 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Learned Loss Function: Speech Enhancement with Quality-Net to Improve Perceptual Evaluation of Speech Quality
Paper and Code
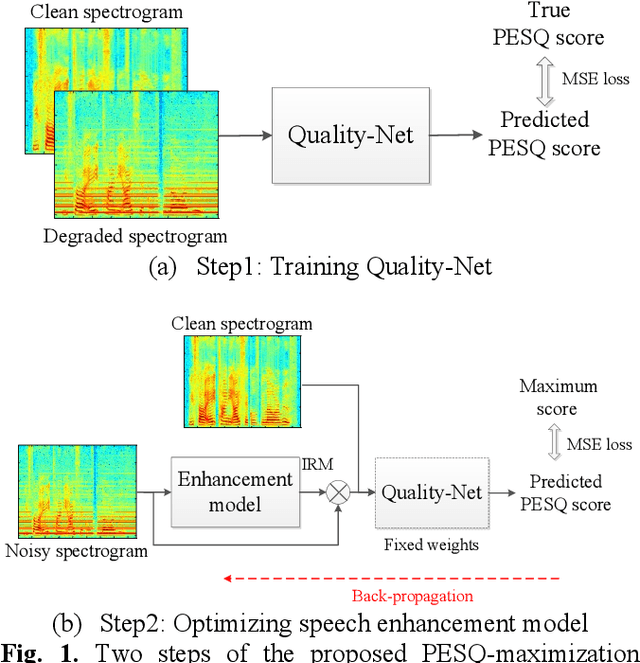
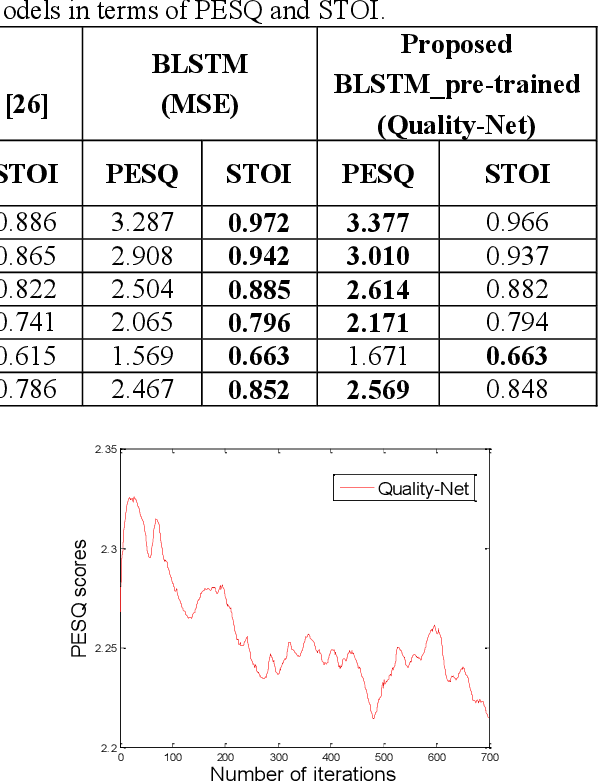

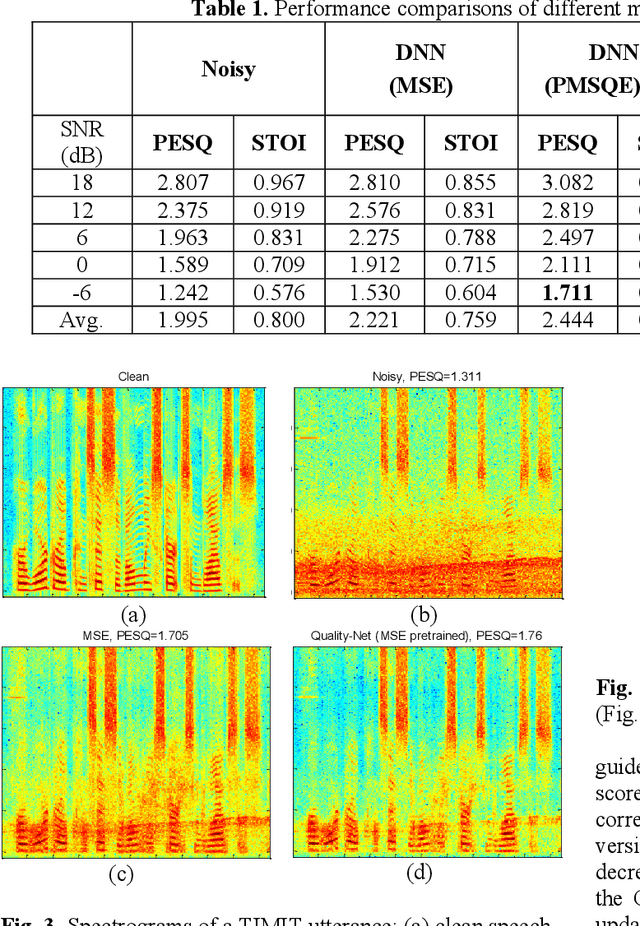
Utilizing a human-perception-related objective function to train a speech enhancement model has become a popular topic recently. This is primarily because the conventional mean squared error (MSE) loss cannot reflect auditory perception well. Among the human-perception-related metrics, the perceptual evaluation of speech quality (PESQ) is a typical one, and has been proven to provide a high correlation to the quality scores rated by humans. Owing to its complex and non-differentiable properties, however, the PESQ function may not be used to optimize speech enhancement models directly. In this study, we propose optimizing the enhancement model with an approximated PESQ function, which is differentiable and learned from the training data. The experimental results indicate that the average PESQ score of the enhanced speech fine-tuning by the learned loss function can further improve 0.1 points, as compared to that with the MSE-based pre-trained model.