 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving End-To-End Modeling for Mispronunciation Detection with Effective Augmentation Mechanisms
Paper and Code
Oct 17, 2021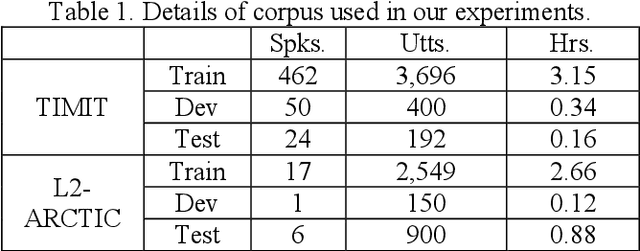
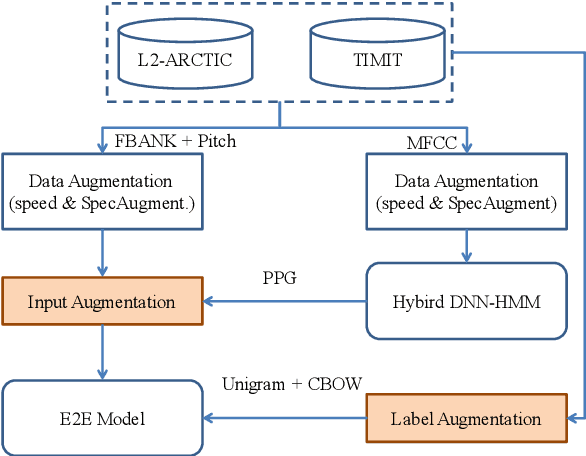
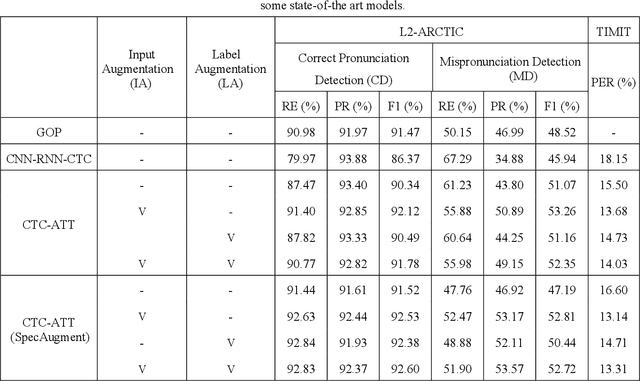
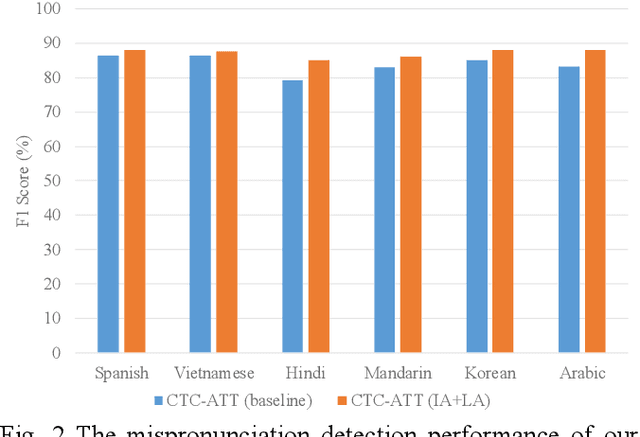
Recently, end-to-end (E2E) models, which allow to take spectral vector sequences of L2 (second-language) learners' utterances as input and produce the corresponding phone-level sequences as output, have attracted much research attention in developing mispronunciation detection (MD) systems. However, due to the lack of sufficient labeled speech data of L2 speakers for model estimation, E2E MD models are prone to overfitting in relation to conventional ones that are built on DNN-HMM acoustic models. To alleviate this critical issue, we in this paper propose two modeling strategies to enhance the discrimination capability of E2E MD models, each of which can implicitly leverage the phonetic and phonological traits encoded in a pretrained acoustic model and contained within reference transcripts of the training data, respectively. The first one is input augmentation, which aims to distill knowledge about phonetic discrimination from a DNN-HMM acoustic model. The second one is label augmentation, which manages to capture more phonological patterns from the transcripts of training data. A series of empirical experiments conducted on the L2-ARCTIC English dataset seem to confirm the efficacy of our E2E MD model when compared to some top-of-the-line E2E MD models and a classic pronunciation-scoring based method built on a DNN-HMM acoustic model.