 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum F1-score training for end-to-end mispronunciation detection and diagnosis of L2 English speech
Aug 31, 2021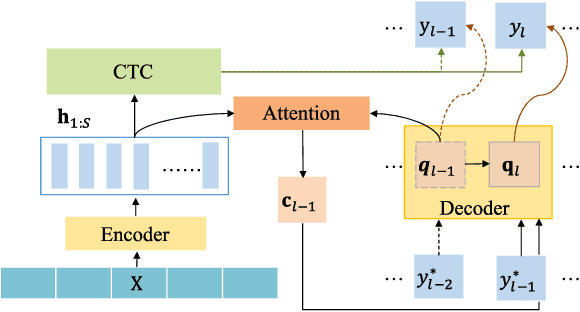


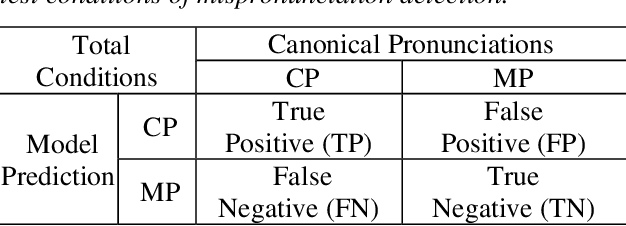
End-to-end (E2E) neural models are increasingly attracting attention as a promising modeling approach for mispronunciation detection and diagnosis (MDD). Typically, these models are trained by optimizing a cross-entropy criterion, which corresponds to improving the log-likelihood of the training data. However, there is a discrepancy between the objectives of model training and the MDD evaluation, since the performance of an MDD model is commonly evaluated in terms of F1-score instead of word error rate (WER). In view of this, we in this paper explore the use of a discriminative objective function for training E2E MDD models, which aims to maximize the expected F1-score directly. To further facilitate maximum F1-score training, we randomly perturb fractions of the labels of phonetic confusing pairs in the training utterances of L2 (second language) learners to generate artificial pronunciation error patterns for data augmentation. A series of experiments conducted on the L2-ARCTIC dataset show that our proposed method can yield considerable performance improvements in relation to some state-of-the-art E2E MDD approaches and the conventional GOP method.
Towards Robust Mispronunciation Detection and Diagnosis for L2 English Learners with Accent-Modulating Methods
Aug 26, 2021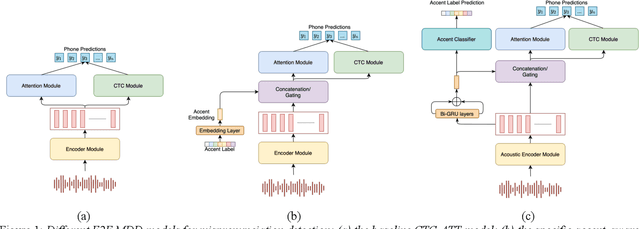
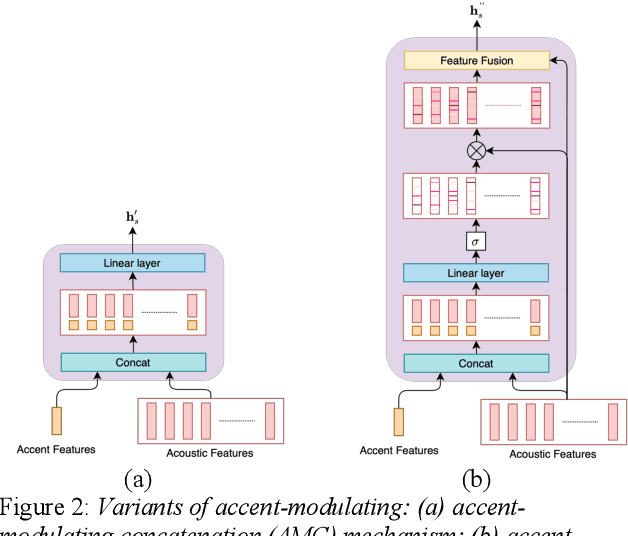
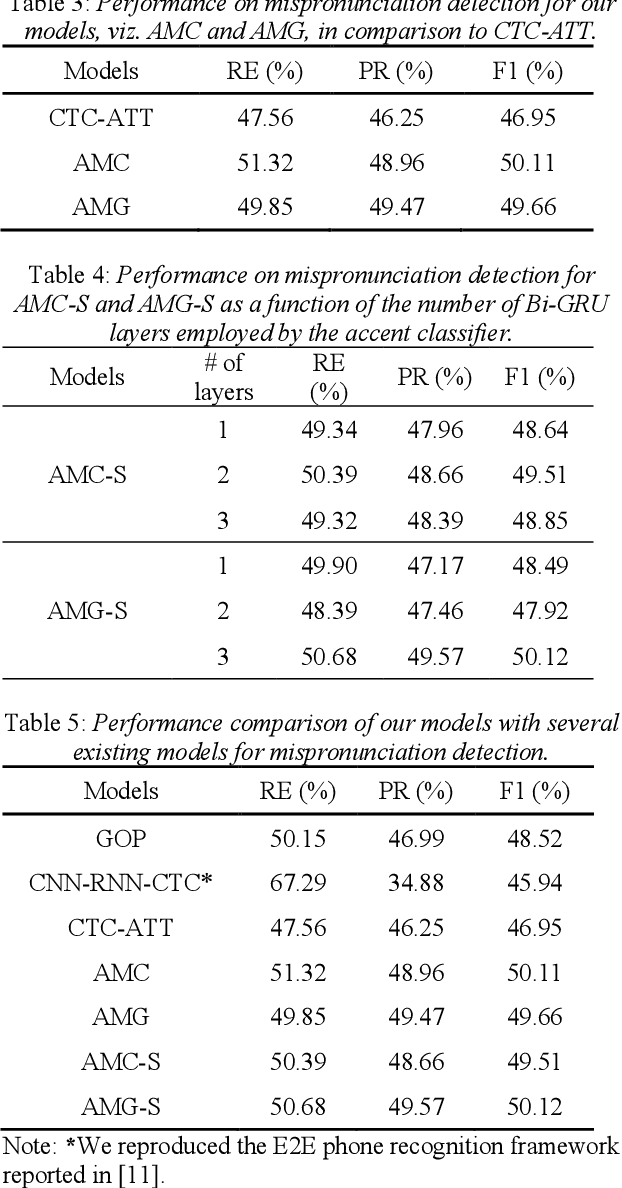
With the acceleration of globalization, more and more people are willing or required to learn second languages (L2). One of the major remaining challenges facing current mispronunciation and diagnosis (MDD) models for use in computer-assisted pronunciation training (CAPT) is to handle speech from L2 learners with a diverse set of accents. In this paper, we set out to mitigate the adverse effects of accent variety in building an L2 English MDD system with end-to-end (E2E) neural models. To this end, we first propose an effective modeling framework that infuses accent features into an E2E MDD model, thereby making the model more accent-aware. Going a step further, we design and present disparate accent-aware modules to perform accent-aware modulation of acoustic features in a fine-grained manner, so as to enhance the discriminating capability of the resulting MDD model. Extensive sets of experiments conducted on the L2-ARCTIC benchmark dataset show the merits of our MDD model, in comparison to some existing E2E-based strong baselines and the celebrated pronunciation scoring based method.
TENET: A Time-reversal Enhancement Network for Noise-robust ASR
Jul 08, 2021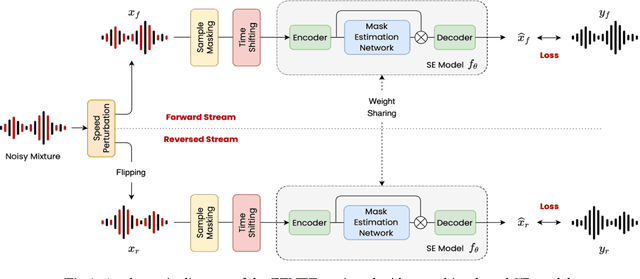
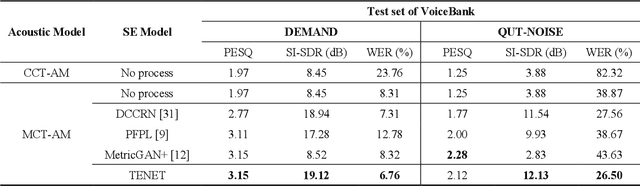
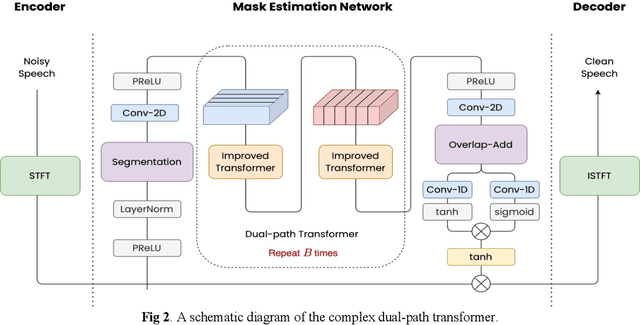
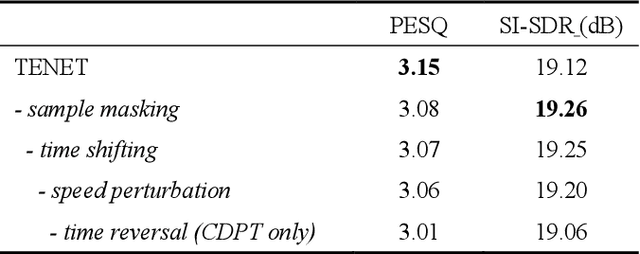
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.