 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NTNU System for Formosa Speech Recognition Challenge 2020
Apr 20, 2021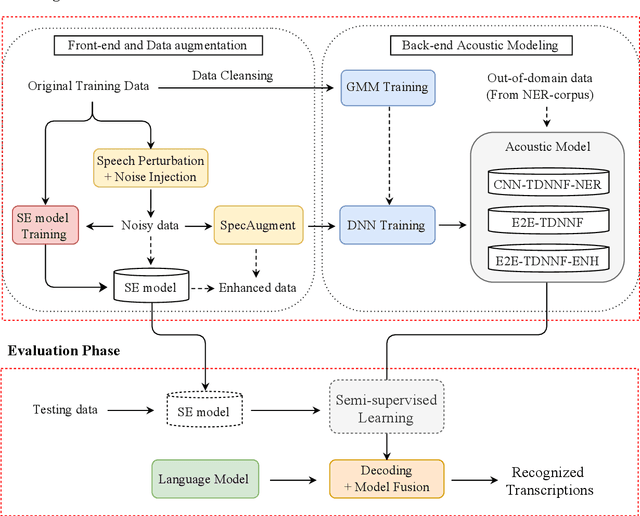
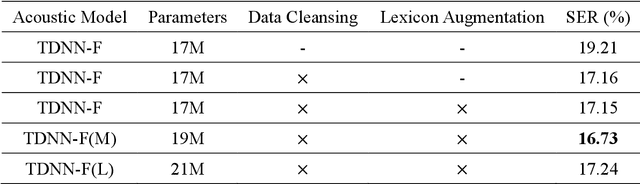
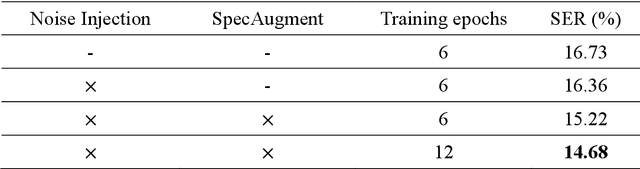
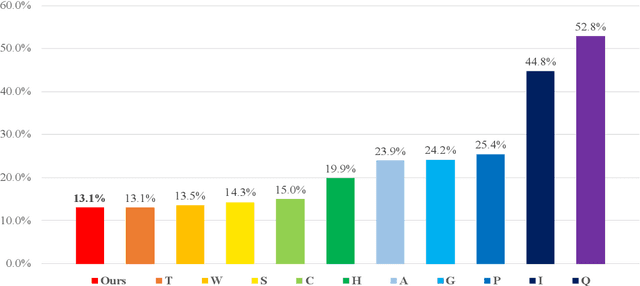
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
The NTNU System at the Interspeech 2020 Non-Native Children's Speech ASR Challenge
Jun 02, 2020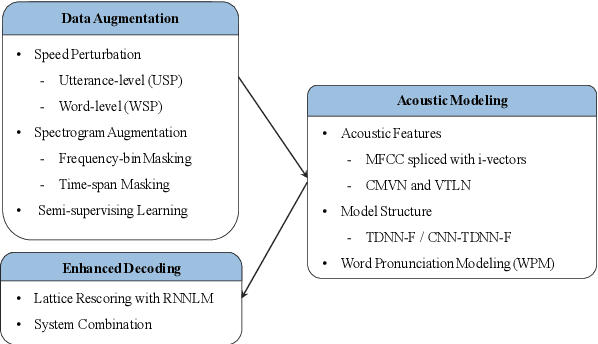
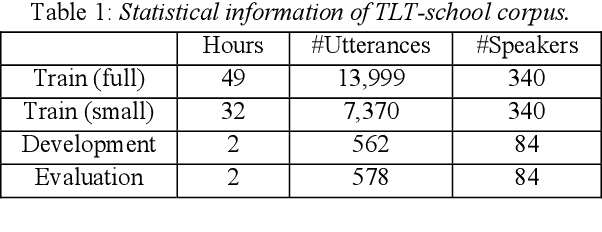
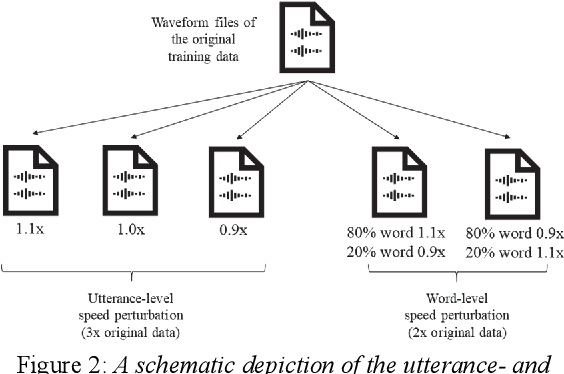
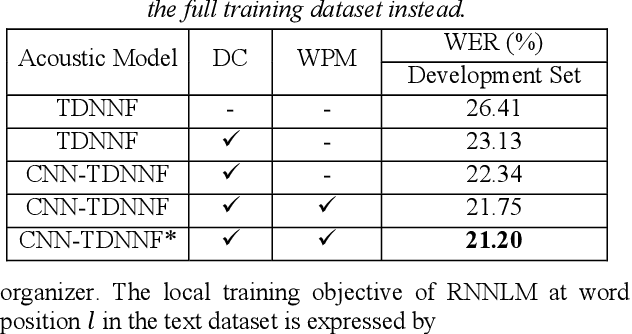
This paper describes the NTNU ASR system participating in the Interspeech 2020 Non-Native Children's Speech ASR Challenge supported by the SIG-CHILD group of ISCA. This ASR shared task is made much more challenging due to the coexisting diversity of non-native and children speaking characteristics. In the setting of closed-track evaluation, all participants were restricted to develop their systems merely based on the speech and text corpora provided by the organizer. To work around this under-resourced issue, we built our ASR system on top of CNN-TDNNF-based acoustic models, meanwhile harnessing the synergistic power of various data augmentation strategies, including both utterance- and word-level speed perturbation and spectrogram augmentation, alongside a simple yet effective data-cleansing approach. All variants of our ASR system employed an RNN-based language model to rescore the first-pass recognition hypotheses, which was trained solely on the text dataset released by the organizer. Our system with the best configuration came out in second place, resulting in a word error rate (WER) of 17.59 %, while those of the top-performing, second runner-up and official baseline systems are 15.67%, 18.71%, 35.09%, respectively.
An Effective Contextual Language Modeling Framework for Speech Summarization with Augmented Features
Jun 01, 2020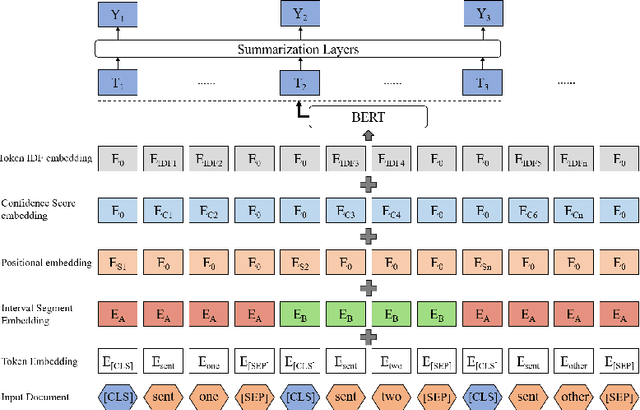
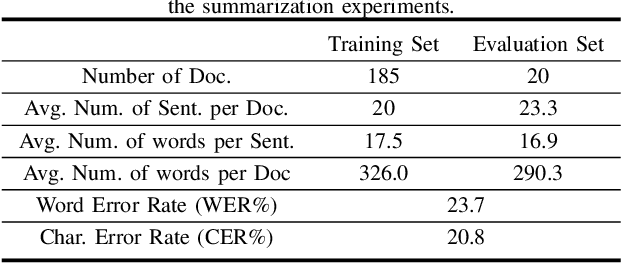
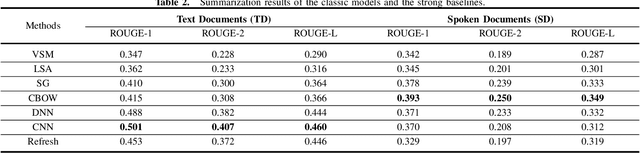
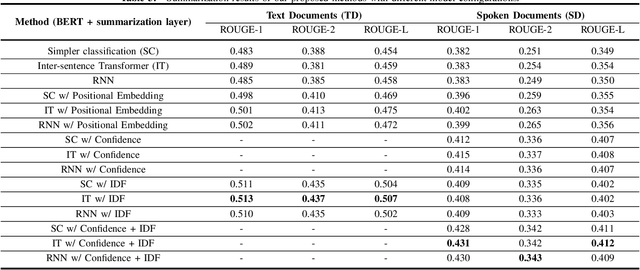
Tremendous amounts of multimedia associated with speech information are driving an urgent need to develop efficient and effective automatic summarization methods. To this end, we have seen rapid progress in applying supervised deep neural network-based methods to extractive speech summarization. More recently, the Bidirectional Encoder Representations from Transformers (BERT) model was proposed and has achieved record-breaking success on many natural language processing (NLP) tasks such as question answering and language understanding. In view of this, we in this paper contextualize and enhance the state-of-the-art BERT-based model for speech summarization, while its contributions are at least three-fold. First, we explore the incorporation of confidence scores into sentence representations to see if such an attempt could help alleviate the negative effects caused by imperfect automatic speech recognition (ASR). Secondly, we also augment the sentence embeddings obtained from BERT with extra structural and linguistic features, such as sentence position and inverse document frequency (IDF) statistics. Finally, we validate the effectiveness of our proposed method on a benchmark dataset, in comparison to several classic and celebrated speech summarization methods.
An Effective End-to-End Modeling Approach for Mispronunciation Detection
May 18, 2020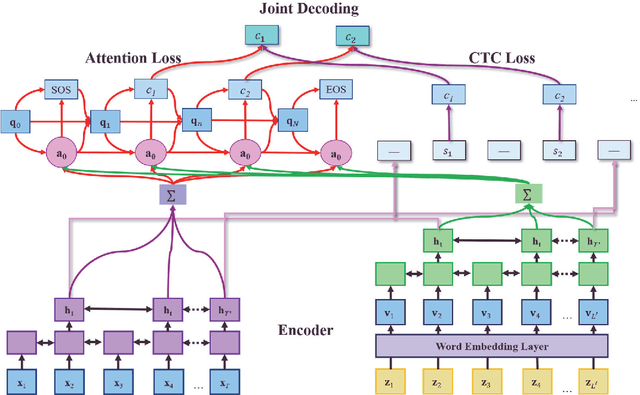
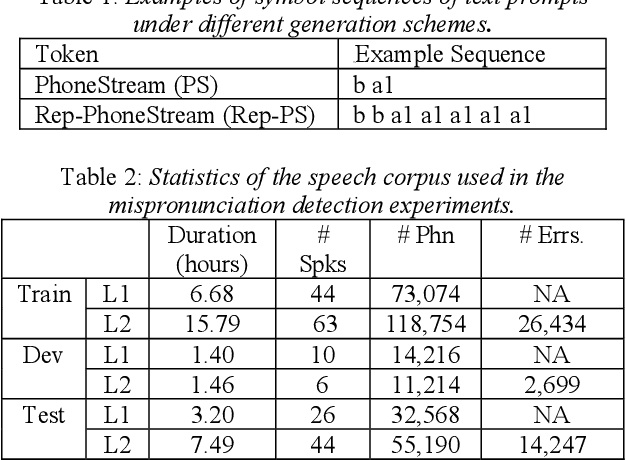
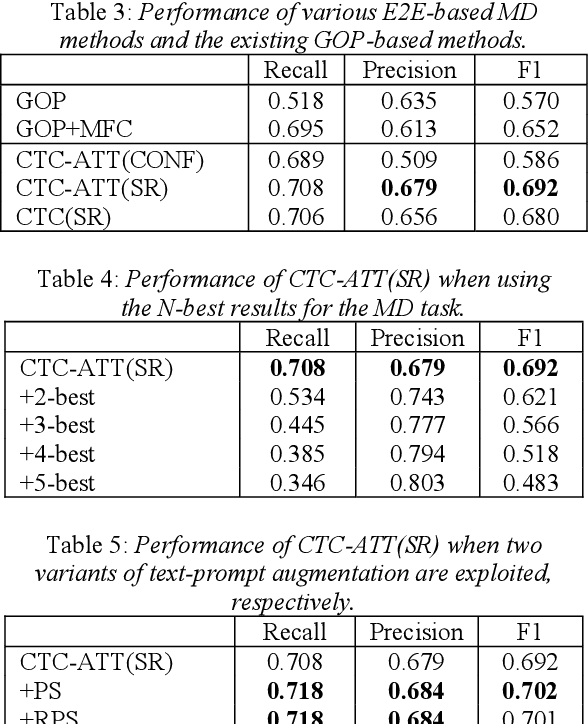
Recently, end-to-end (E2E) automatic speech recognition (ASR) systems have garnered tremendous attention because of their great success and unified modeling paradigms in comparison to conventional hybrid DNN-HMM ASR systems. Despite the widespread adoption of E2E modeling frameworks on ASR, there still is a dearth of work on investigating the E2E frameworks for use in computer-assisted pronunciation learning (CAPT), particularly for Mispronunciation detection (MD). In response, we first present a novel use of hybrid CTCAttention approach to the MD task, taking advantage of the strengths of both CTC and the attention-based model meanwhile getting around the need for phone-level forced alignment. Second, we perform input augmentation with text prompt information to make the resulting E2E model more tailored for the MD task. On the other hand, we adopt two MD decision methods so as to better cooperate with the proposed framework: 1) decision-making based on a recognition confidence measure or 2) simply based on speech recognition results. A series of Mandarin MD experiments demonstrate that our approach not only simplifies the processing pipeline of existing hybrid DNN-HMM systems but also brings about systematic and substantial performance improvements. Furthermore, input augmentation with text prompts seems to hold excellent promise for the E2E-based MD approach.