 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaraSinger: Score-Free Singing Voice Synthesis with VQ-VAE using Mel-spectrograms
Oct 08, 2021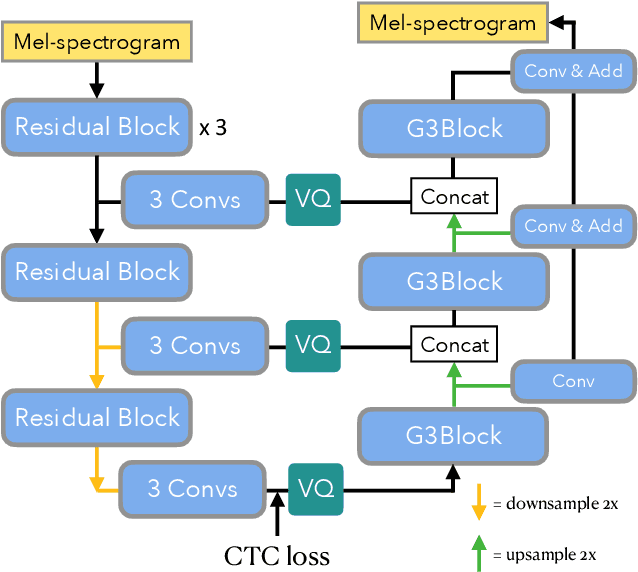
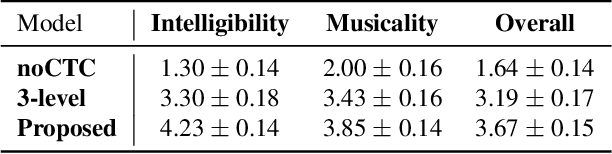
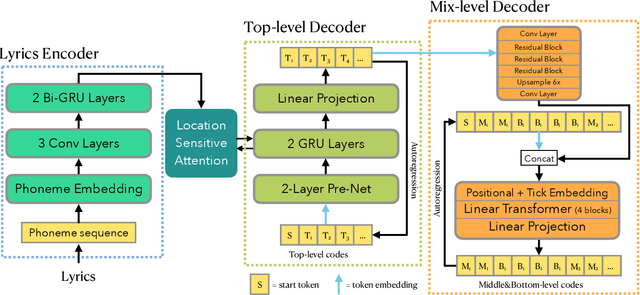

In this paper, we propose a novel neural network model called KaraSinger for a less-studied singing voice synthesis (SVS) task named score-free SVS, in which the prosody and melody are spontaneously decided by machine. KaraSinger comprises a vector-quantized variational autoencoder (VQ-VAE) that compresses the Mel-spectrograms of singing audio to sequences of discrete codes, and a language model (LM) that learns to predict the discrete codes given the corresponding lyrics. For the VQ-VAE part, we employ a Connectionist Temporal Classification (CTC) loss to encourage the discrete codes to carry phoneme-related information. For the LM part, we use location-sensitive attention for learning a robust alignment between the input phoneme sequence and the output discrete code. We keep the architecture of both the VQ-VAE and LM light-weight for fast training and inference speed. We validate the effectiveness of the proposed design choices using a proprietary collection of 550 English pop songs sung by multiple amateur singers. The result of a listening test shows that KaraSinger achieves high scores in intelligibility, musicality, and the overall quality.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021
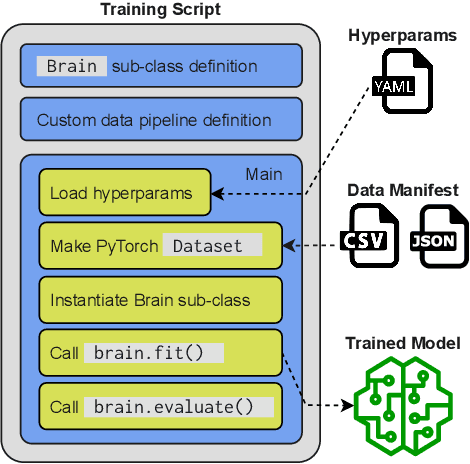

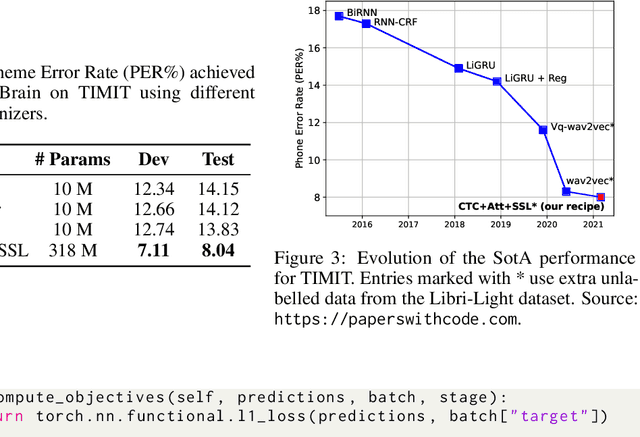
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021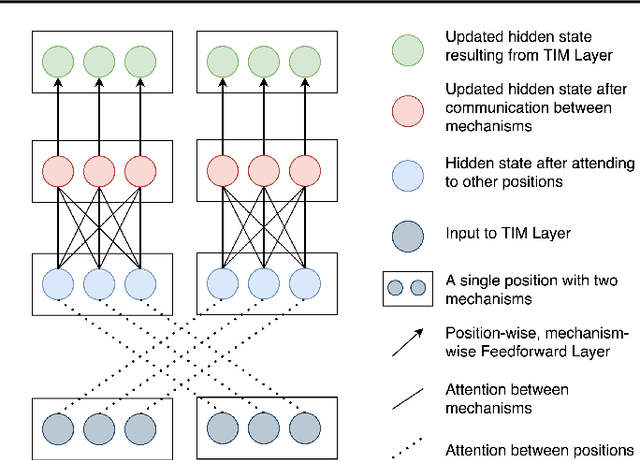
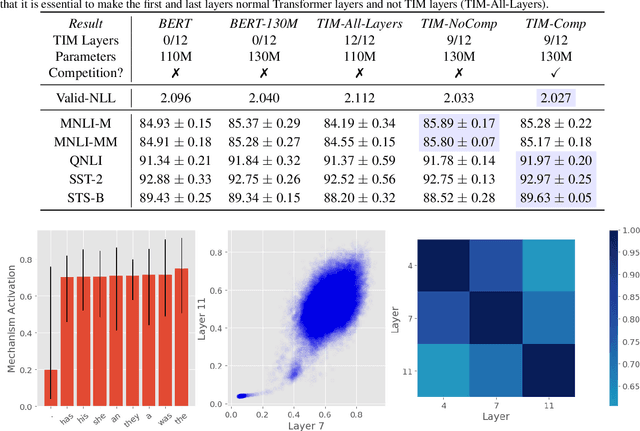
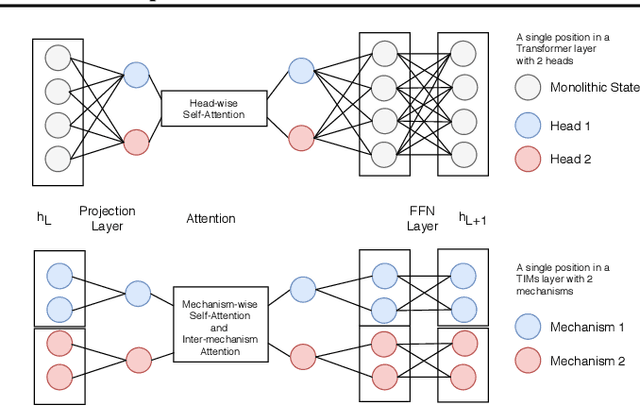
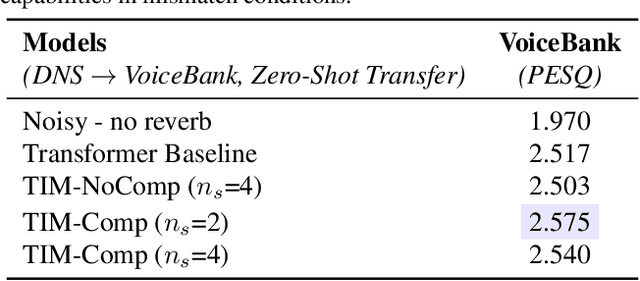
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
Incorporating Broad Phonetic Information for Speech Enhancement
Aug 13, 2020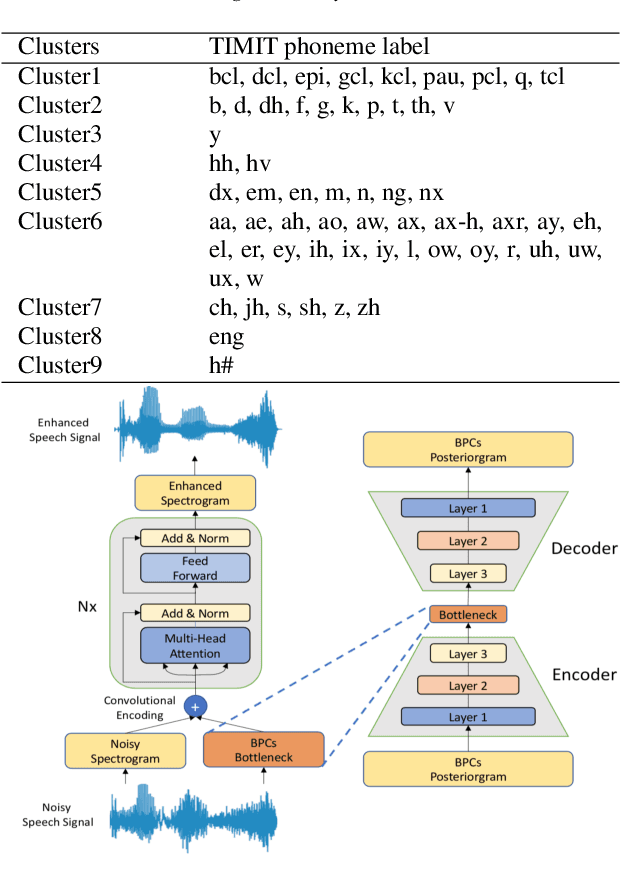
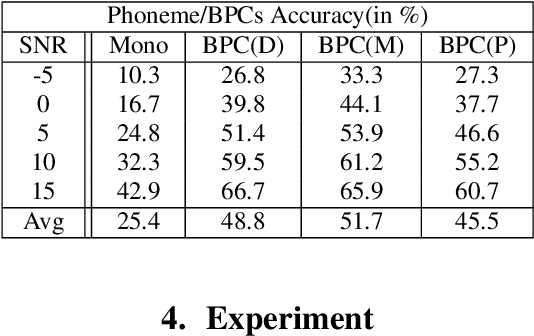
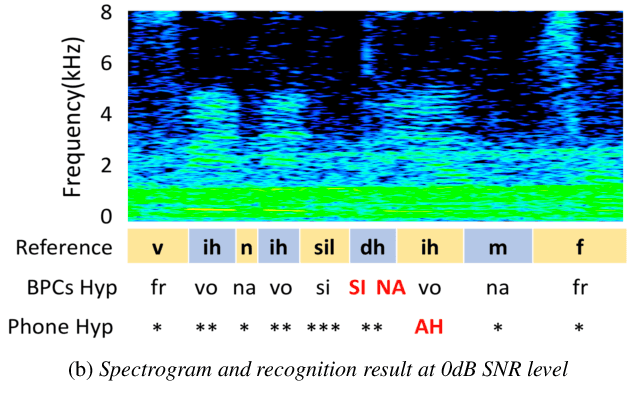

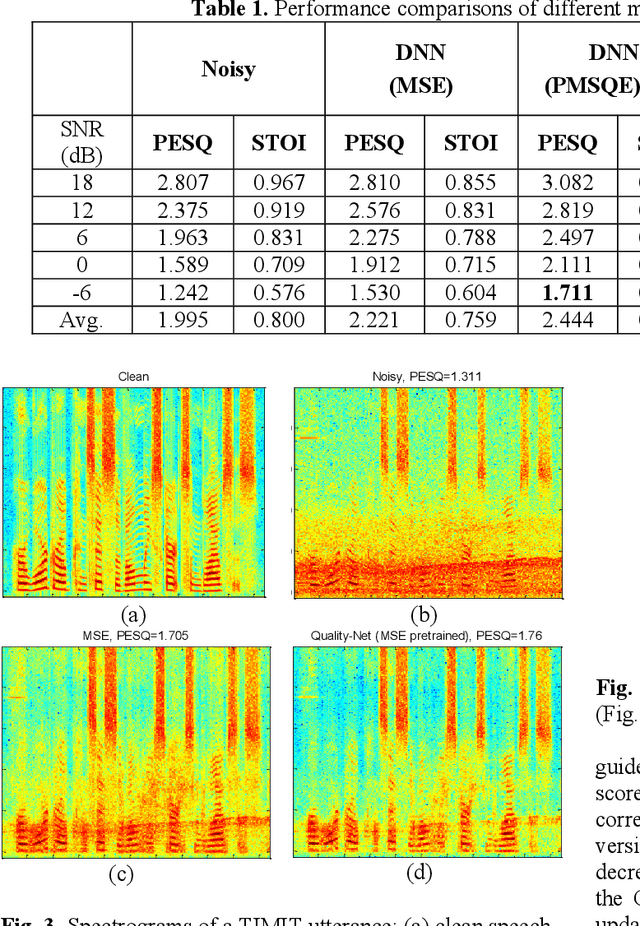
In noisy conditions, knowing speech contents facilitates listeners to more effectively suppress background noise components and to retrieve pure speech signals. Previous studies have also confirmed the benefits of incorporating phonetic information in a speech enhancement (SE) system to achieve better denoising performance. To obtain the phonetic information, we usually prepare a phoneme-based acoustic model, which is trained using speech waveforms and phoneme labels. Despite performing well in normal noisy conditions, when operating in very noisy conditions, however, the recognized phonemes may be erroneous and thus misguide the SE process. To overcome the limitation, this study proposes to incorporate the broad phonetic class (BPC) information into the SE process. We have investigated three criteria to build the BPC, including two knowledge-based criteria: place and manner of articulatory and one data-driven criterion. Moreover, the recognition accuracies of BPCs are much higher than that of phonemes, thus providing more accurate phonetic information to guide the SE process under very noisy conditions. Experimental results demonstrate that the proposed SE with the BPC information framework can achieve notable performance improvements over the baseline system and an SE system using monophonic information in terms of both speech quality intelligibility on the TIMIT dataset.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020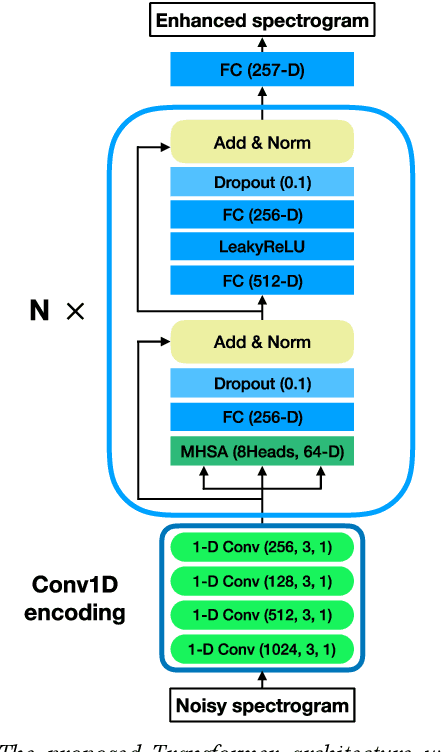
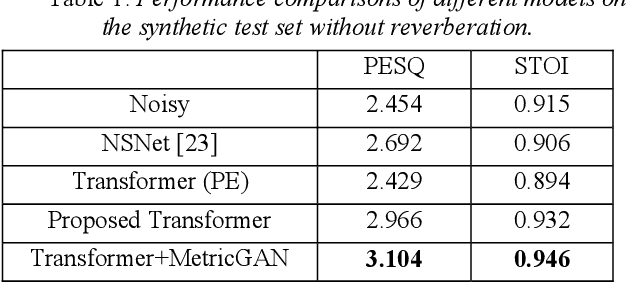

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.
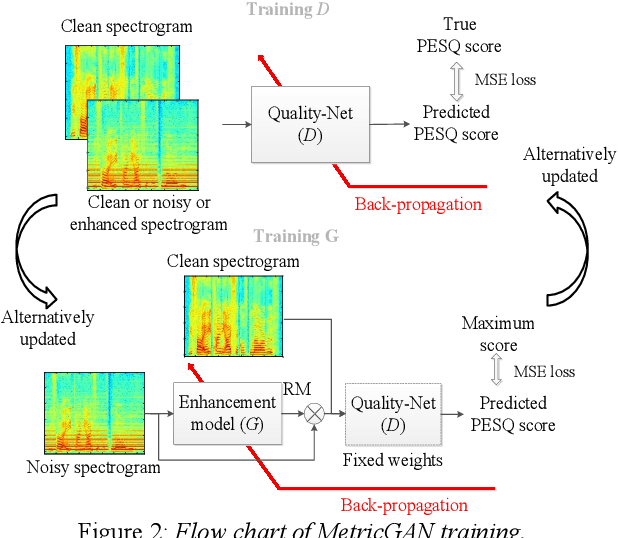
MetricGAN: Generative Adversarial Networks based Black-box Metric Scores Optimization for Speech Enhancement
May 13, 2019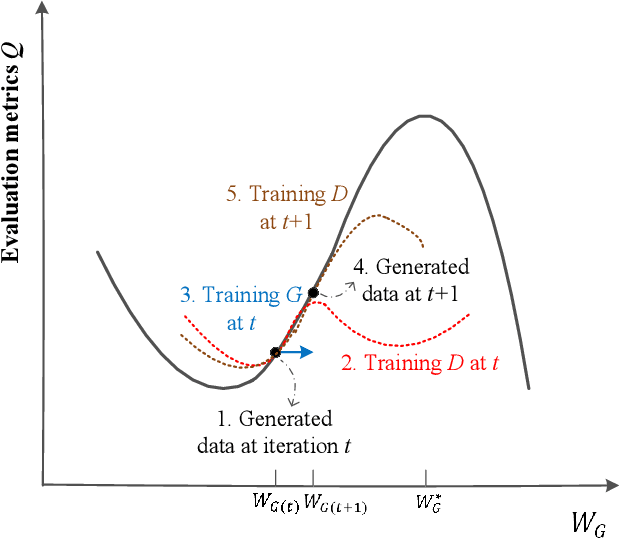
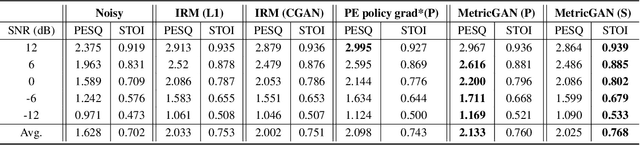
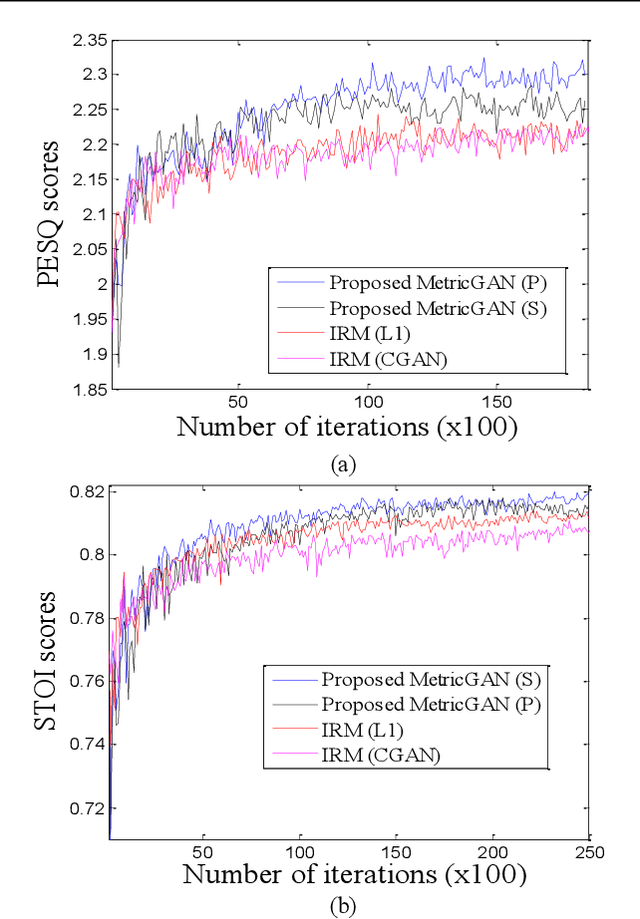
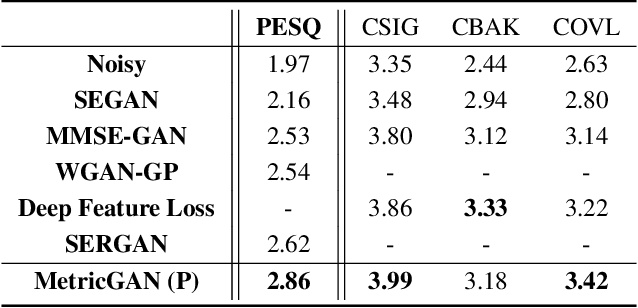
Adversarial loss in a conditional generative adversarial network (GAN) is not designed to directly optimize evaluation metrics of a target task, and thus, may not always guide the generator in a GAN to generate data with improved metric scores. To overcome this issue, we propose a novel MetricGAN approach with an aim to optimize the generator with respect to one or multiple evaluation metrics. Moreover, based on MetricGAN, the metric scores of the generated data can also be arbitrarily specified by users. We tested the proposed MetricGAN on a speech enhancement task, which is particularly suitable to verify the proposed approach because there are multiple metrics measuring different aspects of speech signals. Moreover, these metrics are generally complex and could not be fully optimized by Lp or conventional adversarial losses.
Learning with Learned Loss Function: Speech Enhancement with Quality-Net to Improve Perceptual Evaluation of Speech Quality
May 06, 2019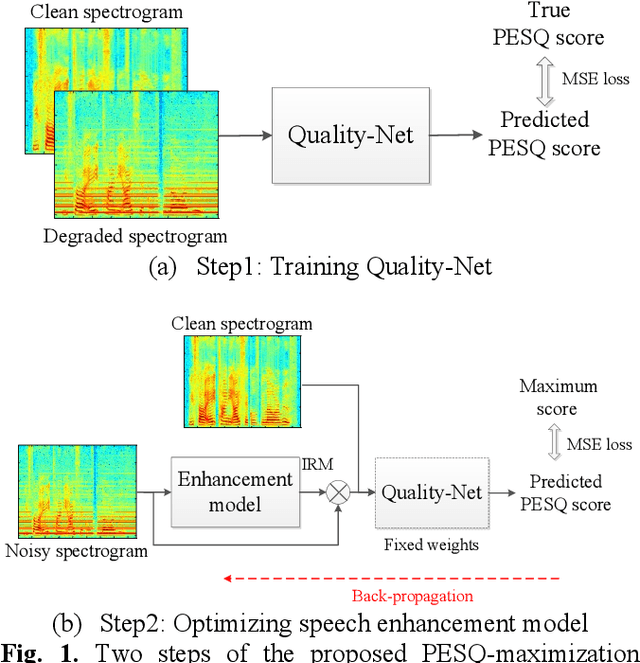
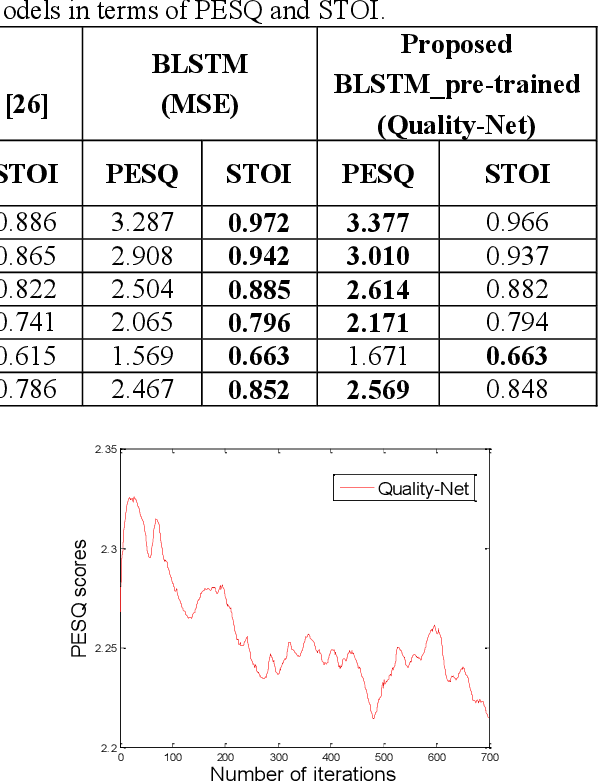

Utilizing a human-perception-related objective function to train a speech enhancement model has become a popular topic recently. This is primarily because the conventional mean squared error (MSE) loss cannot reflect auditory perception well. Among the human-perception-related metrics, the perceptual evaluation of speech quality (PESQ) is a typical one, and has been proven to provide a high correlation to the quality scores rated by humans. Owing to its complex and non-differentiable properties, however, the PESQ function may not be used to optimize speech enhancement models directly. In this study, we propose optimizing the enhancement model with an approximated PESQ function, which is differentiable and learned from the training data. The experimental results indicate that the average PESQ score of the enhanced speech fine-tuning by the learned loss function can further improve 0.1 points, as compared to that with the MSE-based pre-trained model.
Incorporating Symbolic Sequential Modeling for Speech Enhancement
Apr 30, 2019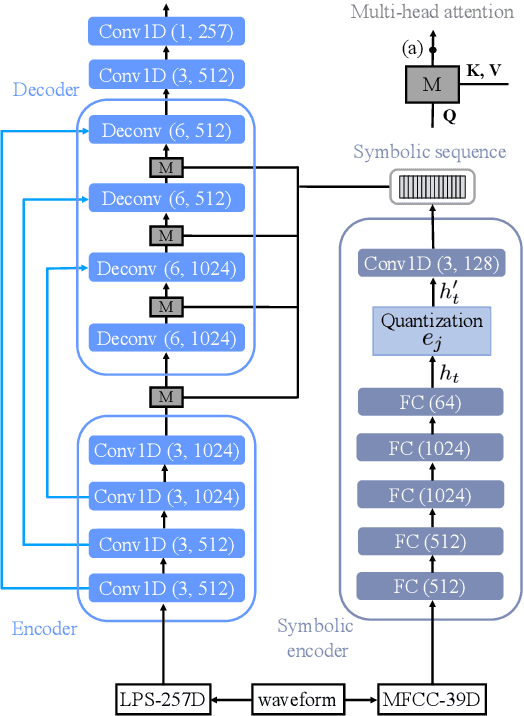
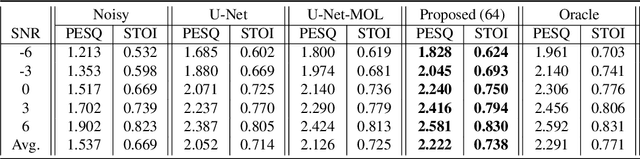
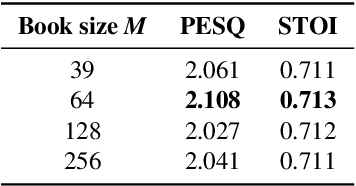
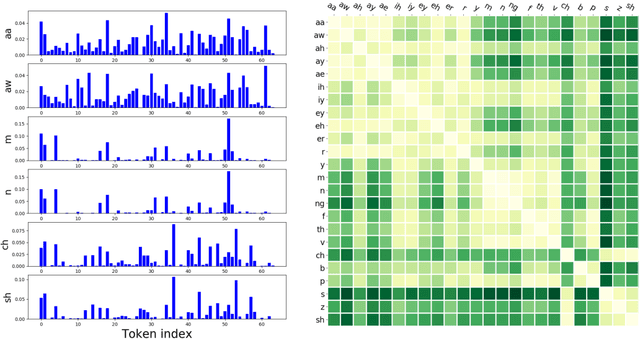
In a noisy environment, a lossy speech signal can be automatically restored by a listener if he/she knows the language well. That is, with the built-in knowledge of a "language model", a listener may effectively suppress noise interference and retrieve the target speech signals. Accordingly, we argue that familiarity with the underlying linguistic content of spoken utterances benefits speech enhancement (SE) in noisy environments. In this study, in addition to the conventional modeling for learning the acoustic noisy-clean speech mapping, an abstract symbolic sequential modeling is incorporated into the SE framework. This symbolic sequential modeling can be regarded as a "linguistic constraint" in learning the acoustic noisy-clean speech mapping function. In this study, the symbolic sequences for acoustic signals are obtained as discrete representations with a Vector Quantized Variational Autoencoder algorithm. The obtained symbols are able to capture high-level phoneme-like content from speech signals. The experimental results demonstrate that the proposed framework can significantly improve the SE performance in terms of perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI) on the TIMIT dataset.