 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Minimal Sampling and Consensus for Prohibitively Large Datasets
Apr 24, 2026We introduce NONSAC (Non-Minimal Sampling and Consensus), a general framework for robust and scalable model estimation from arbitrarily large datasets contaminated with noise and outliers. NONSAC repeatedly samples non-minimal subsets of data and generates model hypotheses using a robust estimator, producing multiple candidate models. The final model is selected based on a predefined scoring rule that evaluates hypothesis quality. Our framework is estimator-agnostic and can be integrated with existing geometric fitting algorithms such as RANSAC to improve both scalability and robustness to outliers. We propose and evaluate various scoring rules for NONSAC on relative camera pose estimation, Perspective-n-Point, and point cloud registration. Furthermore, we showcase the applicability of NONSAC to correspondence-free point cloud registration by hypothesizing all-to-all correspondences.
Instance-Guided Radar Depth Estimation for 3D Object Detection
Jan 27, 2026Accurate depth estimation is fundamental to 3D perception in autonomous driving, supporting tasks such as detection, tracking, and motion planning. However, monocular camera-based 3D detection suffers from depth ambiguity and reduced robustness under challenging conditions. Radar provides complementary advantages such as resilience to poor lighting and adverse weather, but its sparsity and low resolution limit its direct use in detection frameworks. This motivates the need for effective Radar-camera fusion with improved preprocessing and depth estimation strategies. We propose an end-to-end framework that enhances monocular 3D object detection through two key components. First, we introduce InstaRadar, an instance segmentation-guided expansion method that leverages pre-trained segmentation masks to enhance Radar density and semantic alignment, producing a more structured representation. InstaRadar achieves state-of-the-art results in Radar-guided depth estimation, showing its effectiveness in generating high-quality depth features. Second, we integrate the pre-trained RCDPT into the BEVDepth framework as a replacement for its depth module. With InstaRadar-enhanced inputs, the RCDPT integration consistently improves 3D detection performance. Overall, these components yield steady gains over the baseline BEVDepth model, demonstrating the effectiveness of InstaRadar and the advantage of explicit depth supervision in 3D object detection. Although the framework lags behind Radar-camera fusion models that directly extract BEV features, since Radar serves only as guidance rather than an independent feature stream, this limitation highlights potential for improvement. Future work will extend InstaRadar to point cloud-like representations and integrate a dedicated Radar branch with temporal cues for enhanced BEV fusion.
FALCON: Few-Shot Adversarial Learning for Cross-Domain Medical Image Segmentation
Jan 04, 2026Precise delineation of anatomical and pathological structures within 3D medical volumes is crucial for accurate diagnosis, effective surgical planning, and longitudinal disease monitoring. Despite advancements in AI, clinically viable segmentation is often hindered by the scarcity of 3D annotations, patient-specific variability, data privacy concerns, and substantial computational overhead. In this work, we propose FALCON, a cross-domain few-shot segmentation framework that achieves high-precision 3D volume segmentation by processing data as 2D slices. The framework is first meta-trained on natural images to learn-to-learn generalizable segmentation priors, then transferred to the medical domain via adversarial fine-tuning and boundary-aware learning. Task-aware inference, conditioned on support cues, allows FALCON to adapt dynamically to patient-specific anatomical variations across slices. Experiments on four benchmarks demonstrate that FALCON consistently achieves the lowest Hausdorff Distance scores, indicating superior boundary accuracy while maintaining a Dice Similarity Coefficient comparable to the state-of-the-art models. Notably, these results are achieved with significantly less labeled data, no data augmentation, and substantially lower computational overhead.
Surfel-based 3D Registration with Equivariant SE(3) Features
Aug 28, 2025Point cloud registration is crucial for ensuring 3D alignment consistency of multiple local point clouds in 3D reconstruction for remote sensing or digital heritage. While various point cloud-based registration methods exist, both non-learning and learning-based, they ignore point orientations and point uncertainties, making the model susceptible to noisy input and aggressive rotations of the input point cloud like orthogonal transformation; thus, it necessitates extensive training point clouds with transformation augmentations. To address these issues, we propose a novel surfel-based pose learning regression approach. Our method can initialize surfels from Lidar point cloud using virtual perspective camera parameters, and learns explicit $\mathbf{SE(3)}$ equivariant features, including both position and rotation through $\mathbf{SE(3)}$ equivariant convolutional kernels to predict relative transformation between source and target scans. The model comprises an equivariant convolutional encoder, a cross-attention mechanism for similarity computation, a fully-connected decoder, and a non-linear Huber loss. Experimental results on indoor and outdoor datasets demonstrate our model superiority and robust performance on real point-cloud scans compared to state-of-the-art methods.
* 5 pages, 4 figures
BelHouse3D: A Benchmark Dataset for Assessing Occlusion Robustness in 3D Point Cloud Semantic Segmentation
Nov 20, 2024



Large-scale 2D datasets have been instrumental in advancing machine learning; however, progress in 3D vision tasks has been relatively slow. This disparity is largely due to the limited availability of 3D benchmarking datasets. In particular, creating real-world point cloud datasets for indoor scene semantic segmentation presents considerable challenges, including data collection within confined spaces and the costly, often inaccurate process of per-point labeling to generate ground truths. While synthetic datasets address some of these challenges, they often fail to replicate real-world conditions, particularly the occlusions that occur in point clouds collected from real environments. Existing 3D benchmarking datasets typically evaluate deep learning models under the assumption that training and test data are independently and identically distributed (IID), which affects the models' usability for real-world point cloud segmentation. To address these challenges, we introduce the BelHouse3D dataset, a new synthetic point cloud dataset designed for 3D indoor scene semantic segmentation. This dataset is constructed using real-world references from 32 houses in Belgium, ensuring that the synthetic data closely aligns with real-world conditions. Additionally, we include a test set with data occlusion to simulate out-of-distribution (OOD) scenarios, reflecting the occlusions commonly encountered in real-world point clouds. We evaluate popular point-based semantic segmentation methods using our OOD setting and present a benchmark. We believe that BelHouse3D and its OOD setting will advance research in 3D point cloud semantic segmentation for indoor scenes, providing valuable insights for the development of more generalizable models.
Predictive uncertainty estimation in deep learning for lung carcinoma classification in digital pathology under real dataset shifts
Aug 15, 2024Deep learning has shown tremendous progress in a wide range of digital pathology and medical image classification tasks. Its integration into safe clinical decision-making support requires robust and reliable models. However, real-world data comes with diversities that often lie outside the intended source distribution. Moreover, when test samples are dramatically different, clinical decision-making is greatly affected. Quantifying predictive uncertainty in models is crucial for well-calibrated predictions and determining when (or not) to trust a model. Unfortunately, many works have overlooked the importance of predictive uncertainty estimation. This paper evaluates whether predictive uncertainty estimation adds robustness to deep learning-based diagnostic decision-making systems. We investigate the effect of various carcinoma distribution shift scenarios on predictive performance and calibration. We first systematically investigate three popular methods for improving predictive uncertainty: Monte Carlo dropout, deep ensemble, and few-shot learning on lung adenocarcinoma classification as a primary disease in whole slide images. Secondly, we compare the effectiveness of the methods in terms of performance and calibration under clinically relevant distribution shifts such as in-distribution shifts comprising primary disease sub-types and other characterization analysis data; out-of-distribution shifts comprising well-differentiated cases, different organ origin, and imaging modality shifts. While studies on uncertainty estimation exist, to our best knowledge, no rigorous large-scale benchmark compares predictive uncertainty estimation including these dataset shifts for lung carcinoma classification.
PCR-99: A Practical Method for Point Cloud Registration with 99% Outliers
Feb 28, 2024We propose a robust method for point cloud registration that can handle both unknown scales and extreme outlier ratios. Our method, dubbed PCR-99, uses a deterministic 3-point sampling approach with two novel mechanisms that significantly boost the speed: (1) an improved ordering of the samples based on pairwise scale consistency, prioritizing the point correspondences that are more likely to be inliers, and (2) an efficient outlier rejection scheme based on triplet scale consistency, prescreening bad samples and reducing the number of hypotheses to be tested. Our evaluation shows that, up to 98% outlier ratio, the proposed method achieves comparable performance to the state of the art. At 99% outlier ratio, however, it outperforms the state of the art for both known-scale and unknown-scale problems. Especially for the latter, we observe a clear superiority in terms of robustness and speed.
RCDPT: Radar-Camera fusion Dense Prediction Transformer
Nov 04, 2022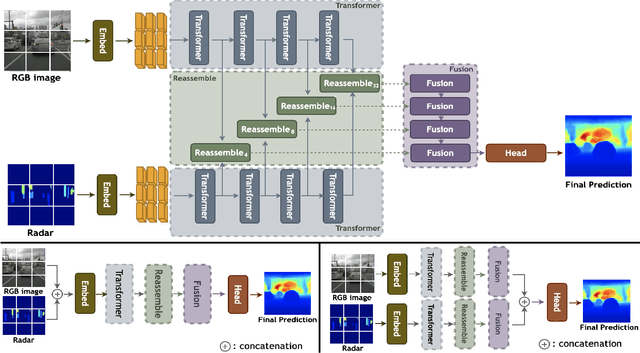
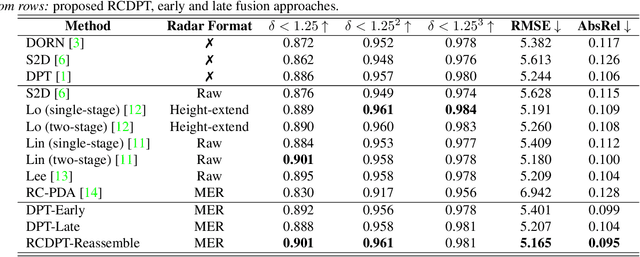

Recently, transformer networks have outperformed traditional deep neural networks in natural language processing and show a large potential in many computer vision tasks compared to convolutional backbones. In the original transformer, readout tokens are used as designated vectors for aggregating information from other tokens. However, the performance of using readout tokens in a vision transformer is limited. Therefore, we propose a novel fusion strategy to integrate radar data into a dense prediction transformer network by reassembling camera representations with radar representations. Instead of using readout tokens, radar representations contribute additional depth information to a monocular depth estimation model and improve performance. We further investigate different fusion approaches that are commonly used for integrating additional modality in a dense prediction transformer network. The experiments are conducted on the nuScenes dataset, which includes camera images, lidar, and radar data. The results show that our proposed method yields better performance than the commonly used fusion strategies and outperforms existing convolutional depth estimation models that fuse camera images and radar.
How much depth information can radar infer and contribute
Feb 26, 2022
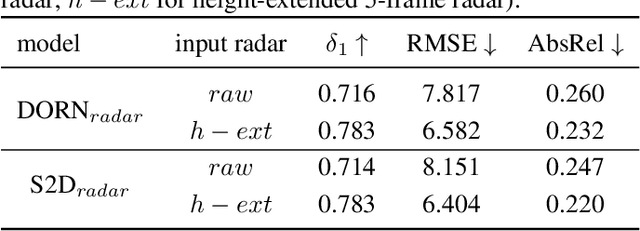

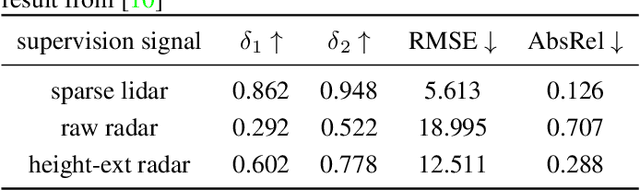
Since the release of radar data in large scale autonomous driving dataset, many works have been proposed fusing radar data as an additional guidance signal into monocular depth estimation models. Although positive performances are reported, it is still hard to tell how much depth information radar can infer and contribute in depth estimation models. In this paper, we conduct two experiments to investigate the intrinsic depth capability of radar data using state-of-the-art depth estimation models. Our experiments demonstrate that the estimated depth from only sparse radar input can detect the shape of surroundings to a certain extent. Furthermore, the monocular depth estimation model supervised by preprocessed radar only during training can achieve 70% performance in delta_1 score compared to the baseline model trained with sparse lidar.
Depth Estimation from Monocular Images and Sparse radar using Deep Ordinal Regression Network
Jul 15, 2021
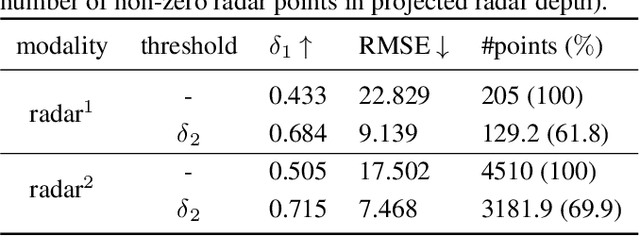
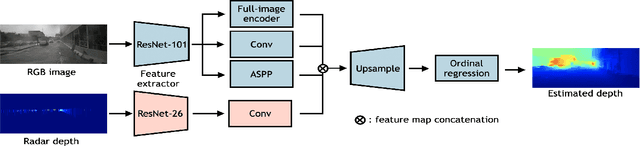
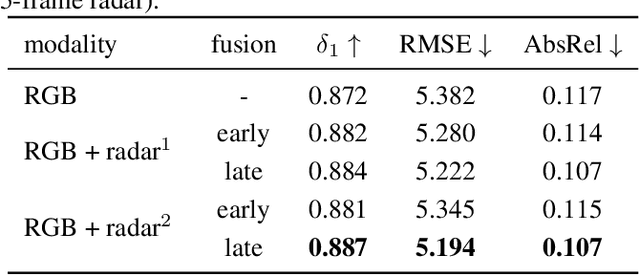
We integrate sparse radar data into a monocular depth estimation model and introduce a novel preprocessing method for reducing the sparseness and limited field of view provided by radar. We explore the intrinsic error of different radar modalities and show our proposed method results in more data points with reduced error. We further propose a novel method for estimating dense depth maps from monocular 2D images and sparse radar measurements using deep learning based on the deep ordinal regression network by Fu et al. Radar data are integrated by first converting the sparse 2D points to a height-extended 3D measurement and then including it into the network using a late fusion approach. Experiments are conducted on the nuScenes dataset. Our experiments demonstrate state-of-the-art performance in both day and night scenes.