 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NTNU System at the Interspeech 2020 Non-Native Children's Speech ASR Challenge
Paper and Code
Jun 02, 2020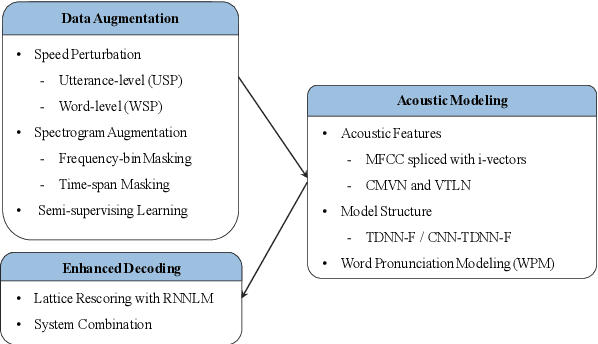
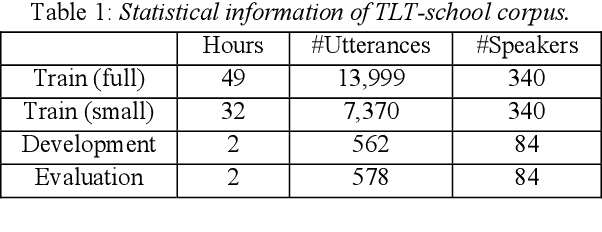
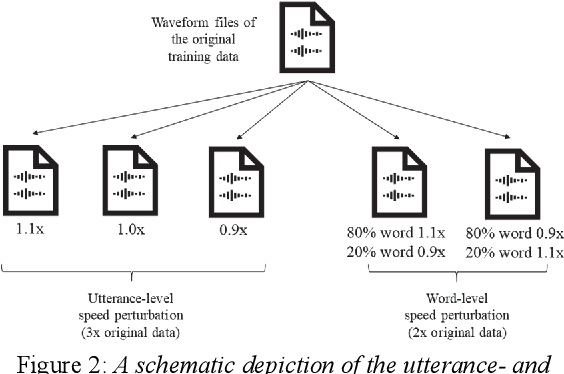
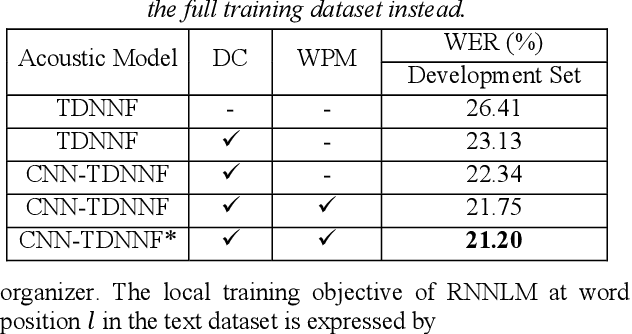
This paper describes the NTNU ASR system participating in the Interspeech 2020 Non-Native Children's Speech ASR Challenge supported by the SIG-CHILD group of ISCA. This ASR shared task is made much more challenging due to the coexisting diversity of non-native and children speaking characteristics. In the setting of closed-track evaluation, all participants were restricted to develop their systems merely based on the speech and text corpora provided by the organizer. To work around this under-resourced issue, we built our ASR system on top of CNN-TDNNF-based acoustic models, meanwhile harnessing the synergistic power of various data augmentation strategies, including both utterance- and word-level speed perturbation and spectrogram augmentation, alongside a simple yet effective data-cleansing approach. All variants of our ASR system employed an RNN-based language model to rescore the first-pass recognition hypotheses, which was trained solely on the text dataset released by the organizer. Our system with the best configuration came out in second place, resulting in a word error rate (WER) of 17.59 %, while those of the top-performing, second runner-up and official baseline systems are 15.67%, 18.71%, 35.09%, respectively.