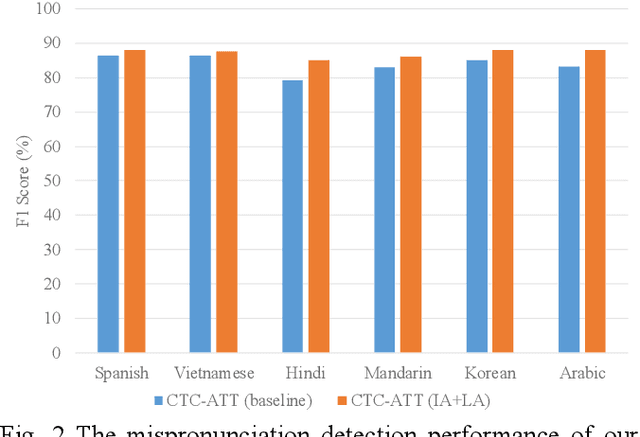
Recently, end-to-end (E2E) models, which allow to take spectral vector sequences of L2 (second-language) learners' utterances as input and produce the corresponding phone-level sequences as output, have attracted much research attention in developing mispronunciation detection (MD) systems. However, due to the lack of sufficient labeled speech data of L2 speakers for model estimation, E2E MD models are prone to overfitting in relation to conventional ones that are built on DNN-HMM acoustic models. To alleviate this critical issue, we in this paper propose two modeling strategies to enhance the discrimination capability of E2E MD models, each of which can implicitly leverage the phonetic and phonological traits encoded in a pretrained acoustic model and contained within reference transcripts of the training data, respectively. The first one is input augmentation, which aims to distill knowledge about phonetic discrimination from a DNN-HMM acoustic model. The second one is label augmentation, which manages to capture more phonological patterns from the transcripts of training data. A series of empirical experiments conducted on the L2-ARCTIC English dataset seem to confirm the efficacy of our E2E MD model when compared to some top-of-the-line E2E MD models and a classic pronunciation-scoring based method built on a DNN-HMM acoustic model.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 20, 2021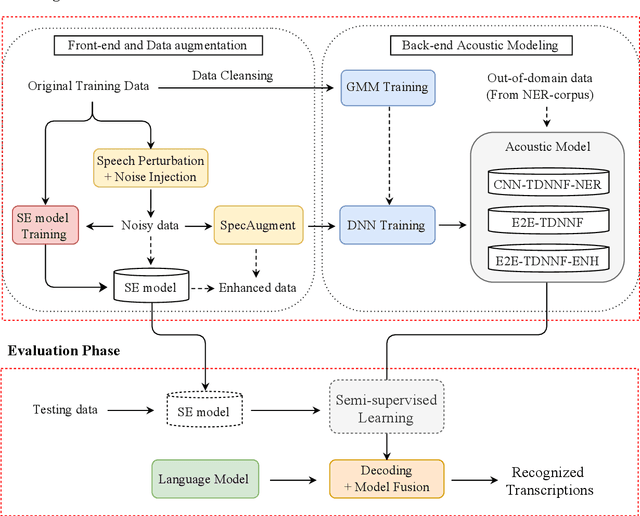
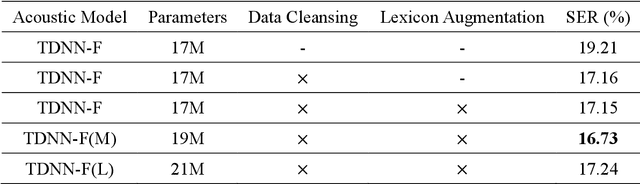
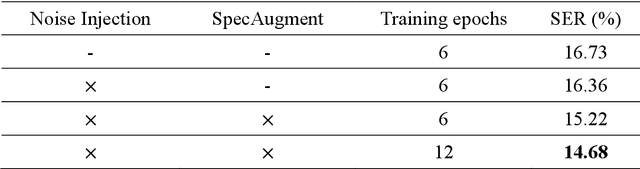
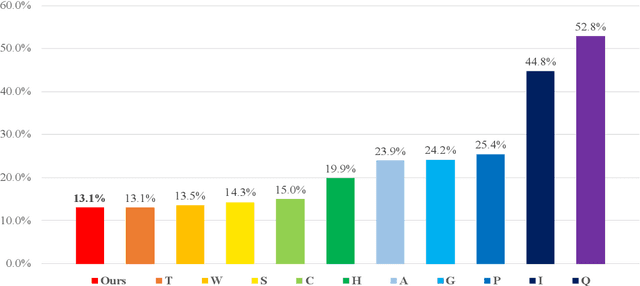
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.