 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiMRAG: Cim-Aware Domain-Adaptive and Noise-Resilient Retrieval-Augmented Generation for Edge-Based LLMs
Jan 27, 2026Personalized virtual assistants powered by large language models (LLMs) on edge devices are attracting growing attention, with Retrieval-Augmented Generation (RAG) emerging as a key method for personalization by retrieving relevant profile data and generating tailored responses. However, deploying RAG on edge devices faces efficiency hurdles due to the rapid growth of profile data, such as user-LLM interactions and recent updates. While Computing-in-Memory (CiM) architectures mitigate this bottleneck by eliminating data movement between memory and processing units via in-situ operations, they are susceptible to environmental noise that can degrade retrieval precision. This poses a critical issue in dynamic, multi-domain edge-based scenarios (e.g., travel, medicine, and law) where both accuracy and adaptability are paramount. To address these challenges, we propose Task-Oriented Noise-resilient Embedding Learning (TONEL), a framework that improves noise robustness and domain adaptability for RAG in noisy edge environments. TONEL employs a noise-aware projection model to learn task-specific embeddings compatible with CiM hardware constraints, enabling accurate retrieval under noisy conditions. Extensive experiments conducted on personalization benchmarks demonstrate the effectiveness and practicality of our methods relative to strong baselines, especially in task-specific noisy scenarios.
Conversational speech recognition leveraging effective fusion methods for cross-utterance language modeling
Nov 05, 2021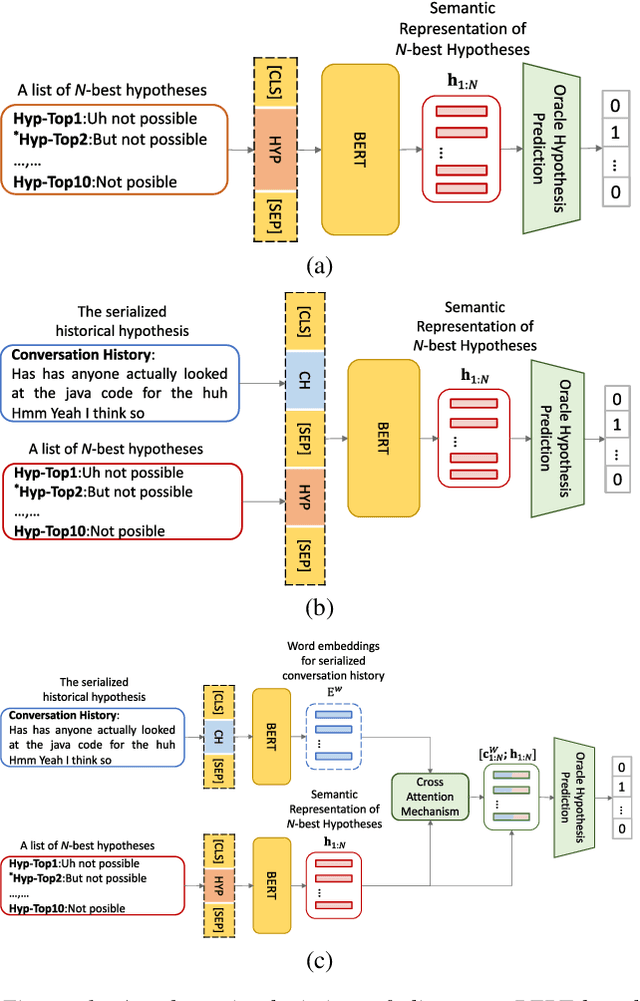
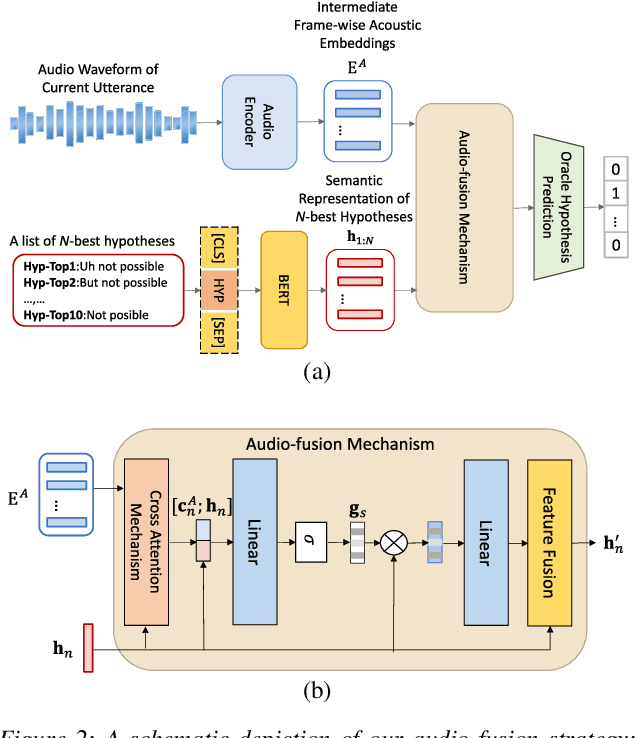

Conversational speech normally is embodied with loose syntactic structures at the utterance level but simultaneously exhibits topical coherence relations across consecutive utterances. Prior work has shown that capturing longer context information with a recurrent neural network or long short-term memory language model (LM) may suffer from the recent bias while excluding the long-range context. In order to capture the long-term semantic interactions among words and across utterances, we put forward disparate conversation history fusion methods for language modeling in automatic speech recognition (ASR) of conversational speech. Furthermore, a novel audio-fusion mechanism is introduced, which manages to fuse and utilize the acoustic embeddings of a current utterance and the semantic content of its corresponding conversation history in a cooperative way. To flesh out our ideas, we frame the ASR N-best hypothesis rescoring task as a prediction problem, leveraging BERT, an iconic pre-trained LM, as the ingredient vehicle to facilitate selection of the oracle hypothesis from a given N-best hypothesis list. Empirical experiments conducted on the AMI benchmark dataset seem to demonstrate the feasibility and efficacy of our methods in relation to some current top-of-line methods.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jul 08, 2021
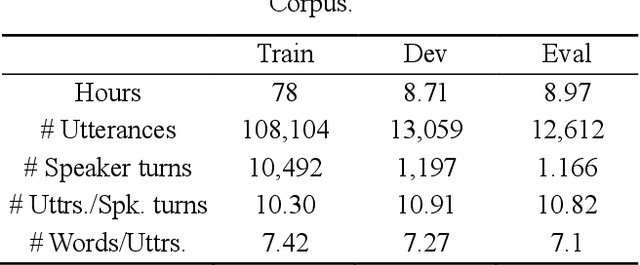
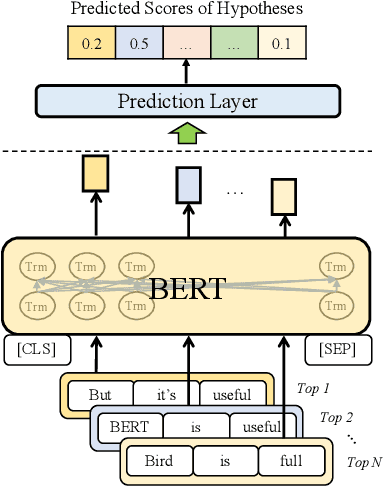
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
The NTNU System for Formosa Speech Recognition Challenge 2020
Apr 20, 2021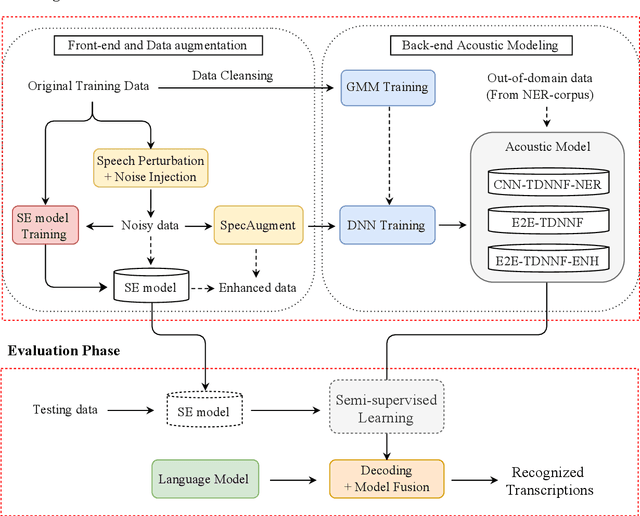
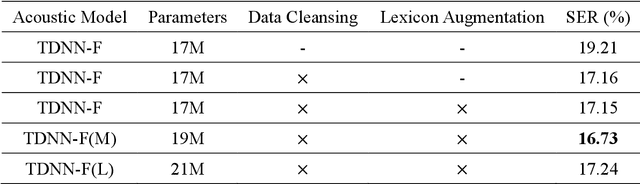
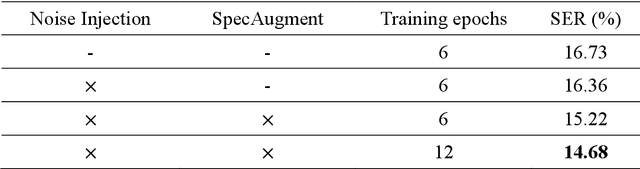
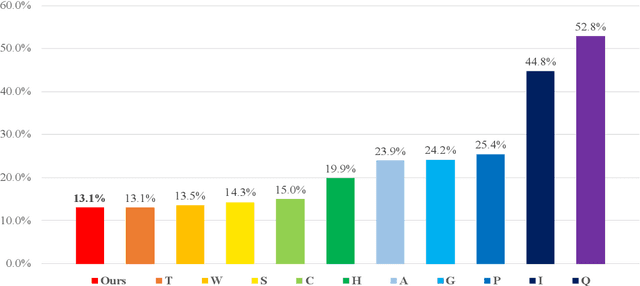
This paper describes the NTNU ASR system participating in the Formosa Speech Recognition Challenge 2020 (FSR-2020) supported by the Formosa Speech in the Wild project (FSW). FSR-2020 aims at fostering the development of Taiwanese speech recognition. Apart from the issues on tonal and dialectical variations of the Taiwanese language, speech artificially contaminated with different types of real-world noise also has to be dealt with in the final test stage; all of these make FSR-2020 much more challenging than before. To work around the under-resourced issue, the main technical aspects of our ASR system include various deep learning techniques, such as transfer learning, semi-supervised learning, front-end speech enhancement and model ensemble, as well as data cleansing and data augmentation conducted on the training data. With the best configuration, our system takes the first place among all participating systems in Track 3.
Innovative Bert-based Reranking Language Models for Speech Recognition
Apr 11, 2021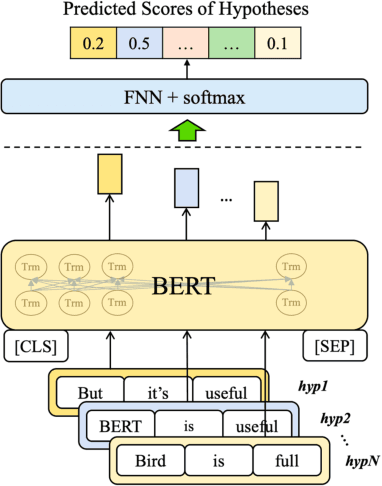

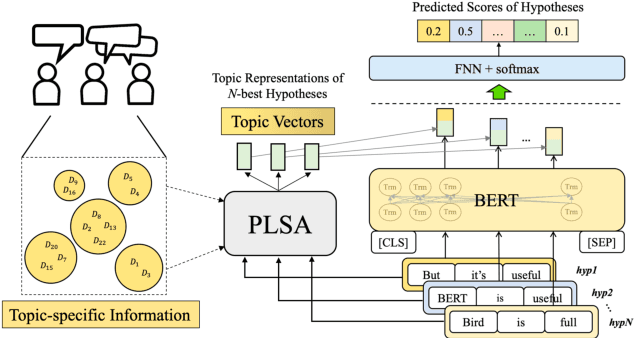
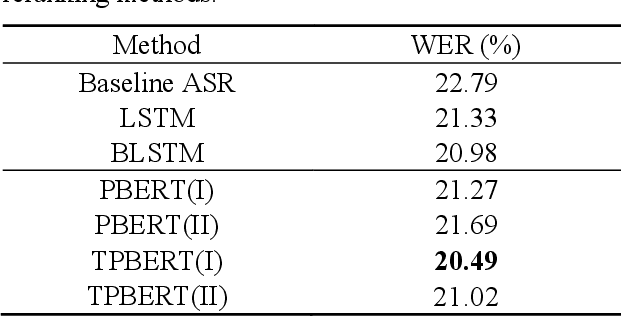
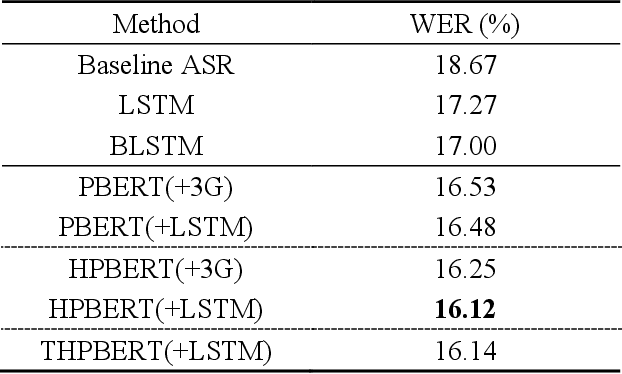
More recently, Bidirectional Encoder Representations from Transformers (BERT) was proposed and has achieved impressive success on many natural language processing (NLP) tasks such as question answering and language understanding, due mainly to its effective pre-training then fine-tuning paradigm as well as strong local contextual modeling ability. In view of the above, this paper presents a novel instantiation of the BERT-based contextualized language models (LMs) for use in reranking of N-best hypotheses produced by automatic speech recognition (ASR). To this end, we frame N-best hypothesis reranking with BERT as a prediction problem, which aims to predict the oracle hypothesis that has the lowest word error rate (WER) given the N-best hypotheses (denoted by PBERT). In particular, we also explore to capitalize on task-specific global topic information in an unsupervised manner to assist PBERT in N-best hypothesis reranking (denoted by TPBERT). Extensive experiments conducted on the AMI benchmark corpus demonstrate the effectiveness and feasibility of our methods in comparison to the conventional autoregressive models like the recurrent neural network (RNN) and a recently proposed method that employed BERT to compute pseudo-log-likelihood (PLL) scores for N-best hypothesis reranking.