 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENET: A Time-reversal Enhancement Network for Noise-robust ASR
Paper and Code
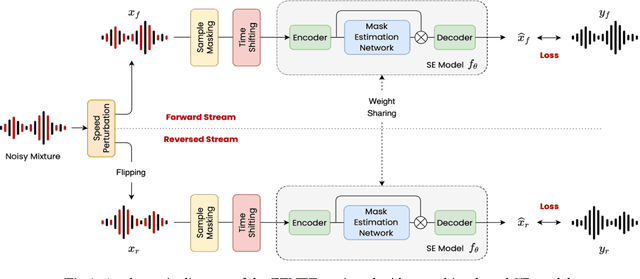
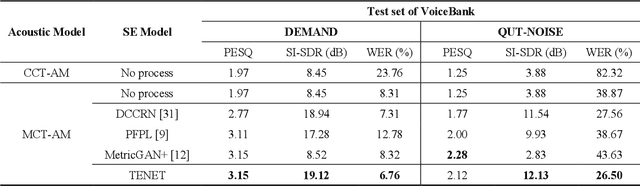
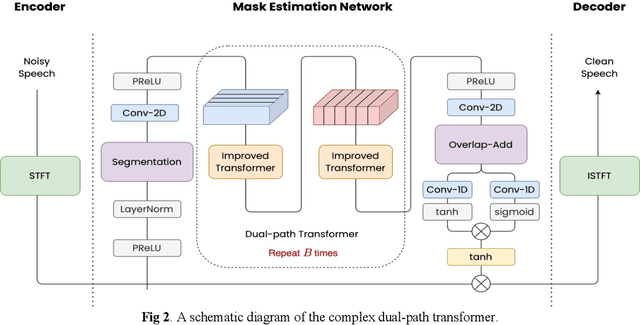
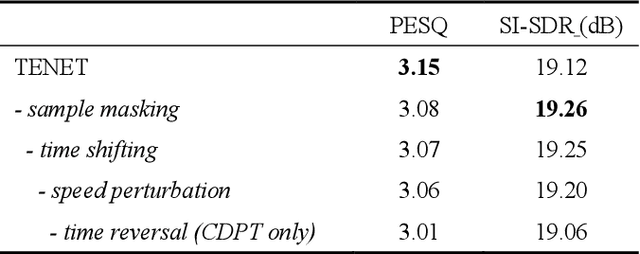
Due to the unprecedented breakthroughs brought about by deep learning, speech enhancement (SE) techniques have been developed rapidly and play an important role prior to acoustic modeling to mitigate noise effects on speech. To increase the perceptual quality of speech, current state-of-the-art in the SE field adopts adversarial training by connecting an objective metric to the discriminator. However, there is no guarantee that optimizing the perceptual quality of speech will necessarily lead to improved automatic speech recognition (ASR) performance. In this study, we present TENET, a novel Time-reversal Enhancement NETwork, which leverages the transformation of an input noisy signal itself, i.e., the time-reversed version, in conjunction with the siamese network and complex dual-path transformer to promote SE performance for noise-robust ASR. Extensive experiments conducted on the Voicebank-DEMAND dataset show that TENET can achieve state-of-the-art results compared to a few top-of-the-line methods in terms of both SE and ASR evaluation metrics. To demonstrate the model generalization ability, we further evaluate TENET on the test set of scenarios contaminated with unseen noise, and the results also confirm the superiority of this promising method.