 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-tuned Wav2vec 2.0/HuBERT Benchmark For Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding
Nov 04, 2021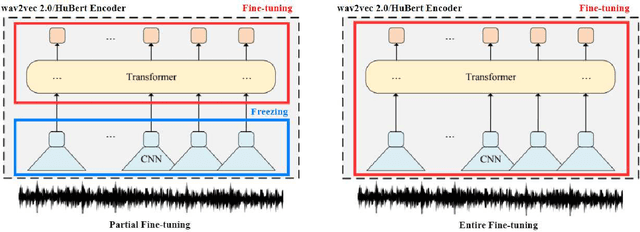
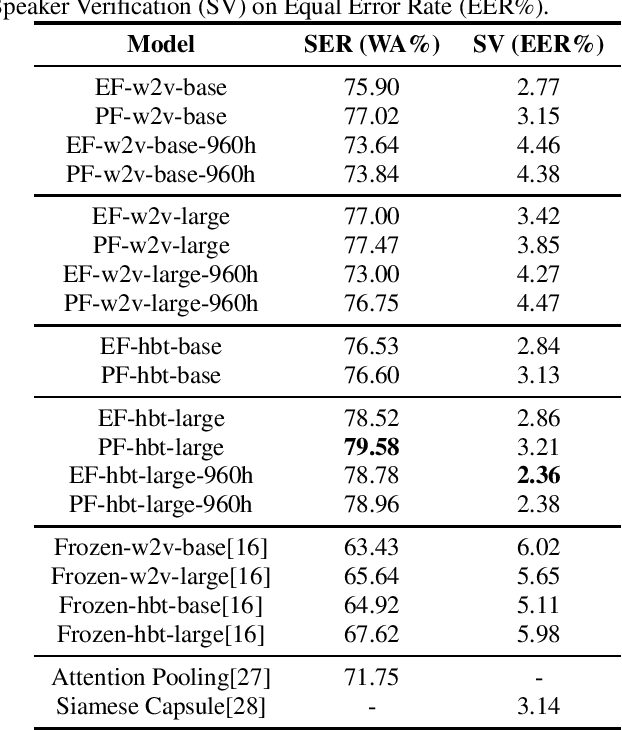
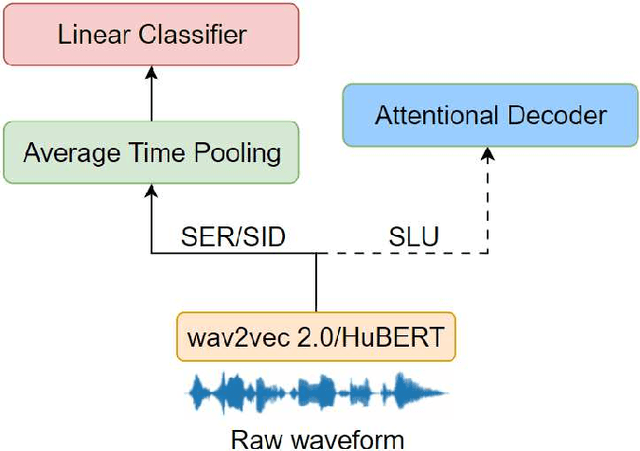
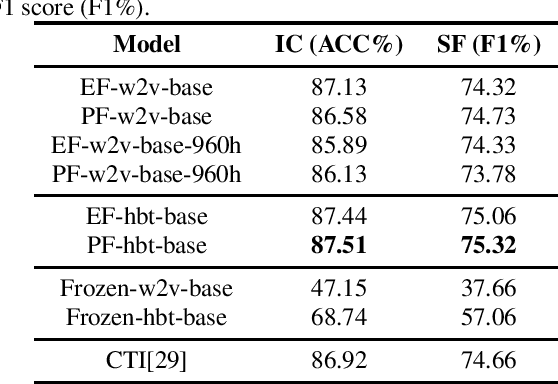
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.
SpeechBrain: A General-Purpose Speech Toolkit
Jun 08, 2021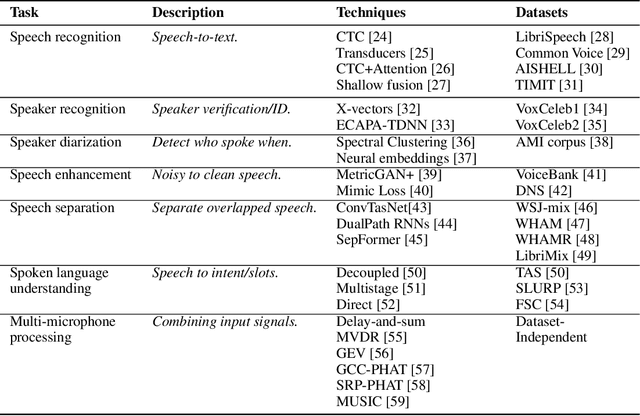
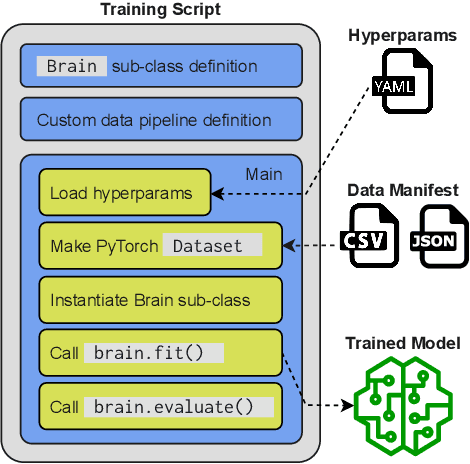

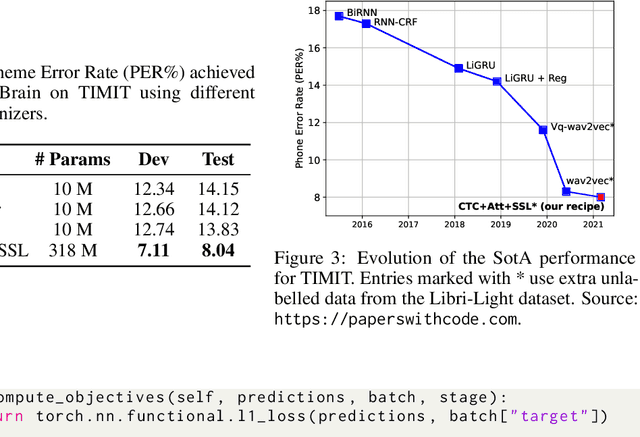
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to facilitate the research and development of neural speech processing technologies by being simple, flexible, user-friendly, and well-documented. This paper describes the core architecture designed to support several tasks of common interest, allowing users to naturally conceive, compare and share novel speech processing pipelines. SpeechBrain achieves competitive or state-of-the-art performance in a wide range of speech benchmarks. It also provides training recipes, pretrained models, and inference scripts for popular speech datasets, as well as tutorials which allow anyone with basic Python proficiency to familiarize themselves with speech technologies.
Timers and Such: A Practical Benchmark for Spoken Language Understanding with Numbers
Apr 04, 2021
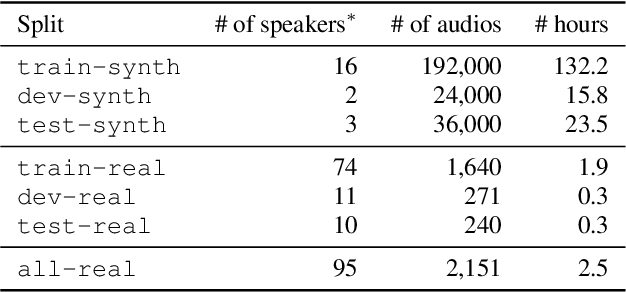
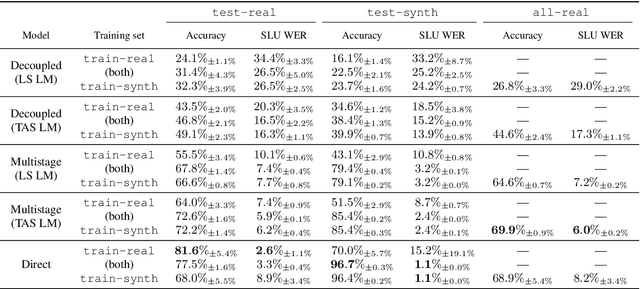
This paper introduces Timers and Such, a new open source dataset of spoken English commands for common voice control use cases involving numbers. We describe the gap in existing spoken language understanding datasets that Timers and Such fills, the design and creation of the dataset, and experiments with a number of ASR-based and end-to-end baseline models, the code for which has been made available as part of the SpeechBrain toolkit.
Twist your logic with TouIST
Jul 14, 2015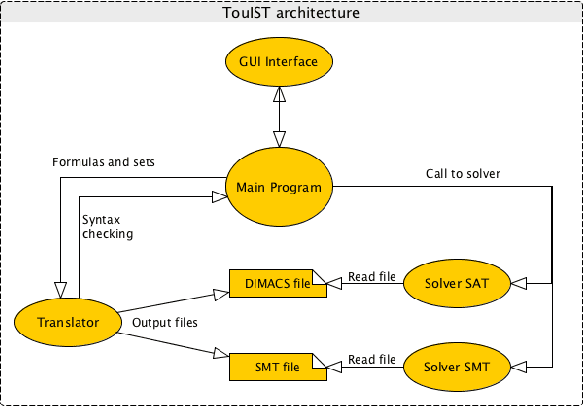
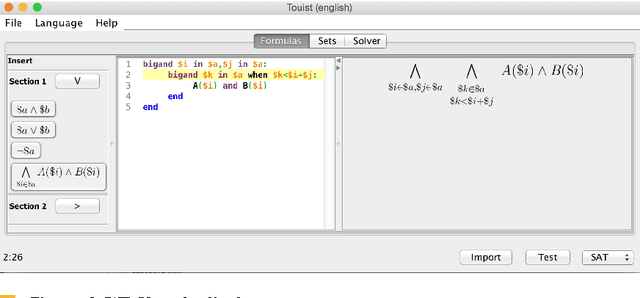
SAT provers are powerful tools for solving real-sized logic problems, but using them requires solid programming knowledge and may be seen w.r.t.\ logic like assembly language w.r.t.\ programming. Something like a high level language was missing to ease various users to take benefit of these tools. {\sc \texttt {TouIST}}\ aims at filling this gap. It is devoted to propositional logic and its main features are 1) to offer a high-level logic langage for expressing succintly complex formulas (e.g.\ formulas describing Sudoku rules, planification problems,\ldots) and 2) to find models to these formulas by using the adequate powerful prover, which the user has no need to know about. It consists in a friendly interface that offers several syntactic facilities and which is connected with some sufficiently powerful provers allowing to automatically solve big instances of difficult problems (such as time-tables or Sudokus). It can interact with various provers: pure SAT solver but also SMT provers (SAT modulo theories - like linear theory of reals, etc) and thus may also be used by beginners for experiencing with pure propositional problems up to graduate students or even researchers for solving planification problems involving big sets of fluents and numerical constraints on them.