 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA2S: An End-to-End Multimodal Articulatory-to-Speech System
Feb 07, 2021
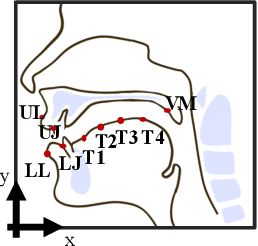

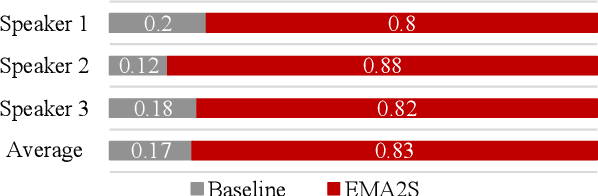
Synthesized speech from articulatory movements can have real-world use for patients with vocal cord disorders, situations requiring silent speech, or in high-noise environments. In this work, we present EMA2S, an end-to-end multimodal articulatory-to-speech system that directly converts articulatory movements to speech signals. We use a neural-network-based vocoder combined with multimodal joint-training, incorporating spectrogram, mel-spectrogram, and deep features. The experimental results confirm that the multimodal approach of EMA2S outperforms the baseline system in terms of both objective evaluation and subjective evaluation metrics. Moreover, results demonstrate that joint mel-spectrogram and deep feature loss training can effectively improve system performance.
Improved Lite Audio-Visual Speech Enhancement
Aug 30, 2020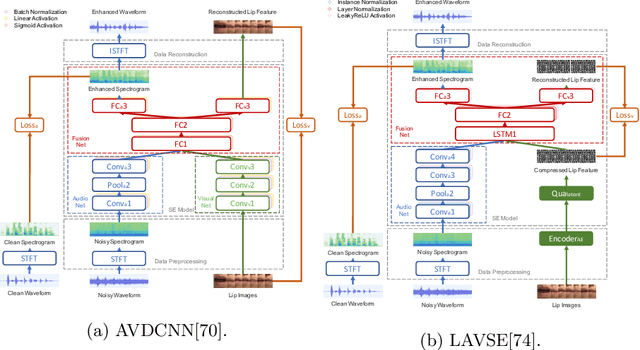
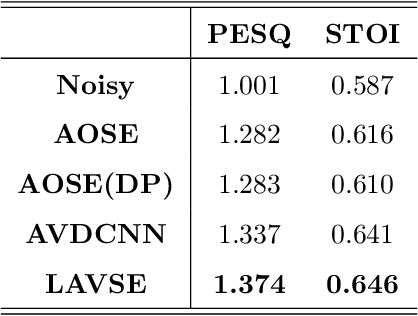

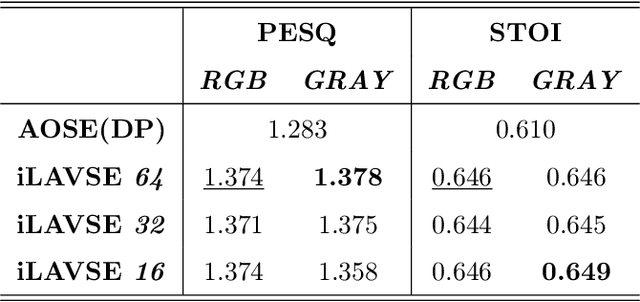
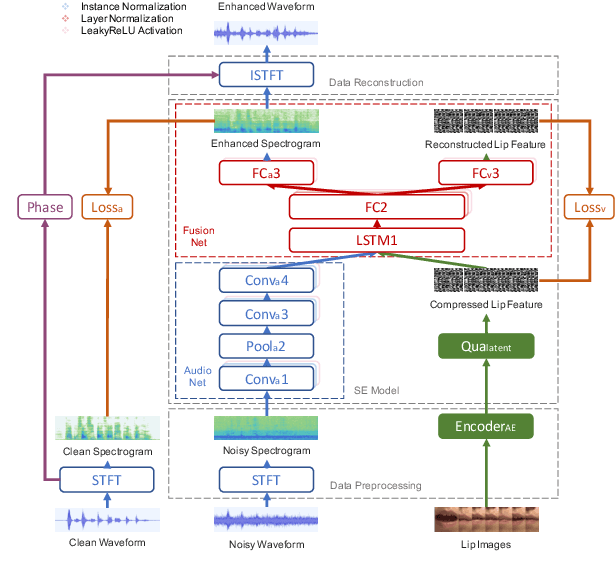
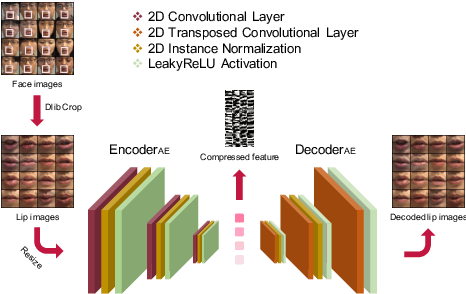
Numerous studies have investigated the effectiveness of audio-visual multimodal learning for speech enhancement (AVSE) tasks, seeking a solution that uses visual data as auxiliary and complementary input to reduce the noise of noisy speech signals. Recently, we proposed a lite audio-visual speech enhancement (LAVSE) algorithm. Compared to conventional AVSE systems, LAVSE requires less online computation and moderately solves the user privacy problem on facial data. In this study, we extend LAVSE to improve its ability to address three practical issues often encountered in implementing AVSE systems, namely, the requirement for additional visual data, audio-visual asynchronization, and low-quality visual data. The proposed system is termed improved LAVSE (iLAVSE), which uses a convolutional recurrent neural network architecture as the core AVSE model. We evaluate iLAVSE on the Taiwan Mandarin speech with video dataset. Experimental results confirm that compared to conventional AVSE systems, iLAVSE can effectively overcome the aforementioned three practical issues and can improve enhancement performance. The results also confirm that iLAVSE is suitable for real-world scenarios, where high-quality audio-visual sensors may not always be available.
Boosting Objective Scores of Speech Enhancement Model through MetricGAN Post-Processing
Jun 18, 2020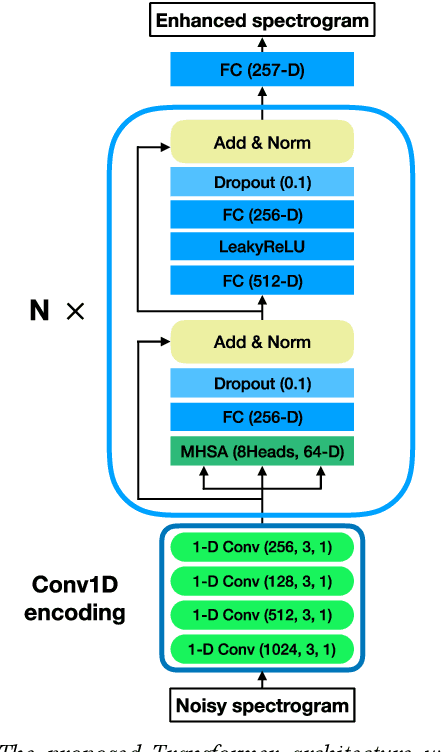
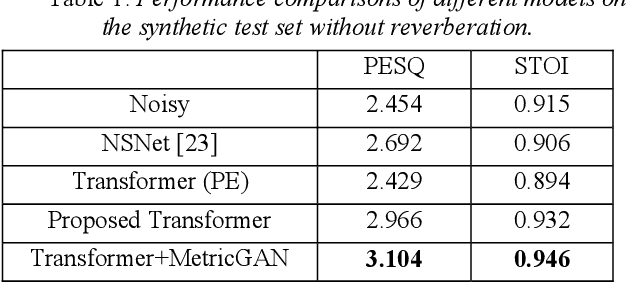
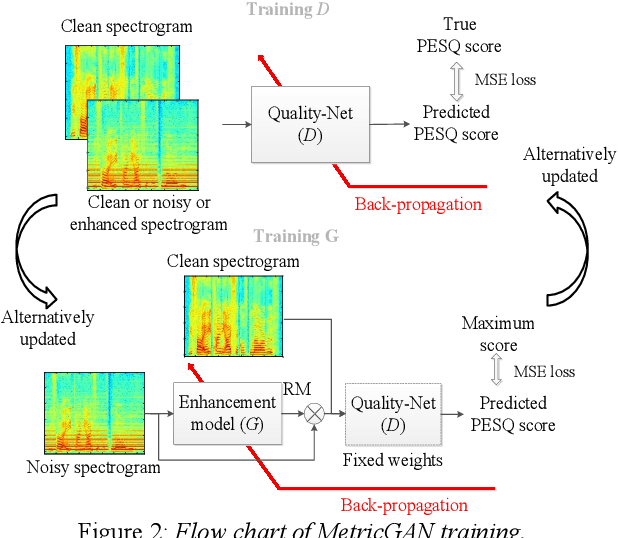

The Transformer architecture has shown its superior ability than recurrent neural networks on many different natural language processing applications. Therefore, this study applies a modified Transformer on the speech enhancement task. Specifically, the positional encoding may not be necessary and hence is replaced by convolutional layers. To further improve PESQ scores of enhanced speech, the L_1 pre-trained Transformer is fine-tuned by MetricGAN framework. The proposed MetricGAN can be treated as a general post-processing module to further boost interested objective scores. The experiments are conducted using the data sets provided by the organizer of the Deep Noise Suppression (DNS) challenge. Experimental results demonstrate that the proposed system outperforms the challenge baseline in both subjective and objective evaluation with a large margin.
Lite Audio-Visual Speech Enhancement
May 24, 2020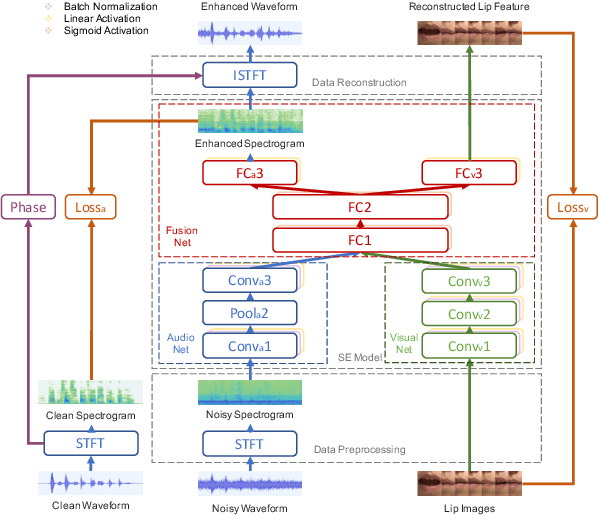
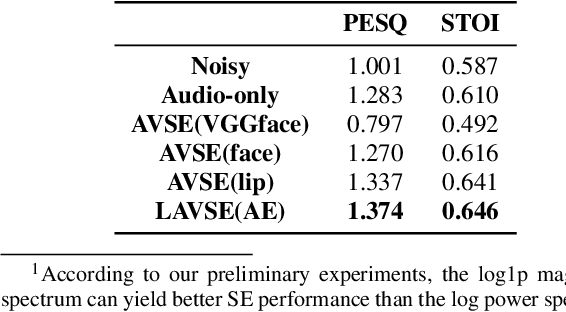
Previous studies have confirmed the effectiveness of incorporating visual information into speech enhancement (SE) systems. Despite improved denoising performance, two problems may be encountered when implementing an audio-visual SE (AVSE) system: (1) additional processing costs are incurred to incorporate visual input and (2) the use of face or lip images may cause privacy problems. In this study, we propose a Lite AVSE (LAVSE) system to address these problems. The system includes two visual data compression techniques and removes the visual feature extraction network from the training model, yielding better online computation efficiency. Our experimental results indicate that the proposed LAVSE system can provide notably better performance than an audio-only SE system with a similar number of model parameters. In addition, the experimental results confirm the effectiveness of the two techniques for visual data compression.