 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSep: a Noise- and Reverberation-Robust Speech Separation Framework by Magnitude Conditioning
Mar 04, 2024Speech separation has recently made significant progress thanks to the fine-grained vision used in time-domain methods. However, several studies have shown that adopting Short-Time Fourier Transform (STFT) for feature extraction could be beneficial when encountering harsher conditions, such as noise or reverberation. Therefore, we propose a magnitude-conditioned time-domain framework, ConSep, to inherit the beneficial characteristics. The experiment shows that ConSep promotes performance in anechoic, noisy, and reverberant settings compared to two celebrated methods, SepFormer and Bi-Sep. Furthermore, we visualize the components of ConSep to strengthen the advantages and cohere with the actualities we have found in preliminary studies.
What do neural networks listen to? Exploring the crucial bands in Speech Enhancement using Sinc-convolution
Mar 04, 2024This study introduces a reformed Sinc-convolution (Sincconv) framework tailored for the encoder component of deep networks for speech enhancement (SE). The reformed Sincconv, based on parametrized sinc functions as band-pass filters, offers notable advantages in terms of training efficiency, filter diversity, and interpretability. The reformed Sinc-conv is evaluated in conjunction with various SE models, showcasing its ability to boost SE performance. Furthermore, the reformed Sincconv provides valuable insights into the specific frequency components that are prioritized in an SE scenario. This opens up a new direction of SE research and improving our knowledge of their operating dynamics.
Naaloss: Rethinking the objective of speech enhancement
Aug 24, 2023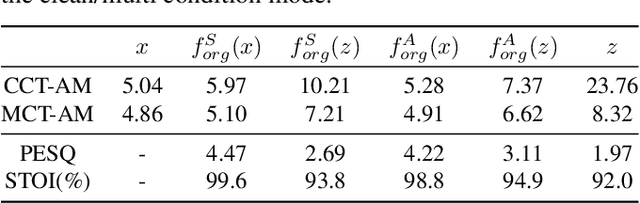
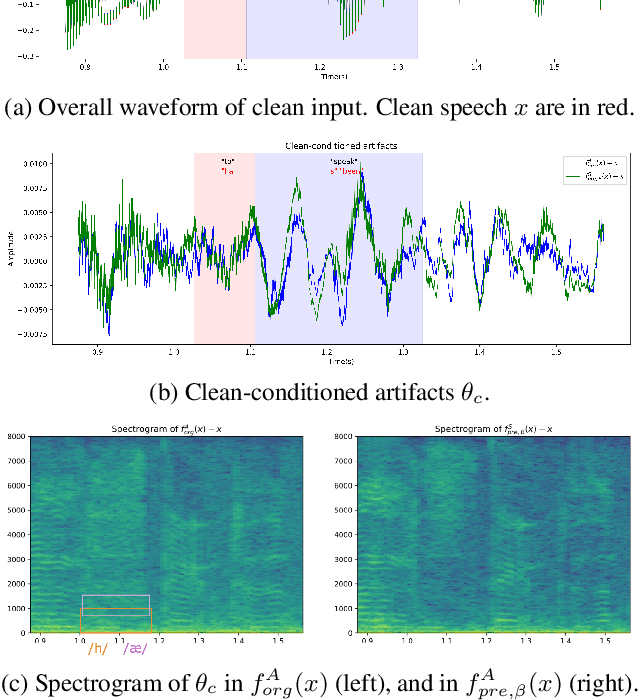
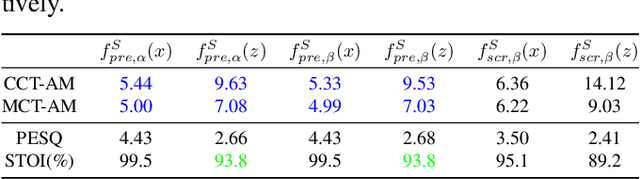
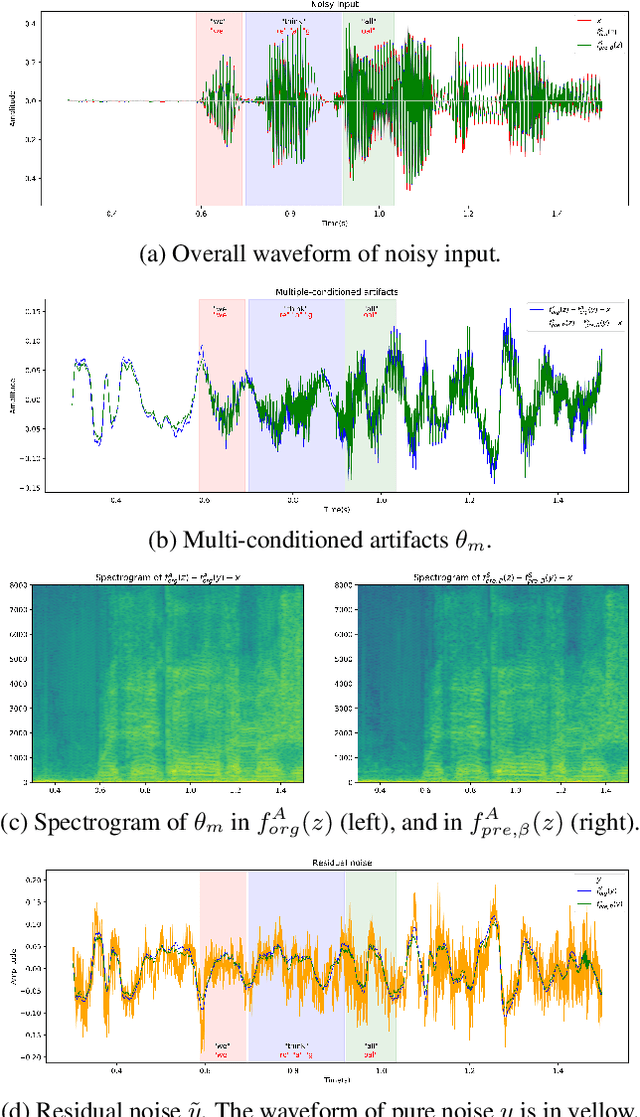
Reducing noise interference is crucial for automatic speech recognition (ASR) in a real-world scenario. However, most single-channel speech enhancement (SE) generates "processing artifacts" that negatively affect ASR performance. Hence, in this study, we suggest a Noise- and Artifacts-aware loss function, NAaLoss, to ameliorate the influence of artifacts from a novel perspective. NAaLoss considers the loss of estimation, de-artifact, and noise ignorance, enabling the learned SE to individually model speech, artifacts, and noise. We examine two SE models (simple/advanced) learned with NAaLoss under various input scenarios (clean/noisy) using two configurations of the ASR system (with/without noise robustness). Experiments reveal that NAaLoss significantly improves the ASR performance of most setups while preserving the quality of SE toward perception and intelligibility. Furthermore, we visualize artifacts through waveforms and spectrograms, and explain their impact on ASR.