 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Face-Mask Speech Enhancement Using Generative Adversarial Networks with Human-in-the-Loop Assessment Metrics
Jul 02, 2024The utilization of face masks is an essential healthcare measure, particularly during times of pandemics, yet it can present challenges in communication in our daily lives. To address this problem, we propose a novel approach known as the human-in-the-loop StarGAN (HL-StarGAN) face-masked speech enhancement method. HL-StarGAN comprises discriminator, classifier, metric assessment predictor, and generator that leverages an attention mechanism. The metric assessment predictor, referred to as MaskQSS, incorporates human participants in its development and serves as a "human-in-the-loop" module during the learning process of HL-StarGAN. The overall HL-StarGAN model was trained using an unsupervised learning strategy that simultaneously focuses on the reconstruction of the original clean speech and the optimization of human perception. To implement HL-StarGAN, we curated a face-masked speech database named "FMVD," which comprises recordings from 34 speakers in three distinct face-masked scenarios and a clean condition. We conducted subjective and objective tests on the proposed HL-StarGAN using this database. The outcomes of the test results are as follows: (1) MaskQSS successfully predicted the quality scores of face mask voices, outperforming several existing speech assessment methods. (2) The integration of the MaskQSS predictor enhanced the ability of HL-StarGAN to transform face mask voices into high-quality speech; this enhancement is evident in both objective and subjective tests, outperforming conventional StarGAN and CycleGAN-based systems.
* face-mask speech enhancement, generative adversarial networks, StarGAN, human-in-the-loop, unsupervised learning
Continuous Speech for Improved Learning Pathological Voice Disorders
Feb 22, 2022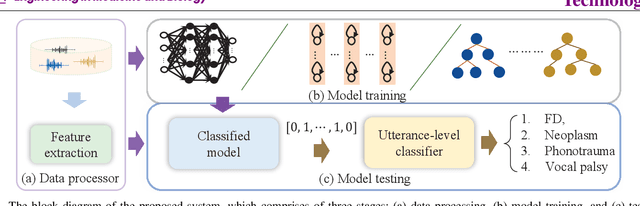
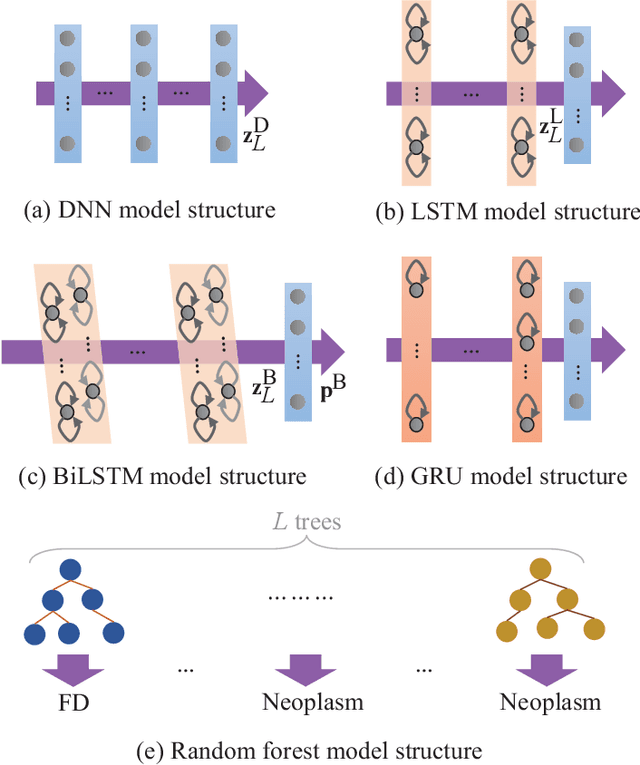
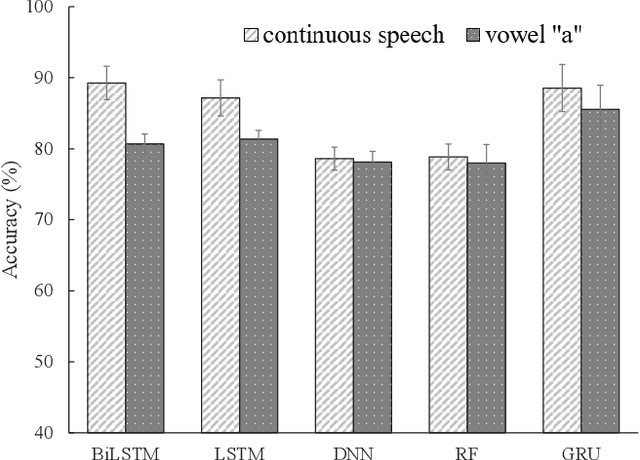
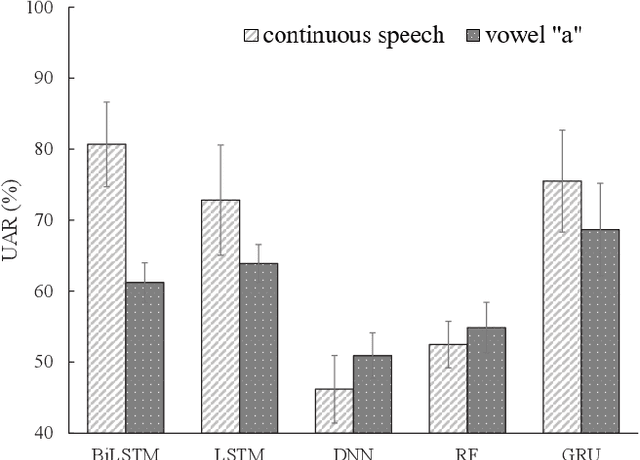
Goal: Numerous studies had successfully differentiated normal and abnormal voice samples. Nevertheless, further classification had rarely been attempted. This study proposes a novel approach, using continuous Mandarin speech instead of a single vowel, to classify four common voice disorders (i.e. functional dysphonia, neoplasm, phonotrauma, and vocal palsy). Methods: In the proposed framework, acoustic signals are transformed into mel-frequency cepstral coefficients, and a bi-directional long-short term memory network (BiLSTM) is adopted to model the sequential features. The experiments were conducted on a large-scale database, wherein 1,045 continuous speech were collected by the speech clinic of a hospital from 2012 to 2019. Results: Experimental results demonstrated that the proposed framework yields significant accuracy and unweighted average recall improvements of 78.12-89.27% and 50.92-80.68%, respectively, compared with systems that use a single vowel. Conclusions: The results are consistent with other machine learning algorithms, including gated recurrent units, random forest, deep neural networks, and LSTM. The sensitivities for each disorder were also analyzed, and the model capabilities were visualized via principal component analysis. An alternative experiment based on a balanced dataset again confirms the advantages of using continuous speech for learning voice disorders.
Toward Real-World Pathological Voice Detection
Dec 05, 2021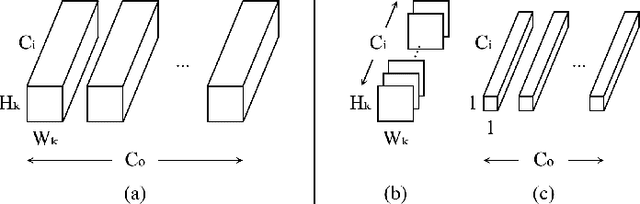
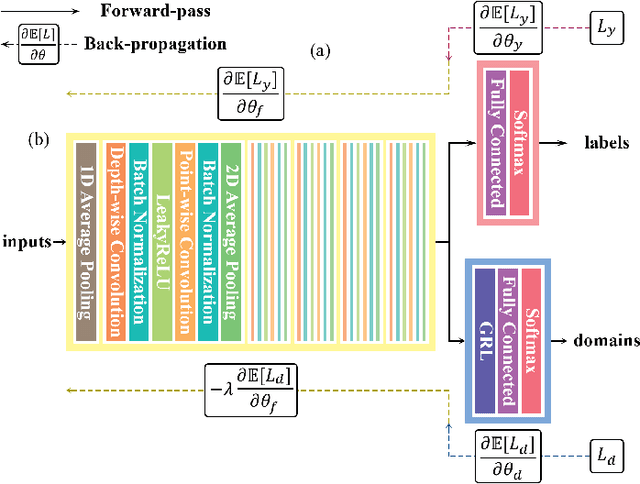
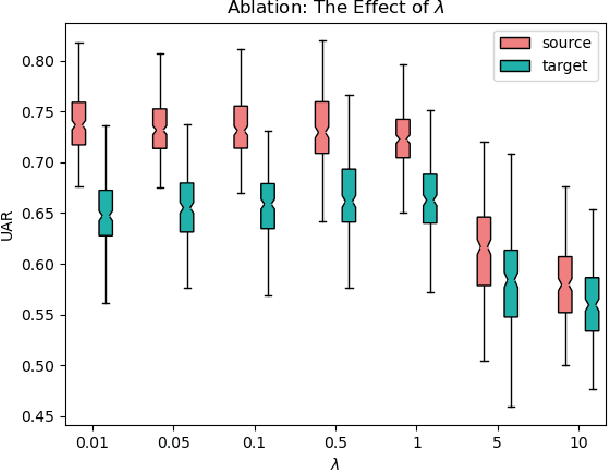
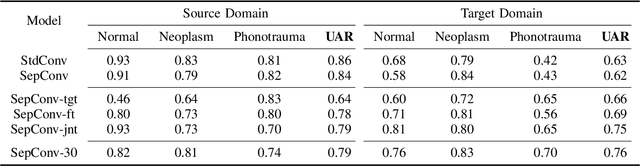
Voice disorders significantly undermine people's ability to speak in their daily lives. Without early diagnoses and treatments, these disorders may drastically deteriorate. Thus, automatic detection systems at home are desired for people inaccessible to disease assessments. However, more accurate systems usually require more cumbersome machine learning models, whereas the memory and computational resources of the systems at home are limited. Moreover, the performance of the systems may be weakened due to domain mismatch between clinic and real-world data. Therefore, we aimed to develop a compressed and domain-robust pathological voice detection system. Domain adversarial training was utilized to address domain mismatch by extracting domain-invariant features. In addition, factorized convolutional neural networks were exploited to compress the feature extractor model. The results showed that only 4% of degradation of unweighted average recall occurred in the target domain compared to the source domain, indicating that the domain mismatch was effectively eliminated. Furthermore, our system reduced both usages of memory and computation by over 73.9%. We concluded that this proposed system successfully resolved domain mismatch and may be applicable to embedded systems at home with limited resources.
Distributed Microphone Speech Enhancement based on Deep Learning
Nov 22, 2019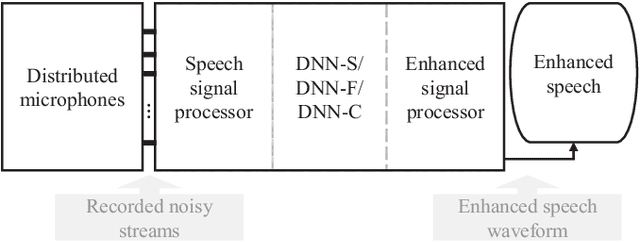

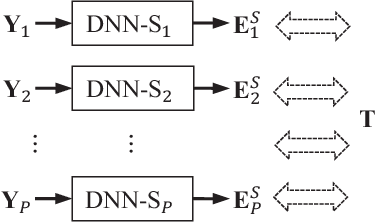
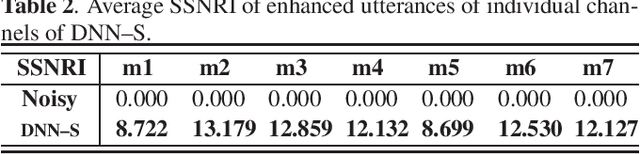
Speech-related applications deliver inferior performance in complex noise environments. Therefore, this study primarily addresses this problem by introducing speech-enhancement (SE) systems based on deep neural networks (DNNs) applied to a distributed microphone architecture. The first system constructs a DNN model for each microphone to enhance the recorded noisy speech signal, and the second system combines all the noisy recordings into a large feature structure that is then enhanced through a DNN model. As for the third system, a channel-dependent DNN is first used to enhance the corresponding noisy input, and all the channel-wise enhanced outputs are fed into a DNN fusion model to construct a nearly clean signal. All the three DNN SE systems are operated in the acoustic frequency domain of speech signals in a diffuse-noise field environment. Evaluation experiments were conducted on the Taiwan Mandarin Hearing in Noise Test (TMHINT) database, and the results indicate that all the three DNN-based SE systems provide the original noise-corrupted signals with improved speech quality and intelligibility, whereas the third system delivers the highest signal-to-noise ratio (SNR) improvement and optimal speech intelligibility.
Robustness against the channel effect in pathological voice detection
Dec 02, 2018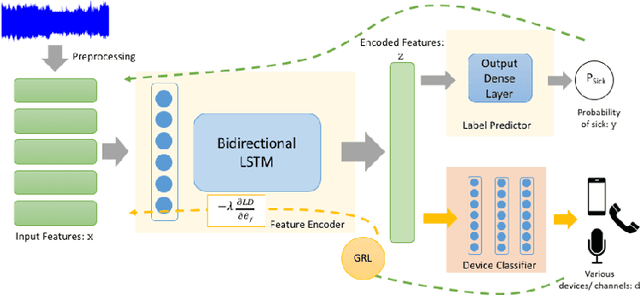
Many people are suffering from voice disorders, which can adversely affect the quality of their lives. In response, some researchers have proposed algorithms for automatic assessment of these disorders, based on voice signals. However, these signals can be sensitive to the recording devices. Indeed, the channel effect is a pervasive problem in machine learning for healthcare. In this study, we propose a detection system for pathological voice, which is robust against the channel effect. This system is based on a bidirectional LSTM network. To increase the performance robustness against channel mismatch, we integrate domain adversarial training (DAT) to eliminate the differences between the devices. When we train on data recorded on a high-quality microphone and evaluate on smartphone data without labels, our robust detection system increases the PR-AUC from 0.8448 to 0.9455 (and 0.9522 with target sample labels). To the best of our knowledge, this is the first study applying unsupervised domain adaptation to pathological voice detection. Notably, our system does not need target device sample labels, which allows for generalization to many new devices.