 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational speech recognition leveraging effective fusion methods for cross-utterance language modeling
Paper and Code
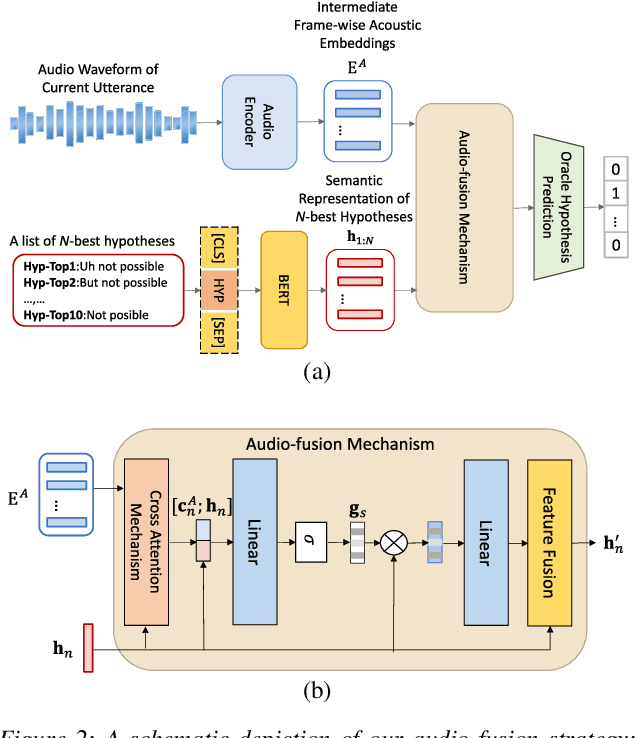
Nov 05, 2021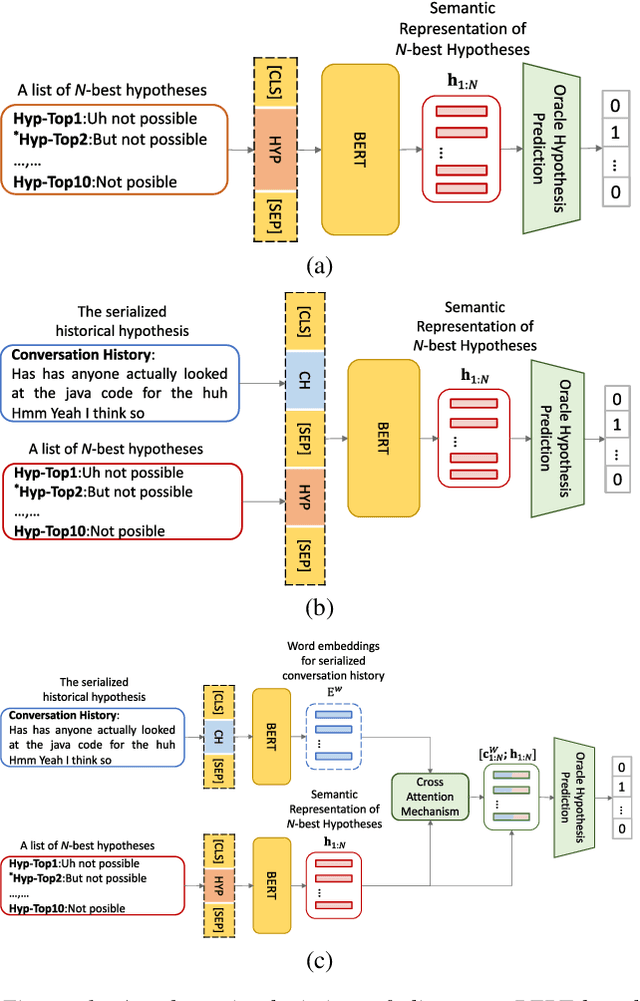

Conversational speech normally is embodied with loose syntactic structures at the utterance level but simultaneously exhibits topical coherence relations across consecutive utterances. Prior work has shown that capturing longer context information with a recurrent neural network or long short-term memory language model (LM) may suffer from the recent bias while excluding the long-range context. In order to capture the long-term semantic interactions among words and across utterances, we put forward disparate conversation history fusion methods for language modeling in automatic speech recognition (ASR) of conversational speech. Furthermore, a novel audio-fusion mechanism is introduced, which manages to fuse and utilize the acoustic embeddings of a current utterance and the semantic content of its corresponding conversation history in a cooperative way. To flesh out our ideas, we frame the ASR N-best hypothesis rescoring task as a prediction problem, leveraging BERT, an iconic pre-trained LM, as the ingredient vehicle to facilitate selection of the oracle hypothesis from a given N-best hypothesis list. Empirical experiments conducted on the AMI benchmark dataset seem to demonstrate the feasibility and efficacy of our methods in relation to some current top-of-line methods.