 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Microphone Speech Enhancement based on Deep Learning
Paper and Code
Nov 22, 2019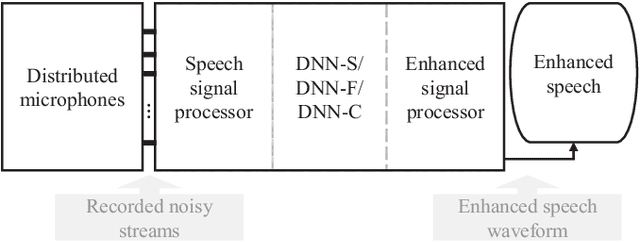

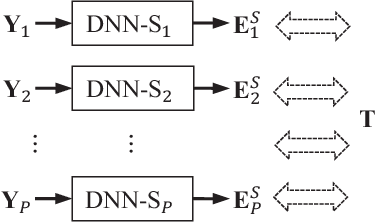
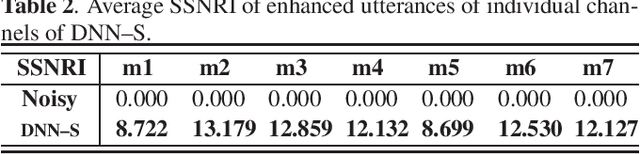
Speech-related applications deliver inferior performance in complex noise environments. Therefore, this study primarily addresses this problem by introducing speech-enhancement (SE) systems based on deep neural networks (DNNs) applied to a distributed microphone architecture. The first system constructs a DNN model for each microphone to enhance the recorded noisy speech signal, and the second system combines all the noisy recordings into a large feature structure that is then enhanced through a DNN model. As for the third system, a channel-dependent DNN is first used to enhance the corresponding noisy input, and all the channel-wise enhanced outputs are fed into a DNN fusion model to construct a nearly clean signal. All the three DNN SE systems are operated in the acoustic frequency domain of speech signals in a diffuse-noise field environment. Evaluation experiments were conducted on the Taiwan Mandarin Hearing in Noise Test (TMHINT) database, and the results indicate that all the three DNN-based SE systems provide the original noise-corrupted signals with improved speech quality and intelligibility, whereas the third system delivers the highest signal-to-noise ratio (SNR) improvement and optimal speech intelligibility.