 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Real-World Pathological Voice Detection
Dec 05, 2021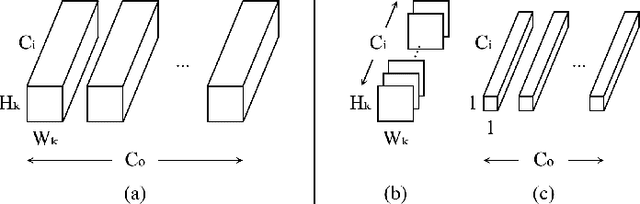
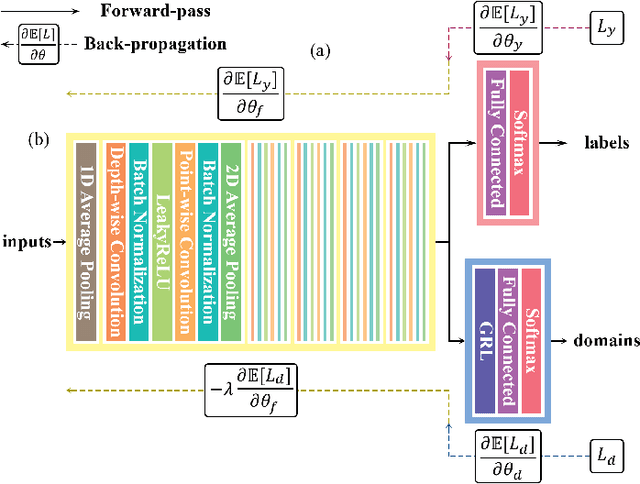
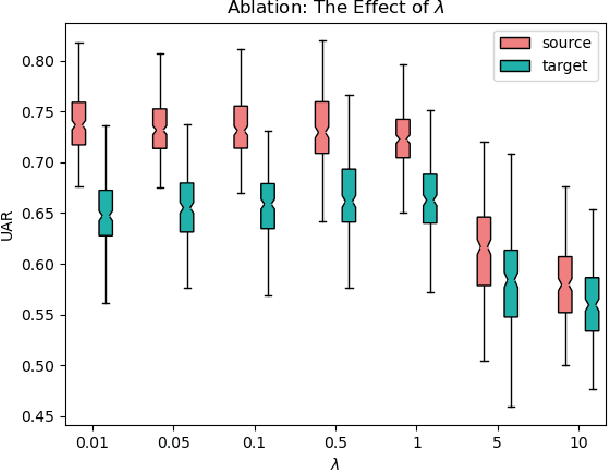
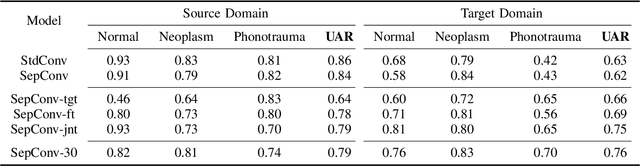
Voice disorders significantly undermine people's ability to speak in their daily lives. Without early diagnoses and treatments, these disorders may drastically deteriorate. Thus, automatic detection systems at home are desired for people inaccessible to disease assessments. However, more accurate systems usually require more cumbersome machine learning models, whereas the memory and computational resources of the systems at home are limited. Moreover, the performance of the systems may be weakened due to domain mismatch between clinic and real-world data. Therefore, we aimed to develop a compressed and domain-robust pathological voice detection system. Domain adversarial training was utilized to address domain mismatch by extracting domain-invariant features. In addition, factorized convolutional neural networks were exploited to compress the feature extractor model. The results showed that only 4% of degradation of unweighted average recall occurred in the target domain compared to the source domain, indicating that the domain mismatch was effectively eliminated. Furthermore, our system reduced both usages of memory and computation by over 73.9%. We concluded that this proposed system successfully resolved domain mismatch and may be applicable to embedded systems at home with limited resources.