 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Guided Radar Depth Estimation for 3D Object Detection
Jan 27, 2026Accurate depth estimation is fundamental to 3D perception in autonomous driving, supporting tasks such as detection, tracking, and motion planning. However, monocular camera-based 3D detection suffers from depth ambiguity and reduced robustness under challenging conditions. Radar provides complementary advantages such as resilience to poor lighting and adverse weather, but its sparsity and low resolution limit its direct use in detection frameworks. This motivates the need for effective Radar-camera fusion with improved preprocessing and depth estimation strategies. We propose an end-to-end framework that enhances monocular 3D object detection through two key components. First, we introduce InstaRadar, an instance segmentation-guided expansion method that leverages pre-trained segmentation masks to enhance Radar density and semantic alignment, producing a more structured representation. InstaRadar achieves state-of-the-art results in Radar-guided depth estimation, showing its effectiveness in generating high-quality depth features. Second, we integrate the pre-trained RCDPT into the BEVDepth framework as a replacement for its depth module. With InstaRadar-enhanced inputs, the RCDPT integration consistently improves 3D detection performance. Overall, these components yield steady gains over the baseline BEVDepth model, demonstrating the effectiveness of InstaRadar and the advantage of explicit depth supervision in 3D object detection. Although the framework lags behind Radar-camera fusion models that directly extract BEV features, since Radar serves only as guidance rather than an independent feature stream, this limitation highlights potential for improvement. Future work will extend InstaRadar to point cloud-like representations and integrate a dedicated Radar branch with temporal cues for enhanced BEV fusion.
RCDPT: Radar-Camera fusion Dense Prediction Transformer
Nov 04, 2022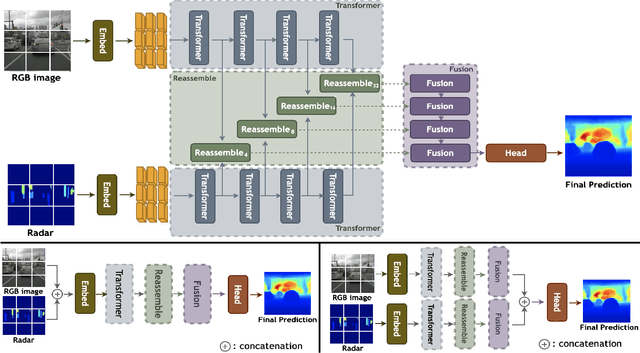
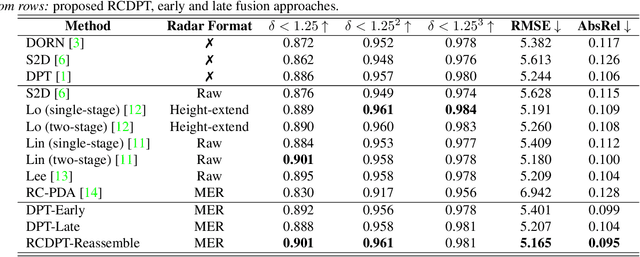

Recently, transformer networks have outperformed traditional deep neural networks in natural language processing and show a large potential in many computer vision tasks compared to convolutional backbones. In the original transformer, readout tokens are used as designated vectors for aggregating information from other tokens. However, the performance of using readout tokens in a vision transformer is limited. Therefore, we propose a novel fusion strategy to integrate radar data into a dense prediction transformer network by reassembling camera representations with radar representations. Instead of using readout tokens, radar representations contribute additional depth information to a monocular depth estimation model and improve performance. We further investigate different fusion approaches that are commonly used for integrating additional modality in a dense prediction transformer network. The experiments are conducted on the nuScenes dataset, which includes camera images, lidar, and radar data. The results show that our proposed method yields better performance than the commonly used fusion strategies and outperforms existing convolutional depth estimation models that fuse camera images and radar.
How much depth information can radar infer and contribute
Feb 26, 2022
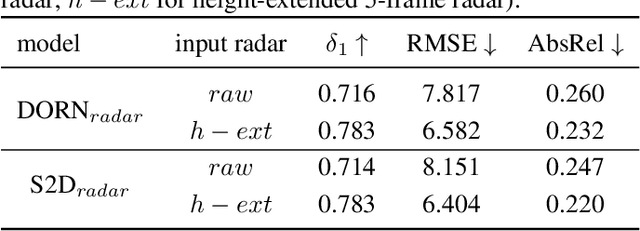

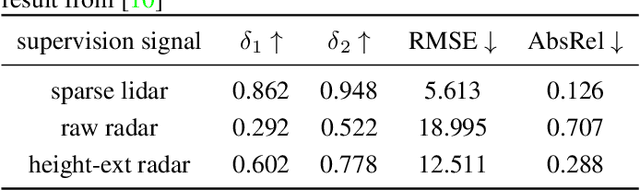
Since the release of radar data in large scale autonomous driving dataset, many works have been proposed fusing radar data as an additional guidance signal into monocular depth estimation models. Although positive performances are reported, it is still hard to tell how much depth information radar can infer and contribute in depth estimation models. In this paper, we conduct two experiments to investigate the intrinsic depth capability of radar data using state-of-the-art depth estimation models. Our experiments demonstrate that the estimated depth from only sparse radar input can detect the shape of surroundings to a certain extent. Furthermore, the monocular depth estimation model supervised by preprocessed radar only during training can achieve 70% performance in delta_1 score compared to the baseline model trained with sparse lidar.
Depth Estimation from Monocular Images and Sparse radar using Deep Ordinal Regression Network
Jul 15, 2021
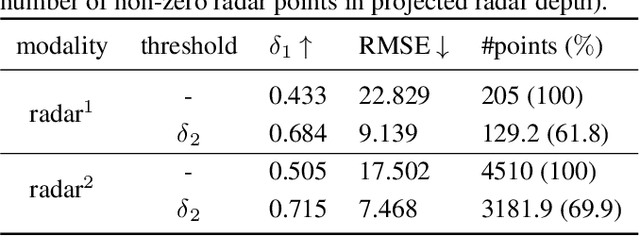
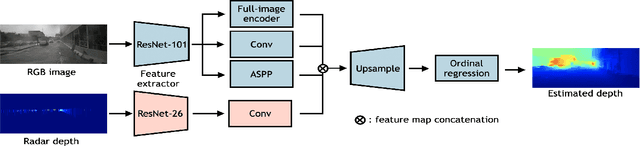
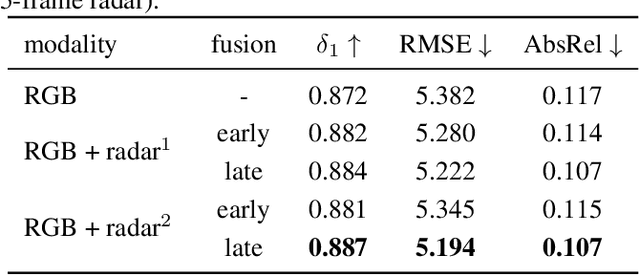
We integrate sparse radar data into a monocular depth estimation model and introduce a novel preprocessing method for reducing the sparseness and limited field of view provided by radar. We explore the intrinsic error of different radar modalities and show our proposed method results in more data points with reduced error. We further propose a novel method for estimating dense depth maps from monocular 2D images and sparse radar measurements using deep learning based on the deep ordinal regression network by Fu et al. Radar data are integrated by first converting the sparse 2D points to a height-extended 3D measurement and then including it into the network using a late fusion approach. Experiments are conducted on the nuScenes dataset. Our experiments demonstrate state-of-the-art performance in both day and night scenes.
Lite Audio-Visual Speech Enhancement
May 24, 2020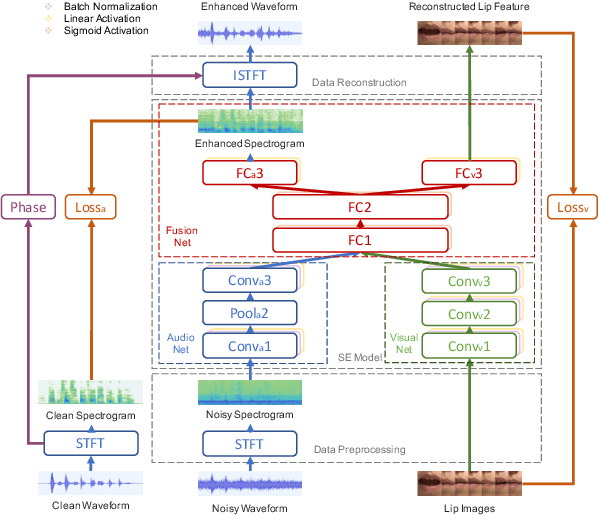
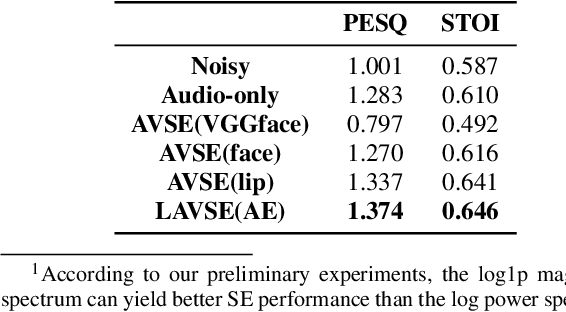
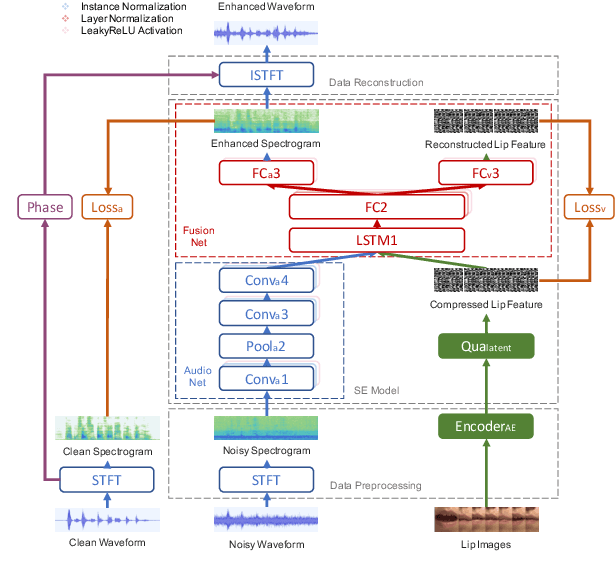
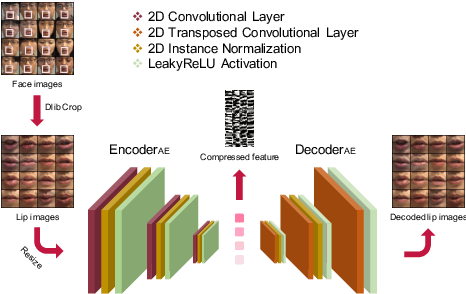
Previous studies have confirmed the effectiveness of incorporating visual information into speech enhancement (SE) systems. Despite improved denoising performance, two problems may be encountered when implementing an audio-visual SE (AVSE) system: (1) additional processing costs are incurred to incorporate visual input and (2) the use of face or lip images may cause privacy problems. In this study, we propose a Lite AVSE (LAVSE) system to address these problems. The system includes two visual data compression techniques and removes the visual feature extraction network from the training model, yielding better online computation efficiency. Our experimental results indicate that the proposed LAVSE system can provide notably better performance than an audio-only SE system with a similar number of model parameters. In addition, the experimental results confirm the effectiveness of the two techniques for visual data compression.
Unsupervised Representation Disentanglement using Cross Domain Features and Adversarial Learning in Variational Autoencoder based Voice Conversion
Feb 07, 2020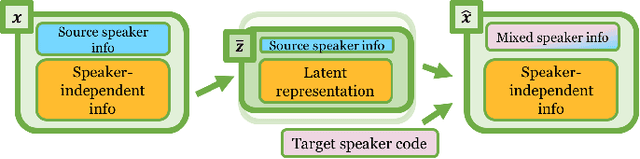
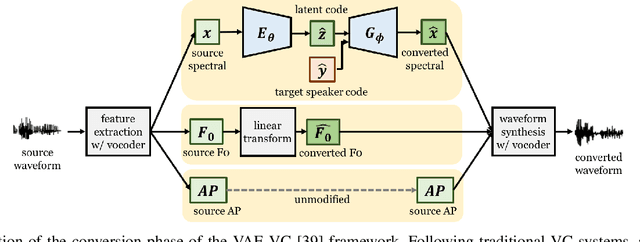
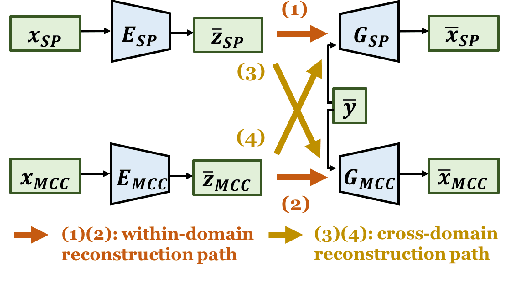

An effective approach for voice conversion (VC) is to disentangle linguistic content from other components in the speech signal. The effectiveness of variational autoencoder (VAE) based VC (VAE-VC), for instance, strongly relies on this principle. In our prior work, we proposed a cross-domain VAE-VC (CDVAE-VC) framework, which utilized acoustic features of different properties, to improve the performance of VAE-VC. We believed that the success came from more disentangled latent representations. In this paper, we extend the CDVAE-VC framework by incorporating the concept of adversarial learning, in order to further increase the degree of disentanglement, thereby improving the quality and similarity of converted speech. More specifically, we first investigate the effectiveness of incorporating the generative adversarial networks (GANs) with CDVAE-VC. Then, we consider the concept of domain adversarial training and add an explicit constraint to the latent representation, realized by a speaker classifier, to explicitly eliminate the speaker information that resides in the latent code. Experimental results confirm that the degree of disentanglement of the learned latent representation can be enhanced by both GANs and the speaker classifier. Meanwhile, subjective evaluation results in terms of quality and similarity scores demonstrate the effectiveness of our proposed methods.
MOSNet: Deep Learning based Objective Assessment for Voice Conversion
Apr 26, 2019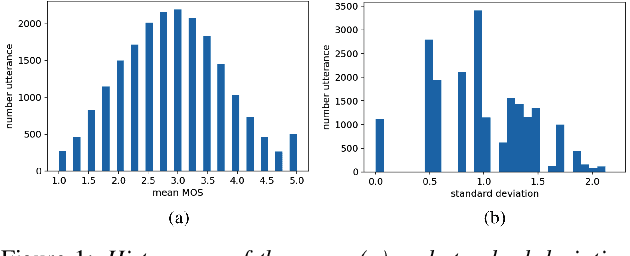
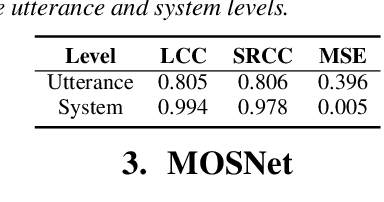
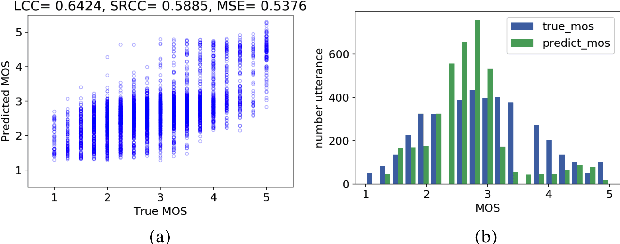
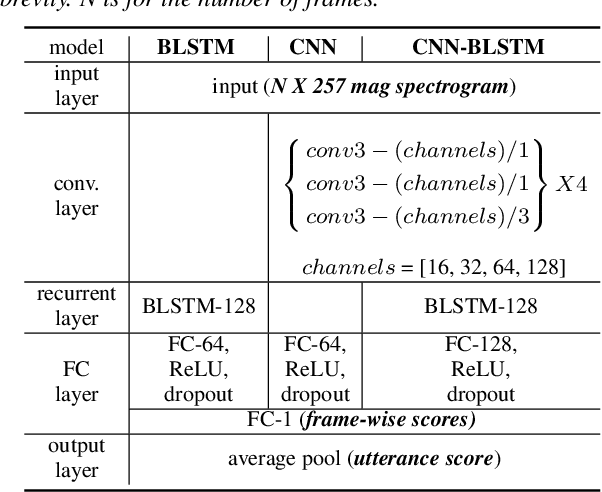
Existing objective evaluation metrics for voice conversion (VC) are not always correlated with human perception. Therefore, training VC models with such criteria may not effectively improve naturalness and similarity of converted speech. In this paper, we propose deep learning-based assessment models to predict human ratings of converted speech. We adopt the convolutional and recurrent neural network models to build a mean opinion score (MOS) predictor, termed as MOSNet. The proposed models are tested on large-scale listening test results of the Voice Conversion Challenge (VCC) 2018. Experimental results show that the predicted scores of the proposed MOSNet are highly correlated with human MOS ratings at the system level while being fairly correlated with human MOS ratings at the utterance level. Meanwhile, we have modified MOSNet to predict the similarity scores, and the preliminary results show that the predicted scores are also fairly correlated with human ratings. These results confirm that the proposed models could be used as a computational evaluator to measure the MOS of VC systems to reduce the need for expensive human rating.